【泡泡图灵智库】解释PointNet:PointNet网络内部到底学习到了什么?
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Explaining the PointNet: What Has Been Learned Inside the PointNet?
作者:Binbin Zhang, Shikun Huang, Wen Shen, Zhihua Wei
来源:CVPR 2019 Workshop
编译:黄文超
审核:万应才
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是 —— Explaining the PointNet: What Has Been Learned Inside the PointNet?
该文章发表于CVPR 2019 Workshop。
在这项工作中,作者专注于解释第一个直接处理3D点云的深度学习框架:PointNet。根据PointNet的性质提出了两个问题并给出了解决方案。首先,将激活函数可视化,以考察全局特征如何表示不同的类的问题;然后,作者提出PointNet的衍生版本并命名为C-PointNet,生成细致的类别响应特征图,以探讨PointNet是基于点云中的何种信息做出决策的。ModelNet40上的实验证明了本文中的工作能够帮助研究人员更好地理解PointNet。
主要贡献
本文的主要贡献为针对 PointNet 提出了两个问题,并给出了相应的答案:
PointNet 提取的全局特征如何表征不同的类别?
PointNet是基于点云中的何种信息做出的分类决策?
算法流程
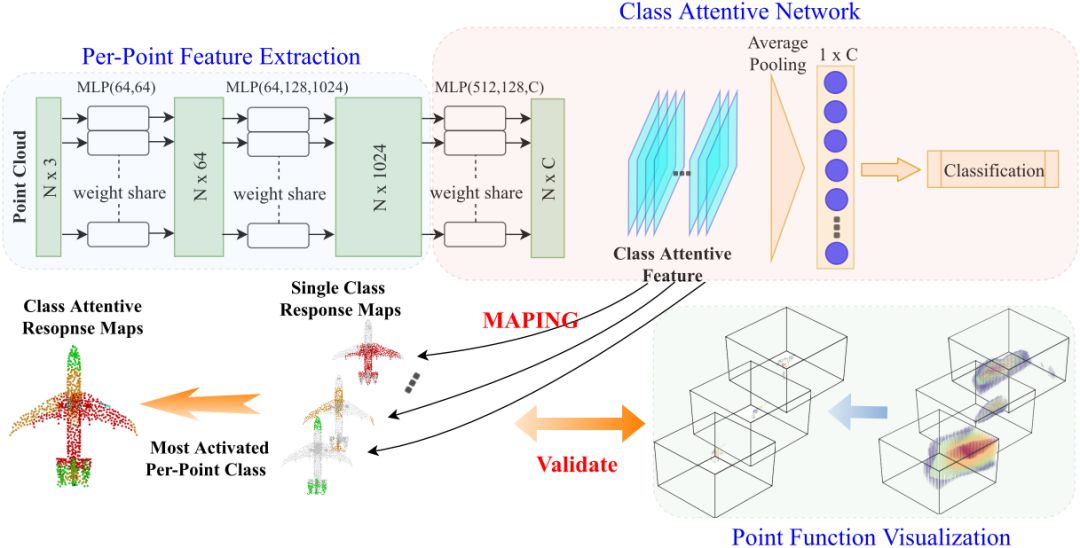
图1 解释 PointNet 的过程
根据 Visual interpretability for deep learning: a survey 一文中的定义,深度学习的可解释性可以大致分为五个研究方向:可视化 CNN 表示,诊断 CNN 表示,解耦 CNN 表示,构建可解释的模型和语义级别的 middle-to-end 学习。其中可视化CNN 表示是最直接的方式,本文也是基于此种方法进行研究。在 PointNet 原文中,作者使用了 t-SNE 聚类的方法来将特征嵌入到低维空间并且可视化样本的相关性。但是本文是第一个同时可视化了 PointNet 的特征表示并且理解了 PointNet的决策方式的工作。
解释PointNet的过程如图1所示,首先,可视化点的函数,随后使用C-PointNet来提取细致的类别全局特征(包含逐点特征提取和类别特征提取)。最后计算类别相关的特征响应来探索决策过程。
对于上述的第一个问题,可以从两个方面考虑:全局特征中每个维度都学习到了什么;全局特征中每个维度的重要性如何。给定无序点云集合{x1, x2, ..., xn},PointNet 可以定义为一个集合的函数 f,将一个集合映射为一个向量,如下式所示,其中 r 和 h 是多层感知机 MLP 网络:
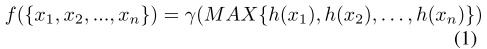
为了分析全局特征中的每个维度,可以可视化每个点的函数h。与 PointNet 原文中直接可视化所有位置的点不同的是,作者只显示特定的更加直观反映点云的特殊性的点。对于每个点函数 h,设定一个阈值 T,只有当 h(x) > T 时点 x 才会被显示。
对于第二个问题,作者修改了 PointNet 的结构,以提取包含类别信息的全局特征,并且生成相应的特征响应图。C-PointNet保持了逐点的特征提取过程,但是不使用最大池化层,修改为一个 MLP 网络,用于将每个点的高维特征降低为类别数的维度,随后进行全局平均池化输出。这样的输出结果中的每个维度可以认为是被关联到了一个特定的类别。生成类别特征响应图的过程可以概括如下:首先提取每个点的类别特征fcls(维度为nxK,n为点数,K为类别数),基于fcls计算特征响应图R(P),其中Ri为映射函数,其将特征值分配到原始的点集中:
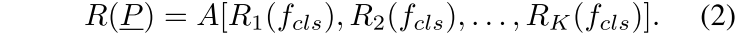
实验结果
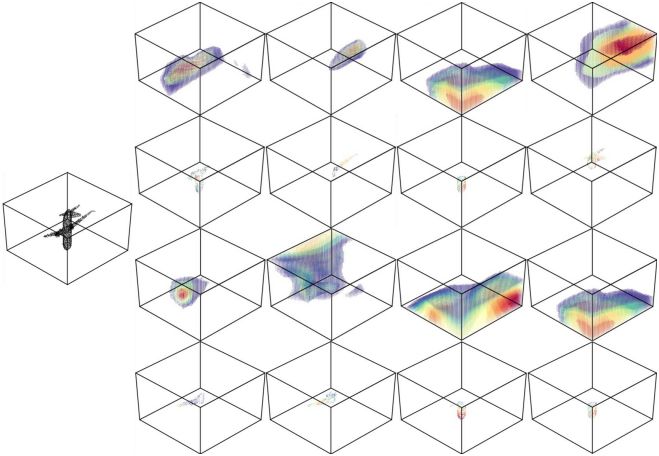
图2 点函数可视化。第一行和第三行是点函数的可视化,
第二行和第四行是点云及其激活值
从图 2 可以看出每个点函数可以检测一定范围内的点,并且有不同的激活值。以飞机为例,不同的点函数可以对机翼、机头、机尾等产生响应。另一个发现是各个点函数的激活区域有很大的重叠,这样的好处是当其中一个函数未成功检测时,其他的函数仍可以检测到重要的部分。但是这样也造成了太多冗余的信息,也会损害网络的可解释性。
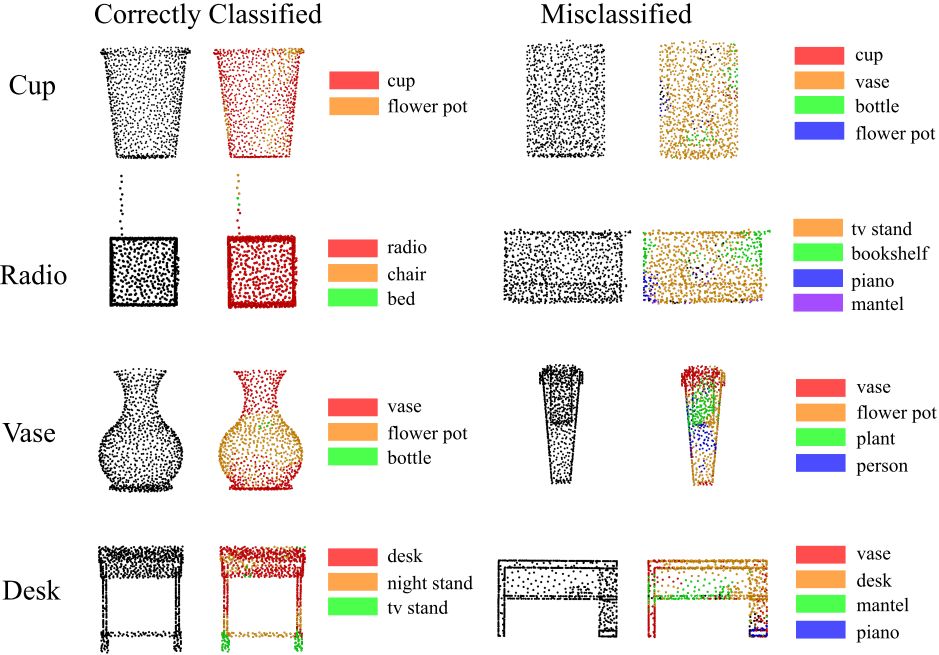
图3 类别特征响应图。原始的点云为黑色,而对不同类别有贡献的点标注为对应的颜色
本文提出的 C-PointNet 可以在达到与 PointNet 对等的分类精度下(88.0%)探索网络决策的过程。如图 3 所示,正确分类的点云中的大部分点都对预测标签有贡献,但是被错误分类的点云中的点可能对其他标签有贡献。图 4 进一步展示了当一对点云具有相似的形状时,其类别特征响应图也可能很相似,这意味着这两类点云很容易被错误分类。
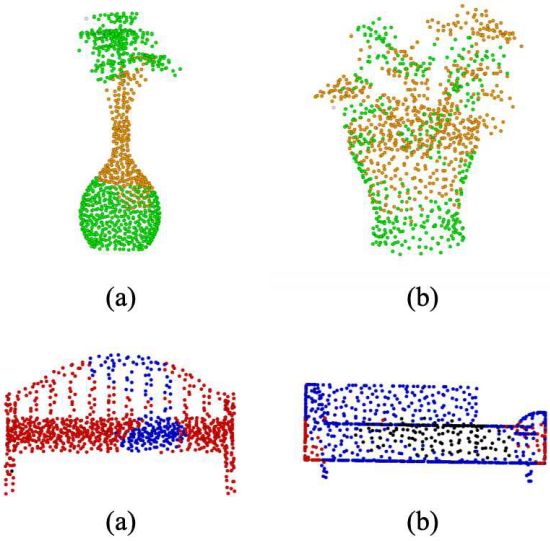
图4 容易被错分的点云示例。
(a)花瓶,(b)花盆,(c)长椅,(d)沙发
(注:论文中给出的图片有误,底部两张图应为(c)、(d))

Abstract
In this work, we focus on explaining the PointNet [4], the first deep learning framework to directly handle 3D point clouds. We raise two issues based on the nature of PointNet and give solutions. First, we visualize the activation of point functions to examine the issue how global features represent different classes? Then, we propose a derivative of PointNet, named C-PointNet, to generate the class-attentive responce maps to explore that based on what information in the point cloud is the PointNet making a decision? The experiments on ModelNet40 demonstrate the efficacy of our work for getting better understanding of PointNet.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




