《十年》歌词怎么重配?-试试SongNet!

作者:Piji Li、Haisong Zhang、Xiaojiang Liu、Shuming Shi
机构:Tencent AI Lab
收录会议:ACL 2020
论文地址:https://www.aminer.cn/pub/5e9d72b391e0117173ad2b50
论文代码:https://github.com/lipiji/SongNet
摘要
基于神经网络的文本生成在各种任务中取得了巨大的进展。这些文本生成任务如对话生成、故事生成、摘要生成等可以自由生成文本而不受特定格式的限制。然而,对于歌词(假设乐谱已给定)、宋词、十四行诗等这些独特的文体,有着严格的格式、韵律等要求。这类文本有以下 3 个典型特征:(1)必须完全遵循预定义的格式。(2)必须遵循对应的押韵规则。(3)在满足上述要求下还必须确保句子的完整性。对于这类给定固定模板,严格要求按照限制格式进行文本生成任务研究较少。为此,本文提出 SongNet 模型以解决此类遵循固定格式的文本生成问题。SongNet 是一个基于 Transformer 的自回归语言模型,通过定制化设计一系列符号提高模型在格式、押韵和句子完整性方面的性能。另外,SongNet 改进了注意机制,以促使模型能够捕获格式的上下文信息。本文在 SongNet 基础上提出一个预训练和微调框架,以进一步提高生成质量。最后,在两个收集的语料库(中文和英文)上进行实验,实验结果表明 SongNet 在自动评测标准上和人工评估方面优于其他模型。
此外,SongNet 已在“唱作俱佳”的腾讯 AI 数字人艾灵的歌词生成方案中得到应用。例如,给定《十年》这首歌词的格式,可以通过 SongNet 重新进行配词,并保证格式不变,可以根据原来的曲谱进行演唱:
原歌词:十年之前/我不认识你/你不属于我/我们还是一样/陪在一个陌生人左右/走过渐渐熟悉的街头
新配词:夜深人静/思念你模样/多少次孤单/想伴在你身旁/是什么让我如此幻想/为何会对你那般痴狂
更多关于腾讯 AI 艾灵戳这里->腾讯 AI 艾灵领唱中国新儿歌(https://mp.weixin.qq.com/s?__biz=MzIzOTg4MjEwNw%3D%3D&chksm=e92219cbde5590ddc2a5c4242bdedb14c251555d79cd6945882dd1fcf1aace12dfefe4c47ae1&idx=1&mid=2247484383&scene=21&sn=59257c51daba61da9dfd9f1660babcc6)。顺便安利下 AI 艾灵的 B 站直播间https://live.bilibili.com/21927742。
文归正传,下面介绍 SongNet 的具体实现。
问题定义
输入:一个模板,即一个预定义的格式要求。比如:
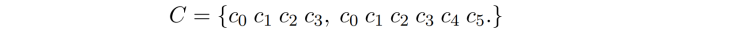
输出:将替换成真实的文字,生成符合模板格式的完整句子。比如:
Y = love is not love;
bends with the remover to remove:
```
模型框架
SongNet 的模型框架如 Figure 2 所示:
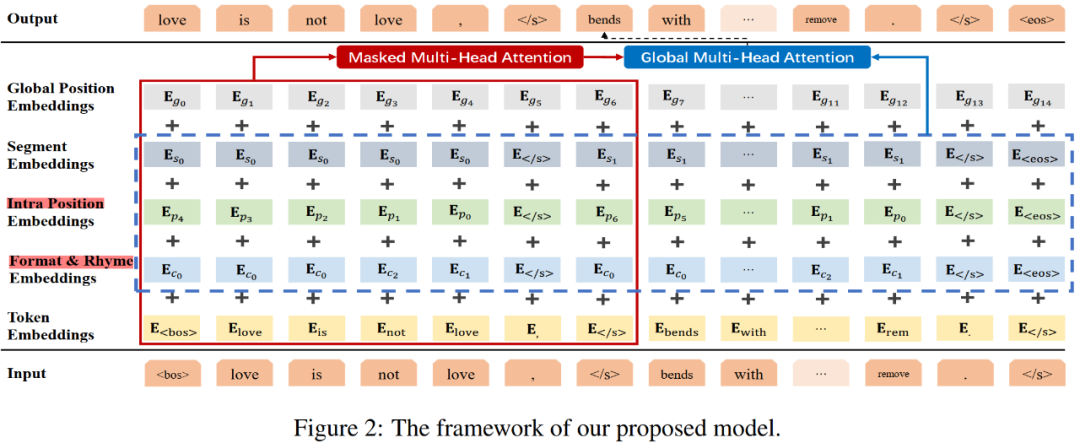
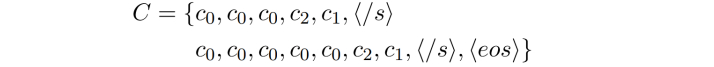
内部位置符号:
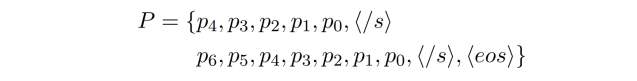
$p_i$表示字符在同一子句或句子中的局部位置。需要注意的是,这里的位置符号索引按降序排列。
其目的是通过推动这些符号捕捉句子的动态信息,特别是精确地捕捉句子的结束位置,从而提高句子的完整性。这是学习句子如何渐进结束的,那么当遇到逗号的时候,模型能够意识到句子生成动态到了尾声。例如$p_0$通常表示标点符号,因此$p_1$表示句子的结尾词。此外,句子内部位置信息还能捕捉诸如对联一类文本的前后句对仗位置特征。
句子符号:
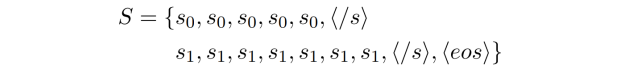
训练的时候,所有的符号以及文本字符向量后统一输入到基于 Transformer 的语言模型中。与 BERT 和 GPT2.0 不同的是,SongNet 稍微修改了传统的注意力机制以适应本文所提出的问题。具体来说,首先通过对所有输入 token 和符号的 embedding 进行求和来获得输入的表征,如 Figure 2 中的红色实线框所示。
为了让模型在自回归的这个动态过程中能够看到模板的后续信息,进而获得序列的全局动态信息。例如,模型可能想知道是否应该通过生成最后一个单词和一个结束句子的标点符号来结束解码过程。为了表示全局动态信息,本文还引入了另一个变量$\mathbf{F}^{0}$,该变量只融合了之前定义的符号信息,没有输入的文本信息从而避免右侧信息泄露,具体如 Figure 2 中蓝色虚线框所示。
对输入进行上述处理后,引入两组注意机制进行特征学习。第一个模块是一个带 masking 的多头自注意力,第二个模块是全局多头注意力。
Masking Multi-Head Self-Attention:
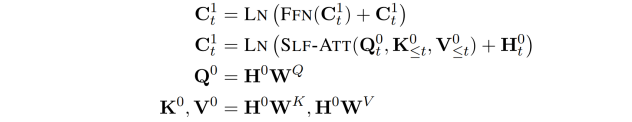
Global Multi-Head Attention:
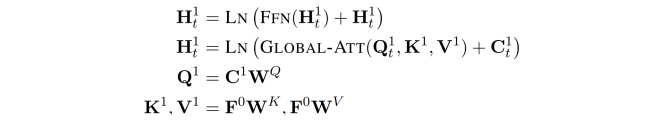
预训练和微调
虽然可以直接拿 SongNet 在目标语料库的训练数据集上进行训练,但通常语料库的规模有限,例如,在莎士比亚的十四行诗语料库中只有大约 150 个样本。因此,本文还设计了一个预训练和微调框架,以进一步提高生成质量。
在生成任务中,会遇到给定部分文本,补全其他文本的需求。例如,在模板中,给定部分句子,要求补全其他句子;在句子中,给定部分词,要求补全其他词。为了使得模型能够应对这类需求,在 SongNet 的预训练阶段,设计了 masking 策略:模板中保留部分词,模型学习预测其他的词。具体来说,在原始文本中随机选取 20% 字符保持不变,而其他字符被遮蔽掉,从而创建一个模板。例子如下:
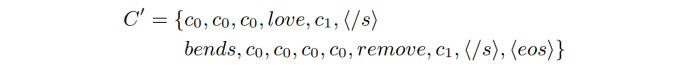
其中“love”、“bends”和“remove”在模板$C^{\prime}$中保持不变。预训练结束后,可以直接对目标语料库进行微调,而不需要调整任何模型结构。
在生成阶段可以指定任何格式和押韵符号(该模板记为$C$)来控制生成。SongNet 模型从特殊token `<bos>`处开始迭代生成,直到遇到结束token `<eos>`。另外,用了 top-k sampling 的解码方法来生成多样性好的结果,通过调节超参k可以平衡多样性和生成质量。
实验
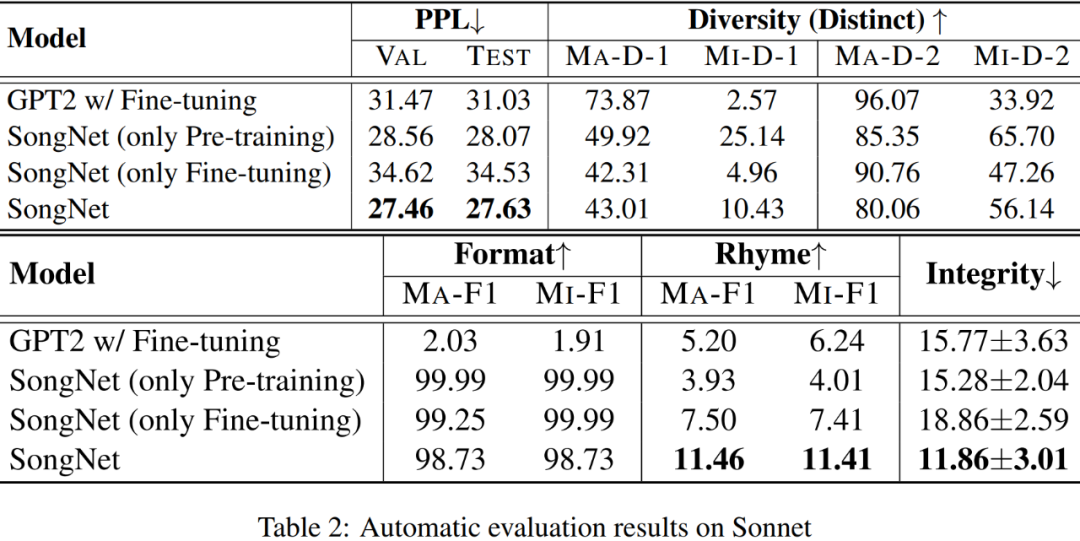
实验评测过程采用中英数据集各一套。中文以宋词生成作为预测目标;英文则是生成莎士比亚十四行诗(sonnet)。模型分预训练和微调两个阶段。在预训练阶段,中文语料主要是新闻和维基百科,英文语料是维基百科和 BooksCorpus。
评测指标
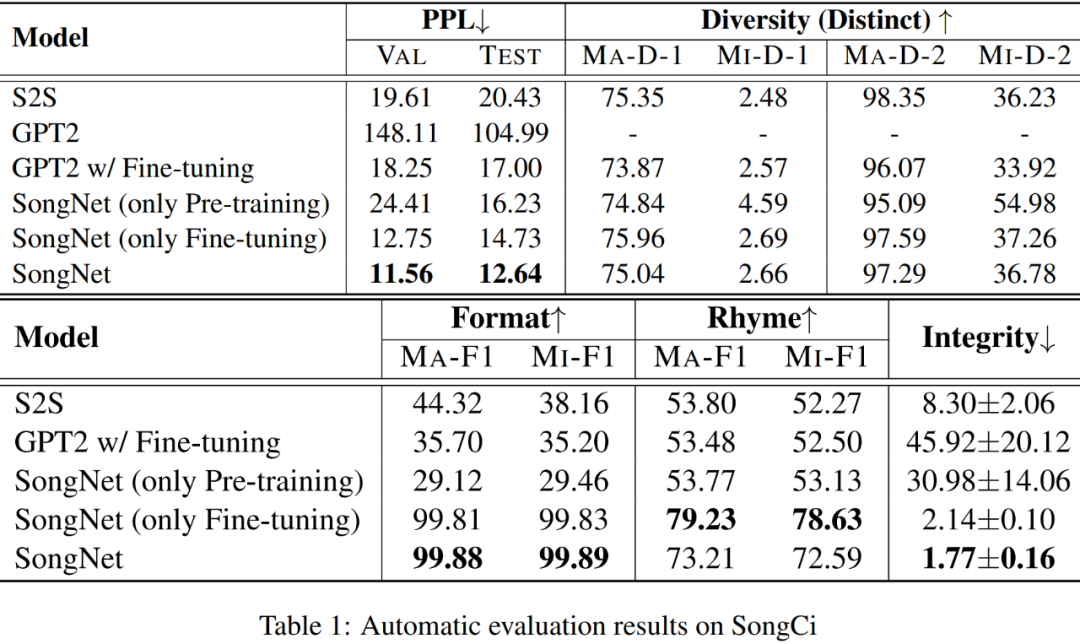
除了常用的文本生成评测指标 PPL、Distinct 外,本文还专门设计了衡量格式(Format)准确率、韵律(Rhyme)准确率和句子完整性(integrity)的指标。
格式准确率:主要是看生成结果与模板之间的长度是否相同,标点符号的位置是否一致,分别有对应的 Precision p、Recall r 和 F1 得分。在实验结果中同时给出了 Macro-F1 和 Micro-F1 的得分。
韵律准确率:
由于在一首宋词的韵脚只有一个,比如宋词:
```
驿外断桥边,寂寞开无主(zhu)。已是黄昏独自愁,更著风和雨(yu)。
无意苦争春,一任群芳妒(du)。零落成泥碾作尘,只有香如故(gu)
```
其中韵脚“zhu”,“yu”,“du”和“gu”。所以对于生成的宋词,先使用开源的 pinyin 工具包获得词在押韵位置上的拼音,再进行评估。在莎士比亚的十四行诗语料库中,押韵规则是明确的“ABAB CDCD EFEF GG”,共有 7 组押韵。对于生成的示例,先使用 CMU 的发音词典获取单词在押韵位置上的音素,然后将原始单词和提取出来的音素的重叠单位进行分组计数,进行评价。同样也使用 Macro-F1 和 Micro-F1 进行评估。
句子完整性:
在模板的限制下,模型必须使用有限的位置来组织语言,因此句子的完整性可能会是一个严重的问题。例如,句子`"love is not love . </s>"`要比`"love is not the . </s>"`在语义的完整性要更好。在对句子完整性进行评价时使用了一种简单明了的方法,即在给定生成前缀下计算 `</s>`之前标点符号的预测概率:
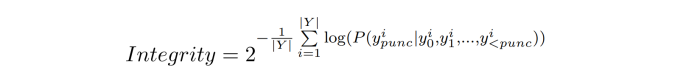
完整性度量值越小,表示句子质量越高。为了实现这一目标,文本分别用大规模中英语料在 GPT2 模型进行预训练,然后用 GPT2 模型对句子完整性进行评估。
生成实例说明
指定模板生成:
Table 5 分别介绍了 SongCi 和十四行诗生成的几个案例。宋词的格式(CiPai)都是冷启动样本,它们不在训练集中,甚至是新定义的。SongNet 仍然可以在格式、韵律和完整性方面产生高质量的结果。对于语料库只有 100 个样本的十四行诗来说,虽然 SongNet 可以生成 14 行文本,但质量就不如宋词那般好了。

预先填入词的生成:
实测效果如 Table 6 所示:

总结
刘杰鹏,毕业于华中科技大学,研究方向机器阅读理解、文本生成等。现居深圳,微信号onepieceand,欢迎同道中人进一步交流。







