来谈谈那些很棒的检索式Chatbots论文(二)
作者:LeonMao
本文为授权转载,转载请联系作者,原文链接,可点击阅读原文直达:
https://zhuanlan.zhihu.com/p/65143297
上一篇文章写到了SMN模型,如果有兴趣的话大家可以看看,先放上链接~
今天和大家分享的是百度在2018年ACL上的一篇论文,同样是检索式对话系统领域上一篇很棒论文,下面就开始进入主题吧~
DAM(Deep Attention Matching Network)
18年一件很火的事件就是bert的出现,其中bert的结构用的是Transformer的Encoder层,而Transformer同样出自于一篇很出名的论文:Attention is all you need,为什么要提到这个,因为DAM就是用到Transformer的部件去实现的,如果大家对Transformer不太熟悉,强烈建议看看这个博客(这个博客写得真的好,可视化的教学,真心安利一波),熟悉了Transformer之后再看DAM会快许多~
DAM的论文全称为:Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network ,首先放出该论文及其源码:

除此之外,大家可以去2018ACL的官网找下,里面有作者分享这篇论文的视频~看完论文后有一种很纯粹的感觉,因为论文用了纯注意力机制去做检索式的Chatbots
Introduction
文章的灵感来自于Transformer,它把Transformer里面的注意力机制运用到模型之中。文章中谈到,捕获response和utterances之间不同粒度的匹配信息是检索式多轮对话的关键,但是在这之前的模型,只考虑了表面的文本关联性(surface text relevance),而且之前的模型用RNN去抽取特征。
而文章中用Transformer的部件替代RNN,去抽取文本的更多层次,更多粒度的信息,从而得到response和utterances之间潜在的语义上的关联。那具体怎么做呢?文章将Transformer里的注意力机制拓展成两种方式:
self-attention
cross-attention
在这里默认大家熟悉Transformer结构,self-attention其实就是Transformer的Encoder层(没有用Multi-Head),其中 


而cross-attention结构上还是Transformer的Encoder层,只不过输入不一样了。其中
Model Overview
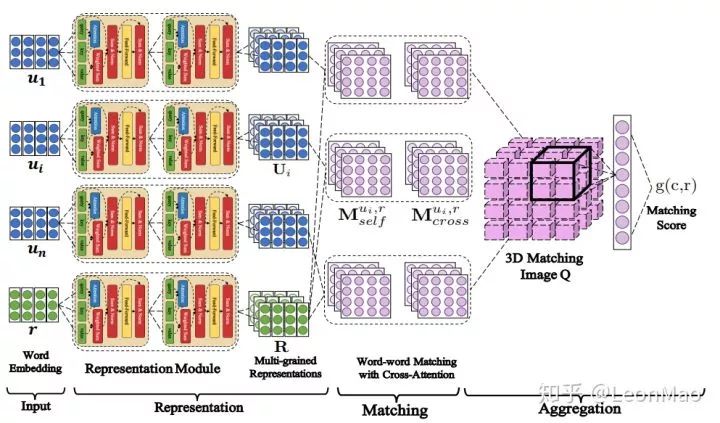
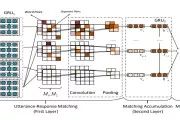
上图就是DAM的模型结构,第一次看这个图感觉好好看,我记得在dstc7的Workshop里,有篇论文的图也好好看,emmm,貌似偏题了。说回正题,模型结构如图所示。
首先response和context中每个utterance通过self-attention层获得不同的表示,拿结构图来说,堆叠了两层self-attention层,即每句话都有两种不同粒度的表示,加上一开始的word embedding表示,每句话一共有三种表示。接着和SMN模型的框架相似,response和每个utterance做匹配,形成2D的匹配矩阵。
而匹配矩阵有两种,分别是 

紧接着就是将得到的所有矩阵进行组合,然后进行3d卷积和池化操作,在连接线性层得到一个最终的匹配分数,以上就是整个DAM模型的大致流程。
模型可以划分为Representation、Matching、Aggregation这三个部分,接下来将按该顺序详细讲述模型的公式,因为attention层在模型中有着举足轻重的地位,也为了在讲述Representation、Matching的时候更清晰,首先具体介绍下attention层。
Attentive Module
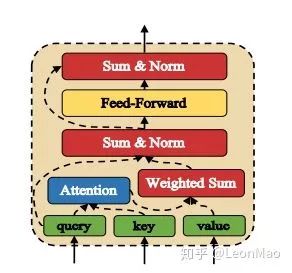
这就是self-attention层和cross-attention层的真面目了~是的,在前面我也说过,self-attention层和cross-attention层的结构都是相同的,只是输入不一样。将图中的query、key、value用




接下来的话就和Transformer的Encoder很像了,首先就是做Scaled Dot-Product Attention(图中蓝色的Attention),然后做Weighted Sum操作,具体公式如下:


接着就是图中的Sum&Norm操作,Sum就是将 

然后将 

在这里,我将feed-forward层的输出表示为 

至此,就能得到最后的输出,有了以上Attentive Module的介绍,以后将会用:
Representation
首先,将response和utterances分别用 



其中 


最后每个句子(response和utterances)都会获得L+1种表示,即

Utterance-Response Matching
得到

而 





Aggregation
在得到



聚合成3D匹配图像后,文章中采用了两次的3D卷积和最大池化去提取特征,在实际试验中,第一次3D卷积的输入通道数为
通过卷积和池化提取到特征后(用 

到此为止,已经将整个模型的具体公式介绍完毕了,整个模型的结构和流程也可以通过公式去慢慢了解。
后续会补充下论文的实验和对模型的相关分析~





