【知识图谱】知识图谱怎么与深度学习结合?
大数据时代的到来,为人工智能的飞速发展带来前所未有的数据红利。在大数据的“喂养”下,人工智能技术获得了前所未有的长足进步。其进展突出体现在以知识图谱为代表的知识工程以及深度学习为代表的机器学习等相关领域。随着深度学习对于大数据的红利消耗殆尽,深度学习模型效果的天花板日益迫近。另一方面大量知识图谱不断涌现,这些蕴含人类大量先验知识的宝库却尚未被深度学习有效利用。融合知识图谱与深度学习,已然成为进一步提升深度学习模型效果的重要思路之一。以知识图谱为代表的符号主义、以深度学习为代表的联结主义,日益脱离原先各自独立发展的轨道,走上协同并进的新道路。
一、历史背景
大数据为机器学习,特别是深度学习带来前所未有的数据红利。得益于大规模标注数据,深度神经网络能够习得有效的层次化特征表示,从而在图像识别等领域取得优异效果。但是随着数据红利消失殆尽,深度学习也日益体现出其局限性,尤其体现在依赖大规模标注数据和难以有效利用先验知识等方面。这些局限性阻碍了深度学习的进一步发展。另一方面在深度学习的大量实践中,人们越来越多地发现深度学习模型的结果往往与人的先验知识或者专家知识相冲突。如何让深度学习摆脱对于大规模样本的依赖?如何让深度学习模型有效利用大量存在的先验知识?如何让深度学习模型的结果与先验知识一致已成为了当前深度学习领域的重要问题。
当前,人类社会业已积累大量知识。特别是,近几年在知识图谱技术的推动下,对于机器友好的各类在线知识图谱大量涌现。知识图谱本质上是一种语义网络,表达了各类实体、概念及其之间的语义关系。相对于传统知识表示形式(诸如本体、传统语义网络),知识图谱具有实体/概念覆盖率高、语义关系多样、结构友好(通常表示为RDF格式)以及质量较高等优势,从而使得知识图谱日益成为大数据时代和人工智能时代最为主要的知识表示方式。能否利用蕴含于知识图谱中的知识指导深度神经网络模型的学习从而提升模型的性能,成为了深度学习模型研究的重要问题之一。
现阶段将深度学习技术应用于知识图谱的方法较为直接。大量的深度学习模型可以有效完成端到端的实体识别、关系抽取和关系补全等任务,进而可以用来构建或丰富知识图谱。本文主要探讨知识图谱在深度学习模型中的应用。从当前的文献来看,主要有两种方式。一是将知识图谱中的语义信息输入到深度学习模型中;将离散化知识图谱表达为连续化的向量,从而使得知识图谱的先验知识能够成为深度学习的输入。二是利用知识作为优化目标的约束,指导深度学习模型的学习;通常是将知识图谱中知识表达为优化目标的后验正则项。前者的研究工作已有不少文献,并成为当前研究热点。知识图谱向量表示作为重要的特征在问答以及推荐等实际任务中得到有效应用。后者的研究才刚刚起步,本文将重点介绍以一阶谓词逻辑作为约束的深度学习模型。
二、知识图谱作为深度学习的输入
知识图谱是人工智能符号主义近期进展的典型代表。知识图谱中的实体、概念以及关系均采用了离散的、显式的符号化表示。而这些离散的符号化表示难以直接应用于基于连续数值表示的神经网络。为了让神经网络有效利用知识图谱中的符号化知识,研究人员提出了大量的知识图谱的表示学习方法。知识图谱的表示学习旨在习得知识图谱的组成元素(节点与边)的实值向量化表示。这些连续的向量化表示可以作为神经网络的输入,从而使得神经网络模型能够充分利用知识图谱中大量存在的先验知识。这一趋势催生了对于知识图谱的表示学习的大量研究。本章首先简要回顾知识图谱的表示学习,再进一步介绍这些向量表示如何应用到基于深度学习模型的各类实际任务中,特别是问答与推荐等实际应用。
1.知识图谱的表示学习
知识图谱的表示学习旨在学习实体和关系的向量化表示,其关键是合理定义知识图谱中关于事实(三元组< h,r,t >)的损失函数 ƒr(h,t),其中和是三元组的两个实体h和t的向量化表示。通常情况下,当事实 < h,r,t > 成立时,期望最小化 ƒr(h,t)。考虑整个知识图谱的事实,则可通过最小化:
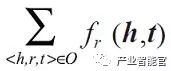
来学习实体以及关系的向量化表示,其中 O 表示知识图谱中所有事实的集合。不同的表示学习可以使用不同的原则和方法定义相应的损失函数。这里以基于距离和翻译的模型介绍知识图谱表示的基本思路[1]。
基于距离的模型。其代表性工作是 SE 模型[2]。基本思想是当两个实体属于同一个三元组 < h,r,t > 时,它们的向量表示在投影后的空间中也应该彼此靠近。因此,损失函数定义为向量投影后的距离
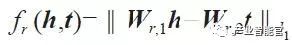
其中矩阵 Wr,1 和 Wr,2 用于三元组中头实体 h 和尾实体 t 的投影操作。但由于 SE 引入了两个单独的投影矩阵,导致很难捕获实体和关系之间的语义相关性。Socher 等人针对这一问题采用三阶张量替代传统神经网络中的线性变换层来刻画评分函数。Bordes 等人提出能量匹配模型,通过引入多个矩阵的 Hadamard 乘积来捕获实体向量和关系向量的交互关系。
基于翻译的表示学习。其代表性工作 TransE 模型通过向量空间的向量翻译来刻画实体与关系之间的相关性[3]。该模型假定,若 < h,r,t > 成立则尾部实体 t 的嵌入表示应该接近头部实体 h 加上关系向量 r 的嵌入表示,即 h+r≈t。因此,TransE 采用
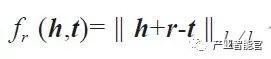
作为评分函数。当三元组成立时,得分较低,反之得分较高。TransE 在处理简单的 1-1 关系(即关系两端连接的实体数比率为 1:1)时是非常有效的,但在处理 N-1、1-N 以及 N-N 的复杂关系时性能则显著降低。针对这些复杂关系,Wang 提出了 TransH 模型通过将实体投影到关系所在超平面,从而习得实体在不同关系下的不同表示。Lin 提出了 TransR 模型通过投影矩阵将实体投影到关系子空间,从而习得不同关系下的不同实体表示。
除了上述两类典型知识图谱表示学习模型之外,还有大量的其他表示学习模型。比如,Sutskever 等人使用张量因式分解和贝叶斯聚类来学习关系结构。Ranzato 等人引入了一个三路的限制玻尔兹曼机来学习知识图谱的向量化表示,并通过一个张量加以参数化。
当前主流的知识图谱表示学习方法仍存在各种各样的问题,比如不能较好刻画实体与关系之间的语义相关性、无法较好处理复杂关系的表示学习、模型由于引入大量参数导致过于复杂,以及计算效率较低难以扩展到大规模知识图谱上等等。为了更好地为机器学习或深度学习提供先验知识,知识图谱的表示学习仍是一项任重道远的研究课题。
知识图谱向量化表示的应用
应用 1: 问答系统。自然语言问答是人机交互的重要形式。深度学习使得基于问答语料的生成式问答成为可能。然而目前大多数深度问答模型仍然难以利用大量的知识实现准确回答。Yin 等人针对简单事实类问题,提出了一种基于 encoder-decoder 框架,能够充分利用知识图谱中知识的深度学习问答模型[4]。在深度神经网络中,一个问题的语义往往被表示为一个向量。具有相似向量的问题被认为是具有相似语义。这是联结主义的典型方式。另一方面,知识图谱的知识表示是离散的,即知识与知识之间并没有一个渐变的关系。这是符号主义的典型方式。通过将知识图谱向量化,可以将问题与三元组进行匹配(也即计算其向量相似度),从而为某个特定问题找到来自知识库的最佳三元组匹配。匹配过程如图 1 所示。对于问题 Q:“How tallis Yao Ming?”,首先将问题中的单词表示为向量数组 HQ。进一步寻找能与之匹配的知识图谱中的候选三元组。最后为这些候选三元组,分别计算问题与不同属性的语义相似度。其由以下相似度公式决定:
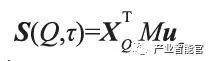
这里,S(Q,τ) 表示问题Q 与候选三元组τ 的相似度;xQ 表示问题的向量( 从HQ计算而得),uτ 表示知识图谱的三元组的向量,M是待学习参数。
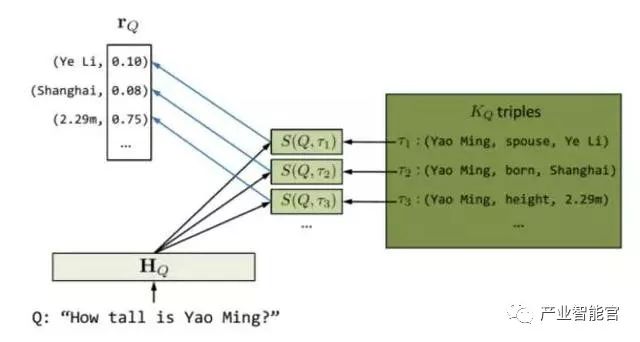
图1 基于知识图谱的神经生成问答模型
应用 2: 推荐系统。个性化推荐系统是互联网各大社交媒体和电商网站的重要智能服务之一。随着知识图谱的应用日益广泛,大量研究工作意识到知识图谱中的知识可以用来完善基于内容的推荐系统中对用户和项目的内容(特征)描述,从而提升推荐效果。另一方面,基于深度学习的推荐算法在推荐效果上日益优于基于协同过滤的传统推荐模型[5]。但是,将知识图谱集成到深度学习的框架中的个性化推荐的研究工作,还较为少见。Zhang 等人做出了这样的尝试。作者充分利用了结构化知识(知识图谱)、文本知识和可视化知识(图片)[6]等三类典型知识。作者分别通过网络嵌入(network embedding)获得结构化知识的向量化表示,然后分别用SDAE(Stacked Denoising Auto-Encoder)和层叠卷积自编码器(stackedconvolution-autoencoder)抽取文本知识特征和图片知识特征;并最终将三类特征融合进协同集成学习框架,利用三类知识特征的整合来实现个性化推荐。作者针对电影和图书数据集进行实验,证明了这种融合深度学习和知识图谱的推荐算法具有较好性能。
知识图谱作为深度学习的约束
Hu 等人提出了一种将一阶谓词逻辑融合进深度神经网络的模型,并将其成功用于解决情感分类和命名实体识别等问题[7]。逻辑规则是一种对高阶认知和结构化知识的灵活表示形式,也是一种典型的知识表示形式。将各类人们已积累的逻辑规则引入到深度神经网络中,利用人类意图和领域知识对神经网络模型进行引导具有十分重要的意义。其他一些研究工作则尝试将逻辑规则引入到概率图模型,这类工作的代表是马尔科夫逻辑网络[8],但是鲜有工作能将逻辑规则引入到深度神经网络中。
Hu 等人所提出的方案框架可以概括为“teacher-student network”,如图 2 所示,包括两个部分 teacher network q(y|x) 和 student network pθ(y|x)。其中 teacher network 负责将逻辑规则所代表的知识建模,student network 利用反向传播方法加上teacher network的约束,实现对逻辑规则的学习。这个框架能够为大部分以深度神经网络为模型的任务引入逻辑规则,包括情感分析、命名实体识别等。通过引入逻辑规则,在深度神经网络模型的基础上实现效果提升。
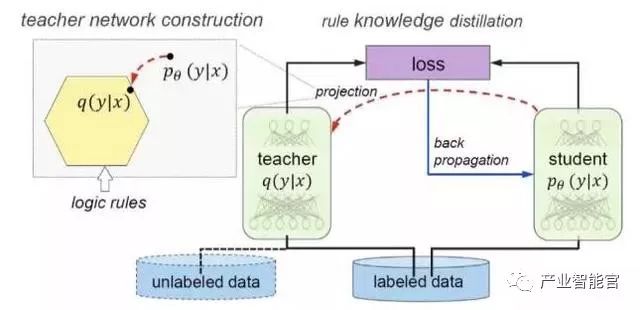
图2 将逻辑规则引入到深度神经网络的“teacher-student network”模型
其学习过程主要包括如下步骤:
利用 soft logic 将逻辑规则表达为 [0, 1] 之间的连续数值。
基于后验正则化(posterior regularization)方法,利用逻辑规则对 teacher network 进行限制,同时保证 teacher network 和 student network 尽量接近。最终优化函数为:
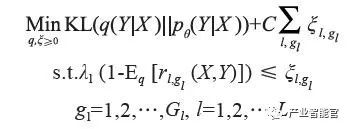
其中,ξl,gl是松弛变量,L 是规则个数,Gl 是第 l 个规则的 grounding 数。KL 函数(Kullback-Leibler Divergence)部分保证 teacher network 和student network 习得模型尽可能一致。后面的正则项表达了来自逻辑规则的约束。
对 student network 进行训练,保证 teacher network 的预测结果和 student network 的预测结果都尽量地好,优化函数如下:
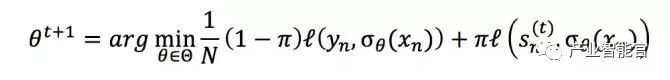
其中,t 是训练轮次,l 是不同任务中的损失函数(如在分类问题中,l 是交叉熵),σθ 是预测函数,sn(t) 是 teacher network 的预测结果。
重复 1~3 过程直到收敛。
后记
随着深度学习研究的进一步深入,如何有效利用大量存在的先验知识,进而降低模型对于大规模标注样本的依赖,逐渐成为主流的研究方向之一。知识图谱的表示学习为这一方向的探索奠定了必要的基础。近期出现的将知识融合进深度神经网络模型的一些开创性工作也颇具启发性。但总体而言,当前的深度学习模型使用先验知识的手段仍然十分有限,学术界在这一方向的探索上仍然面临巨大的挑战。这些挑战主要体现在两个方面:
如何获取各类知识的高质量连续化表示。当前知识图谱的表示学习,不管是基于怎样的学习原则,都不可避免地产生语义损失。符号化的知识一旦向量化后,大量的语义信息被丢弃,只能表达十分模糊的语义相似关系。如何为知识图谱习得高质量的连续化表示仍然是个开放问题。
如何在深度学习模型中融合常识知识。大量的实际任务(诸如对话、问答、阅读理解等等)需要机器理解常识。常识知识的稀缺严重阻碍了通用人工智能的发展。如何将常识引入到深度学习模型将是未来人工智能研究领域的重大挑战,同时也是重大机遇。

关键词:大数据、人工智能、知识图谱、深度学习、问答系统、推荐系统
图网络让深度学习也能因果推理

新智元报道
来源:Arxiv; Quanta Magazine等
编辑:闻菲,刘小芹
【新智元导读】DeepMind联合谷歌大脑、MIT等机构27位作者发表重磅论文,提出“图网络”(Graph network),将端到端学习与归纳推理相结合,有望解决深度学习无法进行关系推理的问题。
作为行业的标杆,DeepMind的动向一直是AI业界关注的热点。最近,这家世界最顶级的AI实验室似乎是把他们的重点放在了探索“关系”上面,6月份以来,接连发布了好几篇“带关系”的论文,比如:
关系归纳偏置(Relational inductive bias for physical construction in humans and machines)
关系深度强化学习(Relational Deep Reinforcement Learning)
关系RNN(Relational Recurrent Neural Networks)
论文比较多,但如果说有哪篇论文最值得看,那么一定选这篇——《关系归纳偏置、深度学习和图网络》。

这篇文章联合了DeepMind、谷歌大脑、MIT和爱丁堡大学的27名作者(其中22人来自DeepMind),用37页的篇幅,对关系归纳偏置和图网络(Graph network)进行了全面阐述。
DeepMind的研究科学家、大牛Oriol Vinyals颇为罕见的在Twitter上宣传了这项工作(他自己也是其中一位作者),并表示这份综述“pretty comprehensive”。

有很不少知名的AI学者也对这篇文章做了点评。
曾经在谷歌大脑实习,从事深度强化学习研究的Denny Britz说,他很高兴看到有人将图(Graph)的一阶逻辑和概率推理结合到一起,这个领域或许会迎来复兴。

芯片公司Graphcore的创始人Chris Gray评论说,如果这个方向继续下去并真的取得成果,那么将为AI开创一个比现如今的深度学习更加富有前景的基础。

康纳尔大学数学博士/MIT博士后Seth Stafford则认为,图神经网络(Graph NNs)可能解决图灵奖得主Judea Pearl指出的深度学习无法做因果推理的核心问题。
那么,这篇论文是关于什么的呢?DeepMind的观点和要点在这一段话里说得非常清楚:
这既是一篇意见书,也是一篇综述,还是一种统一。我们认为,如果AI要实现人类一样的能力,必须将组合泛化(combinatorial generalization)作为重中之重,而结构化的表示和计算是实现这一目标的关键。
正如生物学里先天因素和后天因素是共同发挥作用的,我们认为“人工构造”(hand-engineering)和“端到端”学习也不是只能从中选择其一,我们主张结合两者的优点,从它们的互补优势中受益。
在论文里,作者探讨了如何在深度学习结构(比如全连接层、卷积层和递归层)中,使用关系归纳偏置(relational inductive biases),促进对实体、对关系,以及对组成它们的规则进行学习。
他们提出了一个新的AI模块——图网络(graph network),是对以前各种对图进行操作的神经网络方法的推广和扩展。图网络具有强大的关系归纳偏置,为操纵结构化知识和生成结构化行为提供了一个直接的界面。
作者还讨论了图网络如何支持关系推理和组合泛化,为更复杂、可解释和灵活的推理模式打下基础。
2018年初,承接NIPS 2017有关“深度学习炼金术”的辩论,深度学习又迎来了一位重要的批评者。
图灵奖得主、贝叶斯网络之父Judea Pearl,在ArXiv发布了他的论文《机器学习理论障碍与因果革命七大火花》,论述当前机器学习理论局限,并给出来自因果推理的7大启发。Pearl指出,当前的机器学习系统几乎完全以统计学或盲模型的方式运行,不能作为强AI的基础。他认为突破口在于“因果革命”,借鉴结构性的因果推理模型,能对自动化推理做出独特贡献。

在最近的一篇访谈中,Pearl更是直言,当前的深度学习不过只是“曲线拟合”(curve fitting)。“这听起来像是亵渎……但从数学的角度,无论你操纵数据的手段有多高明,从中读出来多少信息,你做的仍旧只是拟合一条曲线罢了。”
如何解决这个问题?DeepMind认为,要从“图网络”入手。
大数医达创始人、CMU博士邓侃为我们解释了DeepMind这篇论文的研究背景。
邓侃博士介绍,机器学习界有三个主要学派,符号主义(Symbolicism)、连接主义(Connectionism)、行为主义(Actionism)。
符号主义的起源,注重研究知识表达和逻辑推理。经过几十年的研究,目前这一学派的主要成果,一个是贝叶斯因果网络,另一个是知识图谱。
贝叶斯因果网络的旗手是 Judea Pearl 教授,2011年的图灵奖获得者。但是据说 2017年 NIPS 学术会议上,老爷子演讲时,听众寥寥。2018年,老爷子出版了一本新书,“The Book of Why”,为因果网络辩护,同时批判深度学习缺乏严谨的逻辑推理过程。而知识图谱主要由搜索引擎公司,包括谷歌、微软、百度推动,目标是把搜索引擎,由关键词匹配,推进到语义匹配。
连接主义的起源是仿生学,用数学模型来模仿神经元。Marvin Minsky 教授因为对神经元研究的推动,获得了1969年图灵奖。把大量神经元拼装在一起,就形成了深度学习模型,深度学习的旗手是 Geoffrey Hinton 教授。深度学习模型最遭人诟病的缺陷,是不可解释。
行为主义把控制论引入机器学习,最著名的成果是强化学习。强化学习的旗手是 Richard Sutton 教授。近年来Google DeepMind 研究员,把传统强化学习,与深度学习融合,实现了 AlphaGo,战胜当今世界所有人类围棋高手。
DeepMind 前天发表的这篇论文,提议把传统的贝叶斯因果网络和知识图谱,与深度强化学习融合,并梳理了与这个主题相关的研究进展。
在这里,有必要对说了这么多的“图网络”做一个比较详细的介绍。当然,你也可以跳过这一节,直接看后面的解读。
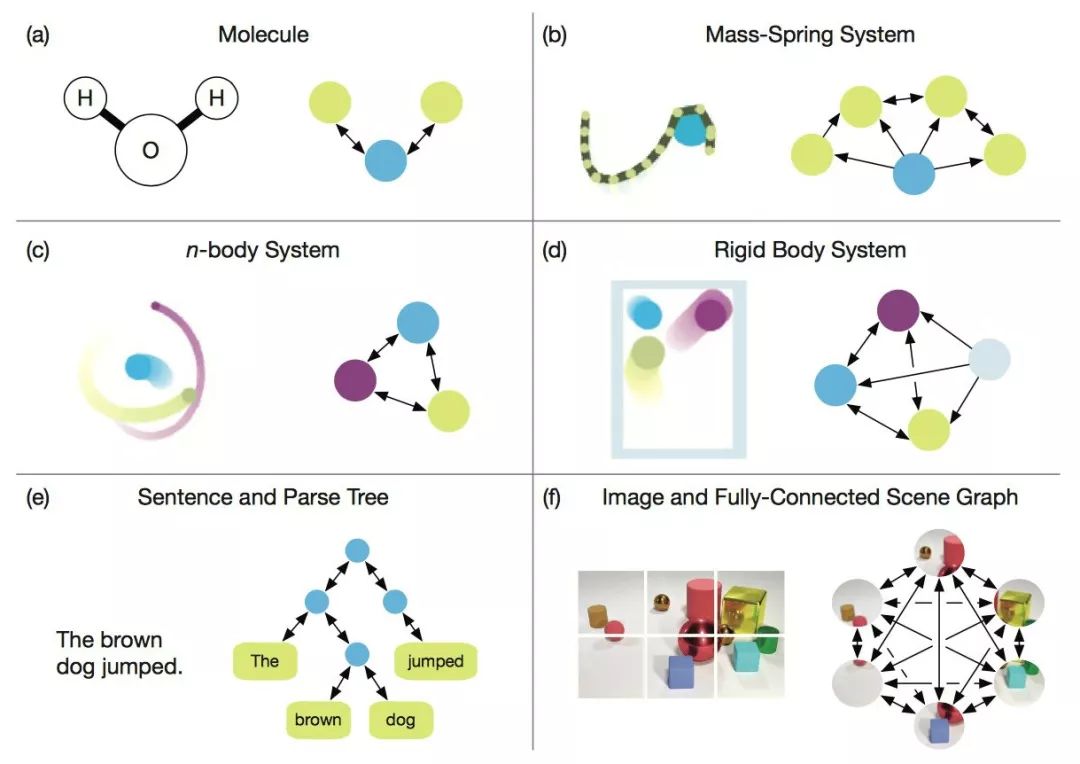
在《关系归纳偏置、深度学习和图网络》这篇论文里,作者详细解释了他们的“图网络”。图网络(GN)的框架定义了一类用于图形结构表示的关系推理的函数。GN 框架概括并扩展了各种的图神经网络、MPNN、以及 NLNN 方法,并支持从简单的构建块(building blocks)来构建复杂的结构。
GN 框架的主要计算单元是 GN block,即 “graph-to-graph” 模块,它将 graph 作为输入,对结构执行计算,并返回 graph 作为输出。如下面的 Box 3 所描述的,entity 由 graph 的节点(nodes),边的关系(relations)以及全局属性(global attributes)表示。
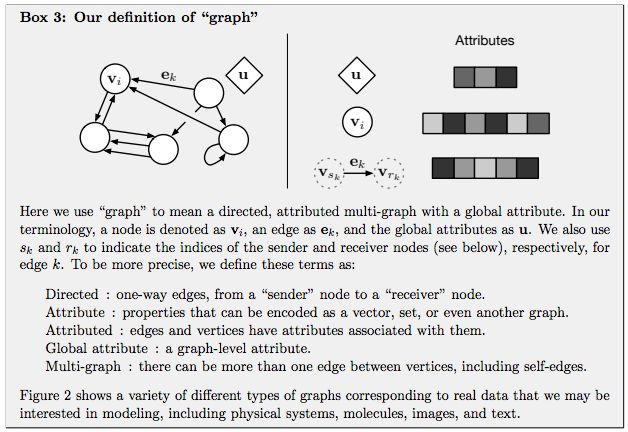
论文作者用 “graph” 表示具有全局属性的有向(directed)、有属性(attributed)的 multi-graph。一个节点(node)表示为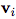
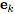
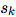
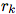
Directed:单向,从 “sender” 节点指向 “receiver” 节点。
Attribute:属性,可以编码为矢量(vector),集合(set),甚至另一个图(graph)
Attributed:边和顶点具有与它们相关的属性
Global attribute:graph-level 的属性
Multi-graph:顶点之间有多个边
GN 框架的 block 的组织强调可定制性,并综合表示所需关系归纳偏置(inductive biases)的新架构。
用一个例子来更具体地解释 GN。考虑在任意引力场中预测一组橡胶球的运动,它们不是相互碰撞,而是有一个或多个弹簧将它们与其他球(或全部球)连接起来。我们将在下文的定义中引用这个运行示例,以说明图形表示和对其进行的计算。
“graph” 的定义
在我们的 GN 框架中,一个 graph 被定义为一个 3 元组的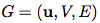
u 表示一个全局属性;例如,u 可能代表重力场。
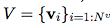
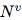
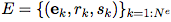
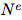
算法 1:一个完整的 GN block 的计算步骤

GN block 的内部结构
一个 GN block 包含三个 “update” 函数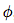
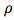
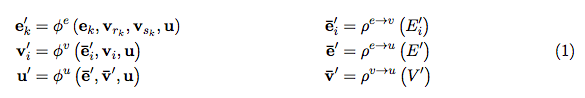
其中:
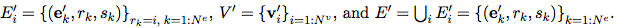
图:GN block 中的 Updates。蓝色表示正在 update 的元素,黑色表示 update 中涉及的其他元素
要把知识图谱和深度学习相结合,邓侃博士认为有几大难点。
1. 点向量:
知识图谱由点和边构成,点(node)用来表征实体(entity),实体又包含属性(attribute)和属性的值(value)。传统知识图谱中的实体,通常由概念符号构成,譬如自然语言的词汇。
传统知识图谱中的边,连接两个单点,也就是两个实体,边表达的是关系,关系的强弱,由权重表达,传统知识图谱的边的权重,通常是常数。
如果想把传统知识图谱与深度学习相融合,首先要做的是实现点的可微分化。用数值化的词向量来替代自然语言的词汇,是实现点的可微分化的有效方法,通常的做法是用语言模型来分析大量的文本,给每个词汇找到最贴合上下文语义的词向量。但在图谱中,传统的词向量的生成算法,不十分奏效,需要改造。
2. 超点:
前文说到,传统知识图谱中的边,连接两个单点,表达两个单点之间的关系。这个假定制约了图谱的表达能力,因为在很多场景下,多个单点组合在一起,才与其它单点或者单点组合,存在关系。我们把单点组合,称之为超点(hyper-node)。
问题是哪些单点组合在一起构成超点?人为的先验指定,当然是一个办法。从大量训练数据中,通过 dropout 或者 regulation 算法,自动学习出超点的构成,也是一个思路。
3. 超边:
传统的知识图谱中的边,表达了点与点之间的关系,关系的强弱由权重表达,通常权重是个常数。但在很多场景下,权重并非是常数。随着点的取值不同,边的权重也发生变化,而且很可能是非线性变化。
用非线性函数来表达图谱的边,称为超边(hyper-edge)。
深度学习模型可以用于模拟非线性函数。所以,知识图谱中每条边都是一个深度学习模型。模型的输入是若干个单点组成的超点,模型的输出是另一个超点。如果把每个深度学习模型,视为一棵树,根是输入,叶子是输出。那么鸟瞰整个知识图谱,实际上是深度学习模型的森林。
4. 路径:
训练知识图谱,包括训练点向量,超点、和超边的时候,一条训练数据往往是在图谱中行走的一条路径,通过拟合海量的路径,获得最贴切的点向量、超点和超边。
用拟合路径来训练图谱,存在的一个问题是,训练过程与过程结束后的评价,两者的脱节。打个比方,给你若干篇文章的提纲,以及相应的范文,让你学习如何写作文。拟合的过程,强调逐字逐句的模仿。但是评价文章的好坏,重点并不在于字句的亦步亦趋,而在于通篇文章的顺畅。
如何解决训练过程与最终评价的脱节?很有潜力的办法,是用强化学习。强化学习的精髓,在于把最终的评价,通过回溯和折现的方法,给路径过程中每一个中间状态,评估它的潜力。
但是强化学习面临的困难,在于中间状态的数量不可太多。当状态数量太多时,强化学习的训练过程,无法收敛。解决收敛问题的办法,是用一个深度学习模型,来估算所有状态的潜力值。换句话说,不需要估算所有状态的潜力值,而只需要训练一个模型的有限参数。
DeepMind 前天发表的这篇文章,提议把深度强化学习与知识图谱等相融合,并梳理了大量的相关研究。但是,论文并没有明确说明 DeepMind 偏向于哪一种具体方案。
或许,针对不同应用场景会有不同方案,并没有通用的最佳方案。
许多重要的现实世界数据集都是以图或网络的形式出现,比如社交网络、知识图谱,万维网等等。 目前,已有越来越多的研究者开始关注神经网络模型对这种结构化数据集的处理。
结合DeepMind、谷歌大脑等发表的一系列的关于图深度学习的论文,是否预示“图深度学习”是下一个AI算法热点?
总之,先从这篇论文看起吧。

地址:https://arxiv.org/pdf/1806.01261.pdf
参考资料
Judea Pearl采访:https://www.quantamagazine.org/to-build-truly-intelligent-machines-teach-them-cause-and-effect-20180515/
图卷积网络:http://tkipf.github.io/graph-convolutional-networks/
关系RNN:https://arxiv.org/pdf/1806.01822v1.pdf
关系深度强化学习:https://arxiv.org/abs/1806.01830
关系归纳偏置https://arxiv.org/pdf/1806.01203.pdf

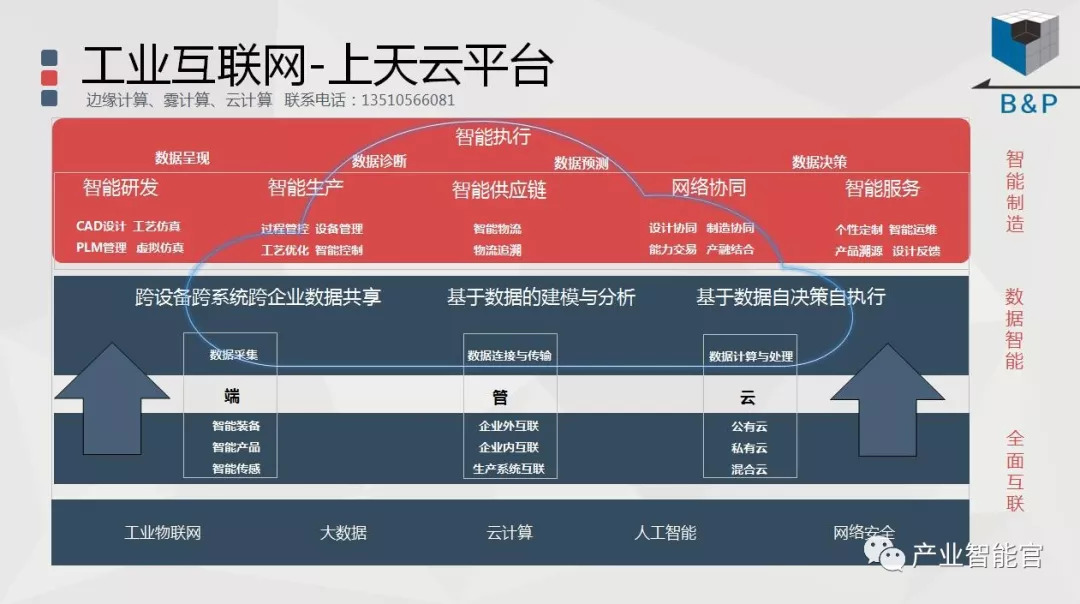
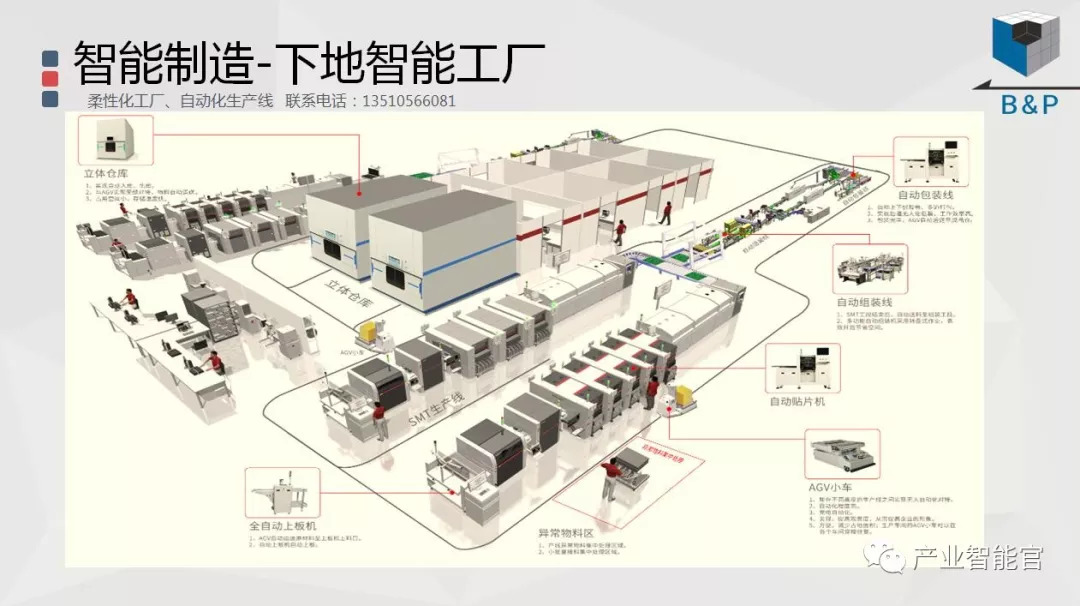
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。

