【长文详解】指针生成网络:不抄不是好学生!

一:今日吐槽
二:内容预告
有哪些文本摘要的评价指标
什么是指针网络
-
什么是coverage机制
三:文本摘要的评价指标
ROUGE(Recall-Oriented Understudy for Gisting Evaluation),是基于召回率的文本摘要评价指标。
ROUGE-N表示一个候选摘要和多条参考摘要之间,共现N-grams的召回率。
下面是ROUGE-N的计算公式:
这个公式看起来有点小复杂,分母是多条参考摘要中,N-grams出现的总数,而分子是候选摘要中,匹配的N-grams的个数。
为啥说是基于召回率的评价指标呢?
因为分母是参考摘要中N-grams出现的总数,那么评估的是候选摘要对N-grams是否覆盖得够全面。
ROUGE-L,是通过统计匹配的最长公共子序列的个数,来评价摘要质量的。
什么是最长公共子序列呢(Longest Common Subsequence,LCS)?
举个例子。
和N-gram有什么区别?
最长公共子序列和N-gram不同,不要求是连续的,可以由断断续续的共有词语拼成,但是要求共有词语的顺序,在参考摘要和候选摘要中,必须保持一致。
ROUGE-L需要计算Recall和Precision,然后得到类似于F1值的指标:
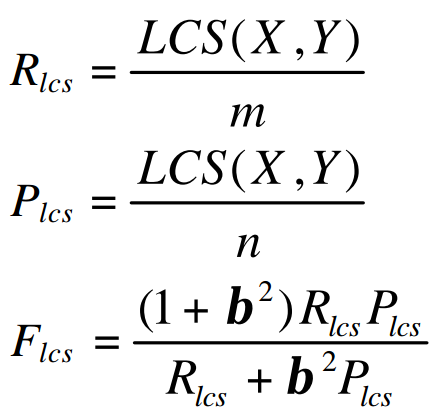
X表示参考摘要,Y表示候选摘要,m、n分别表示二者的长度,LCS(X,Y)表示最长公共子序列的长度。
四:指针生成网络的贡献
指针生成网络这篇论文,首先回顾了抽取式摘要和生成式摘要的优缺点,然后指出,尽管Seq2Seq框架给生成式摘要带来了曙光,但也存在以下三个问题:
-
无法准确地再现文章的事实细节 -
无法解决摘要中的未登录词(OOV)问题 倾向于生成重复的摘要语句
因此论文提出了一种Seq2Seq的改进结构,称为指针生成网络,运用指针网络(Point Network)和Coverage机制(Coverage Mechanism),试图在难度更大的多句摘要任务中,解决上述三个问题。
指针网络可以从原文中复制词语,不仅可以再现原文的重要细节,而且在一定程度上可以解决未登录词的问题。
这与抽取式摘要类似。
同时,指针网络具有生成摘要的能力,可以生成原文中没有的词语。
因此,指针网络与CopyNet有异曲同工之妙,可以视为抽取式摘要和生成式摘要的结合。
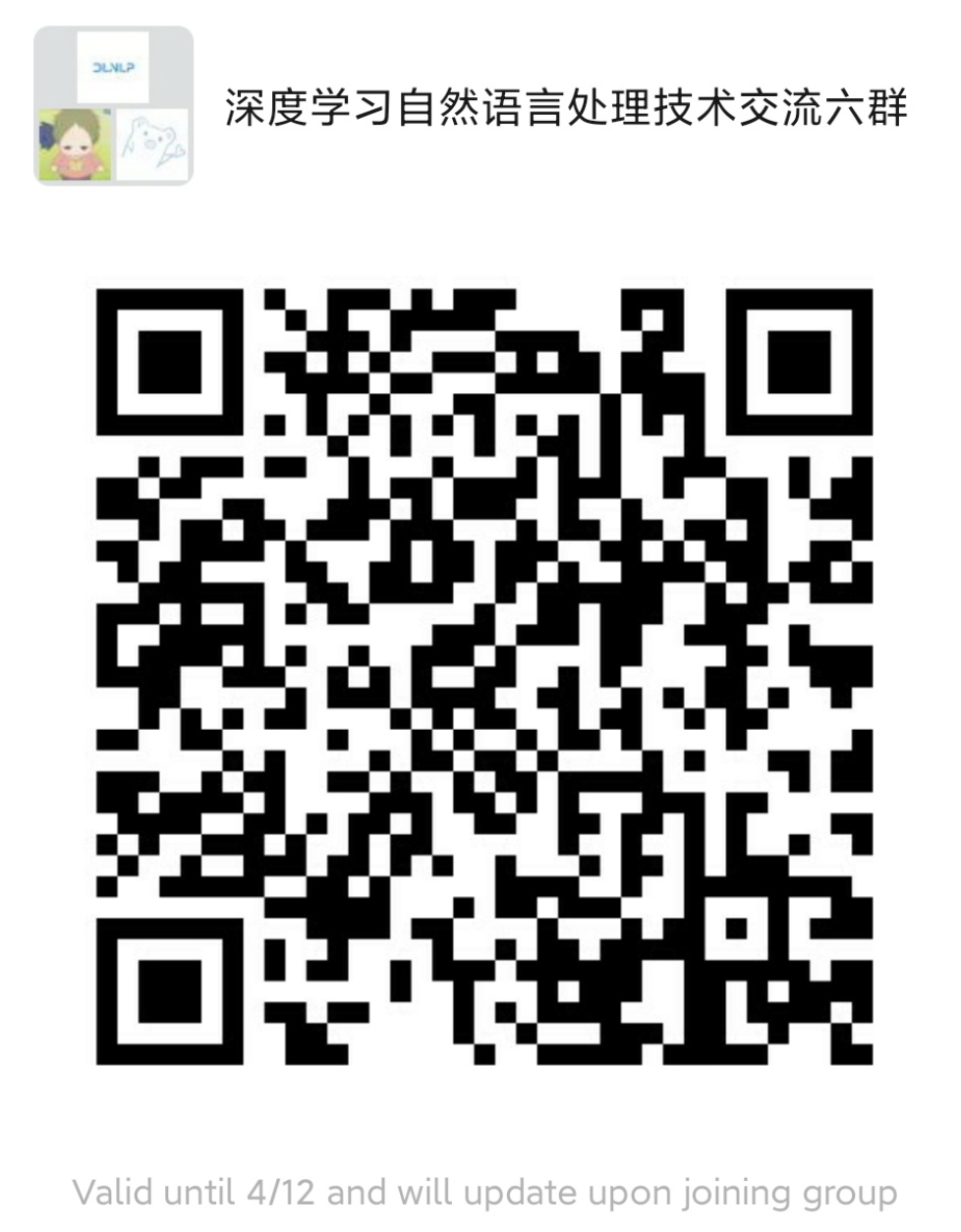
此外,论文运用Coverage机制,对已经出现在摘要中的词语,降低其注意力权重,从而降低其再次被生成的概率,在解决摘要语句重复的问题上,取得了不错的效果。
我们来看指针网络和Coverage机制的效果。
原文如下:

Seq2Seq+Attention:原文中存在事实性错误。而且,原文中存在未登录词 muhammadu buhari,导致摘要中也出现了 UNK 标记。此外,nigeria(尼日利亚)这个词重复出现了很多次。
Pointer-Network:复现了原文中的词语和句子,把原文中的未登录词 muhammadu buhari 复制到摘要中,提升了准确率。但是 in the northeast part of nigeria 这段摘要重复出现了两次。
Pointer-Netword+Coverage:摘要中未出现未登录词和重复的语句,生成的摘要质量比较高。

五:Seq2Seq+Attention
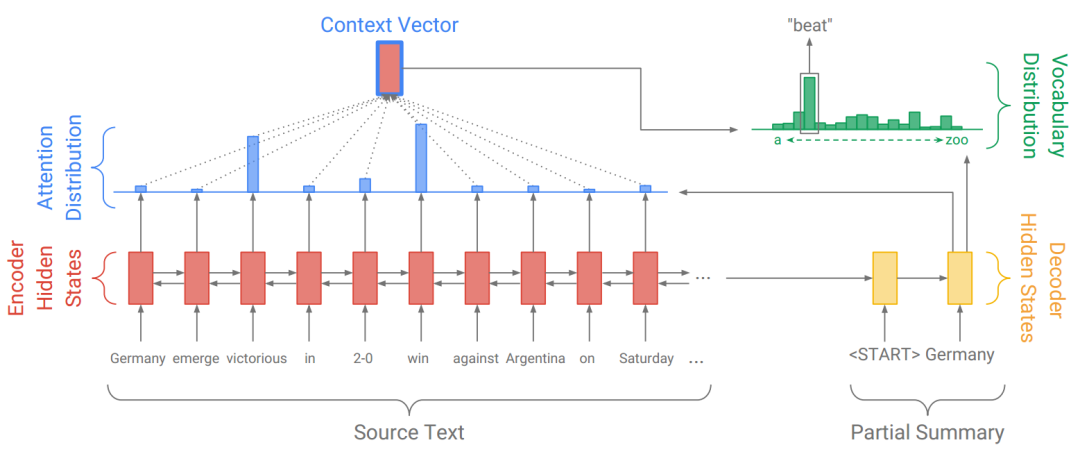
首先是编码阶段,我们把文章序列输入到Encoder(一个双向LSTM)中,得到每个token对应的隐状态(Hidden State)hi(i=1,..,n)。
敲黑板!编码阶段每个token对应的隐状态hi,在接下来的解码过程中,都保持不变。
在解码阶段,我们首先在Decoder中输入一个<START>标记,用于预测第一个词,从第二个词开始,用前一个词来预测下一个词。
用前一个词预测下一个词,在训练阶段和测试阶段的做法不同。
训练阶段是有监督的,有参考摘要,那么前一个词来自于参考摘要,这叫做 Teacher Forcing。
测试阶段是无监督的,那么前一个词来自于Decoder预测的词(Emitted Word)。
那么在解码的第t步,我们输入前一个词,会得到Decoder的隐状态st。
以下代码来自Tensorflow 2.0的机器翻译教程。
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc = tf.keras.layers.Dense(vocab_size)
""" 1: 使用注意力机制 """
self.attention = BahdanauAttention(self.dec_units)
def call(self, x, hidden, enc_output):
""" 2: 用decoder的隐状态和encoder的输出,得到注意力向量和注意力权重 """
context_vector, attention_weights = self.attention(hidden, enc_output)
x = self.embedding(x)
""" 3: decoder的输入与注意力向量拼接,用于计算输出单词的概率分布 """
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
""" 4: 得到decoder的隐状态,用于计算下一步的注意力向量 """
output, state = self.gru(x)
output = tf.reshape(output, (-1, output.shape[2]))
""" 5: 输出的形状(batch-size,vocab)"""
x = self.fc(output)
return x, state, attention_weights有了编码阶段输入序列的隐状态序列(Hidden State)hi(i=1,..,n),以及解码阶段第t步的隐状态st,我们就可以求注意力权重了。
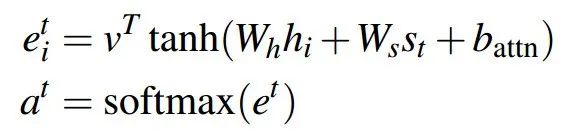
接着以注意力分布为权重,对Encoder的隐状态序列进行加权求和,得到上下文向量:
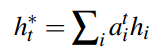
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
hidden_with_time_axis = tf.expand_dims(query, 1)
""" 1: 计算注意力分布,形状 == (批大小,最大长度,1) """
score = self.V(tf.nn.tanh(self.W1(values) + self.W2(hidden_with_time_axis)))
attention_weights = tf.nn.softmax(score, axis=1)
""" 2: 计算上下文向量,形状 == (批大小,隐藏层大小)"""
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights上面Decoder的代码中,是把Decoder的输入和上下文向量拼接,用于计算输出单词的概率分布。
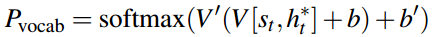
Decoder是一步一步进行预测的,每预测一个词,就计算一个loss,预测完毕后,再把每一步的loss相加,作为总的loss。
比如第t步,参考摘要中的词是:beat,而计算的概率分布中,beat的概率为0.9,那么该步的loss为-log(0.9),是一个很小的数;如果beat的概率为0.09,那么loss非常大。
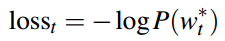
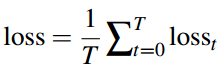
回到上面的例子。
输入:Germany emerge victorious in 2-0 win against Argentina on Saturday.
第二步预测的单词为 beat,是因为对 victorious 和 win 这两个单词给予了更多关注。
六:指针生成网络
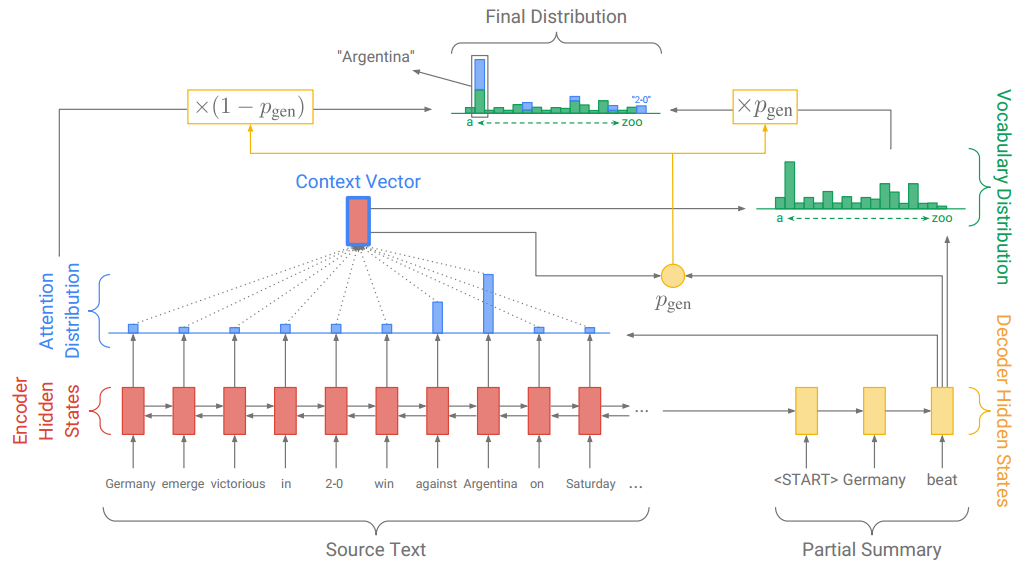
上面的图看着还蛮复杂,还是看公式比较清晰。
首先像Seq2Seq+Attention那样,计算注意力分布、上下文向量和基于原词表的单词概率分布。
这个词表是事先构建好的,不包含输入文本中的OOV词。
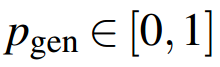
在第t步,这个概率由上下文向量、Decoder的隐状态和Decoder的输入,经过一个sigmoid函数计算而得:
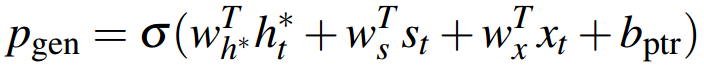
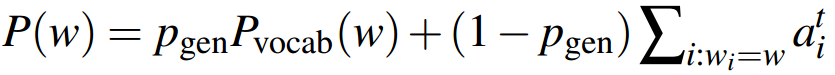
注意,公式左边的Pvocab(w)代表按原词表计算的单词概率分布,而右边的P(w)表示按加入OOV词后的新词表,计算的单词概率分布。
如果预测的单词是 win,而这个单词不在事先构建好的词表中,那么Pvocab(win)为0,而win有一个注意力权重,乘上(1- Pgen),作为该单词的概率。
于是从原文中复制win到摘要中。
而如果预测的词是beat,这个单词在事先构建好的词表中,而不在原文中,那么beat没有注意力权重,只有按原词表计算的概率。
于是按原词表生成beat到摘要中。
这样就解决了OOV问题。
最后再用P(w)计算loss。
用 Tensorflow 2.0 实现 Pointer 的代码如下:
class Pointer(tf.keras.layers.Layer):
def __init__(self):
super(Pointer, self).__init__()
self.w_s_reduce = tf.keras.layers.Dense(1)
self.w_i_reduce = tf.keras.layers.Dense(1)
self.w_c_reduce = tf.keras.layers.Dense(1)
def __call__(self, context_vector, dec_hidden, dec_inp):
dec_inp = tf.squeeze(dec_inp, axis=1)
""" 用上下文向量、Decoder的隐状态和输入,计算选择概率 """
return tf.nn.sigmoid(self.w_s_reduce(dec_hidden) + self.w_c_reduce(context_vector) + self.w_i_reduce(dec_inp))如果加入Coverage机制来减少摘要重复的问题,那么需要对Attention和loss进行修改。
(一)修正Attention
首先在解码的第t步,计算一个coverage向量ct,这个向量是由前t-1步的注意力分布求和而成。
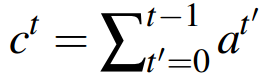
这意味着,我们需要保存每一步计算的注意力分布,用于累加而得coverage向量。
这个coverage向量表示到第t-1步为止,原文中每个单词所受到的关注程度。
很显然,如果某个单词在前t-1步受到的关注太多,那么在第t步,注意力机制就应该给予其他单词更多关注。
于是,把这个coverage向量加入到注意力分布的计算中:
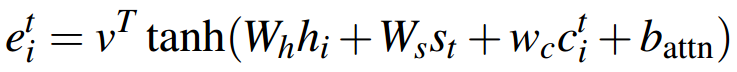
(二)修正loss
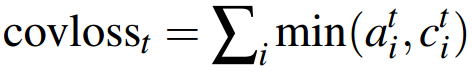
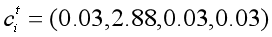
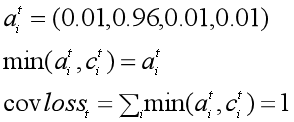
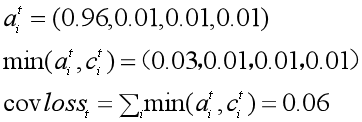
把 coverage loss 加入到原先的loss函数中,就得到了每一步的loss。
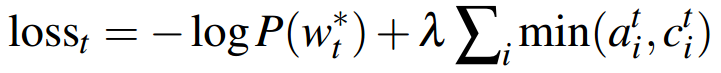
从上面的介绍来看,指针生成网络并不复杂,就是加了指针网络,修正了Attention,加了coverage loss,但是落实到代码,却巨复杂!
每输入一段文本,都需要计算OOV词表,从而得到拓展的词表。
需要计算基于原词表的概率分布和基于原文的注意力分布,得到最终的概率分布。
需要加入coverage loss,得到最终的loss。
关于实验细节,论文写得非常详细,我只选取部分重要的细节。
数据集为CNN/DailyMail。
作者选取的优化器为Adagrad,batch size 为16,学习率为0.15,进行梯度截断的最大梯度为2,没有做学习率衰减。
在测试集上,使用 beam search 进行解码。
作者把训练分成了两个阶段,第一阶段不加入 coverage loss,训练60万步,第二阶段加入 coverage loss,再训练3000步。
作者发现不加 coverage loss,以及在一开始就加入coverage loss,效果都不理想。
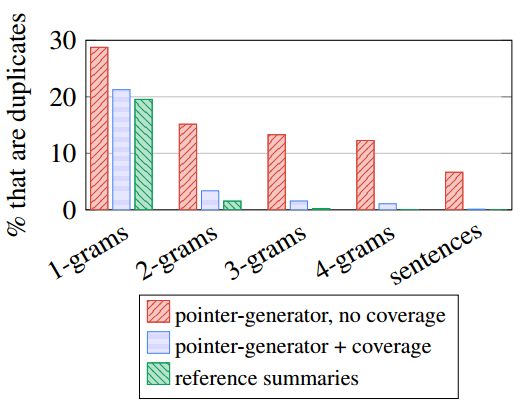
以ROUGE F1为评价指标,指针生成网络以较大的优势,超过了其他生成式摘要模型。