SGM-Nets:第一个将SGM与深度学习结合的网络
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
1. 简介
本文将对2017年的CVPR会议文章《SGM-Nets: Semi-global matching with neural networks》进行简介,该论文作者为Akihito Seki(东芝公司)、Marc Pollefeys(苏黎世联邦工业大学以及微软公司)。研究针对SGM需要根据影像人工调整惩罚参数的问题,利用深度学习网络自动学习惩罚参数,最后利用Kitti标准数据集进行测试,获得了较好的匹配效果。
2. SGM-Nets
SGM是一种著名的密集匹配方法,SGM简要介绍见(链接至之前写的SGM的文章)。整体研究框架见图1。

如图1所示,整体分为两个阶段,即训练阶段与测试阶段,在训练阶段中SGM-Net通过最小化“路径代价”与“邻域代价”迭代训练,以期为每一个像素提供 和 。在测试阶段中,SGM利用SGM-Net估计的 与 进行视差估计。网络输入为小影像块以及其位置,输出为3D物体结构的惩罚参数。
2.1 路径代价
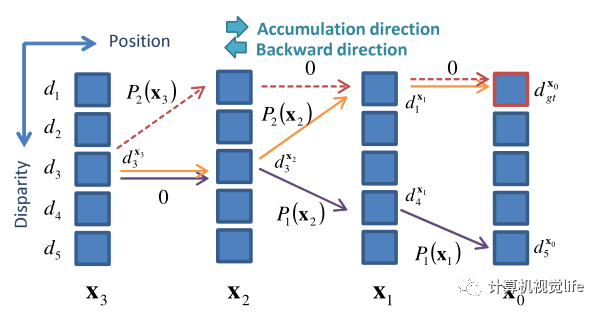
假设像素 的真实视差为 ,那么某一经过该像素的路径代价应当小于任何的其他路径,即, 为便于反向传播,该研究利用hinge损失对其进行表示:
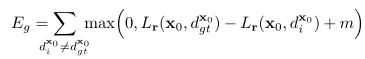
其中,m代表边界。如图2所示,为某一路径下相邻的4个像素,以及每个像素对应的5个候选视差,橙色与紫色的实线分别代表经由 像素正确视差与错误视差 ,聚集代价分别为:
通用表示则为:
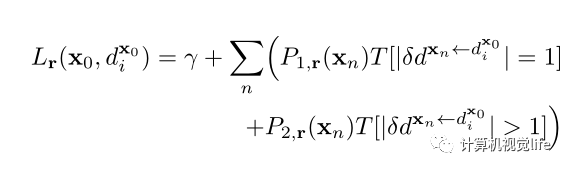
其中 表示每个像素的累计代价以及减去的最小代价。将该式代入hinge损失,并对路径r 和 进行偏微分,得:

据上式可进行正向与反向的传播,该损失函数被该研究定义为“路径损失”。
路径代价的计算无需地面真值,故而可较为容易地使用真实环境下获取的数据集,如KITTI。但路径代价没有考虑到中间路径,如图二中红色虚线路径为真实的路径,但其代价与橙色路径的代价一致。仅以路径代价为损失函数进行网络训练与SGM的结果对比图如图3(c)所示,整体而言,以路径代价为损失进行训练后所得到的视差图效果较SGM更优,但在A处存在信息丢失情况。

2.2 邻域代价
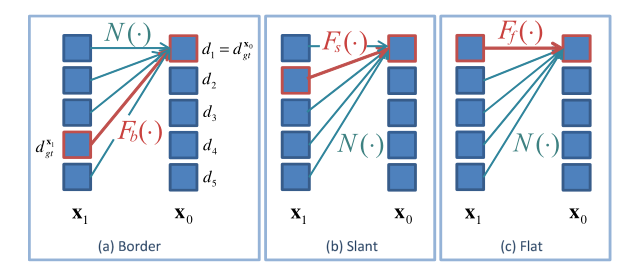
为去除路径代价中中间路径的模糊性,引入“邻域代价”,基本思想为在所有的路径中,穿过连续像素正确视差的路径的代价值必须最小,如图4所示, , 以及 理应小于其他代价 。
邻域代价的公式表示为:
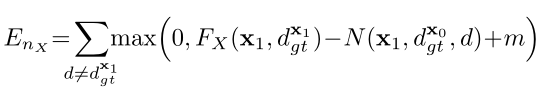
其中 表示:
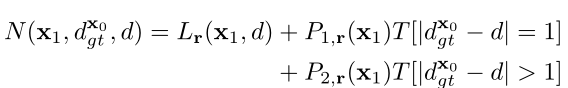
则表示为一个依赖相邻像素关系的函数,如边界 , 倾斜以及平坦 关系,分别为:
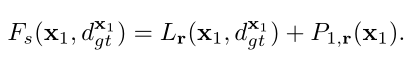
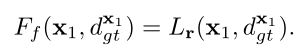
至此,邻域代价可利用类似于路径代价的方式进行微分。应用邻域代价的一个重要前提条件是在像素 的视差必须要估计正确,正因如此,邻域代价无法应用至所有像素,当仅仅使用邻域代价进行训练时,A处细节部分可被保留住,但在B处存在错误匹配,如图三(d)所示。
2.3 综合损失函数
为中和路径代价与邻域代价的优势与弊端,该研究提出最终的综合损失函数为:
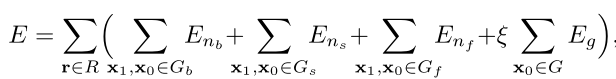
其中 表示混合比例。该研究在每个方向r上随机抽取相同数量的边界像素 、倾斜像素 和平坦 。所有 均有真实视差的标签。惩罚参数 和 的大小与累积成本 有关,反之,累积成本也取决于惩罚参数大小。因此,网络将迭代地进行惩罚参数估计,如图一所示。用该综合损失函数的训练结果如图三(e)所示。
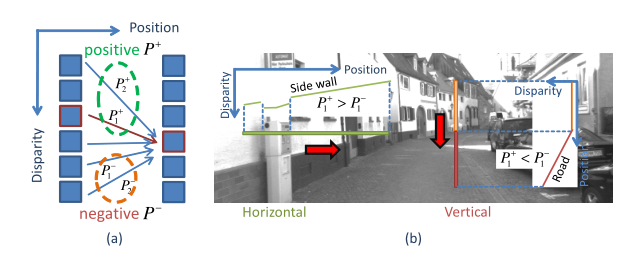
2.4 有向参数化
以上2.1,2.2,2.3中所述内容为SGM的标准参数化,该节将介绍对应的有向参数化。图五为有向参数化的基本思想示意图,所谓的有向参数化指 和 随着视差变化的正向和负向有着不同的数值。
在有向参数化中, 变为:
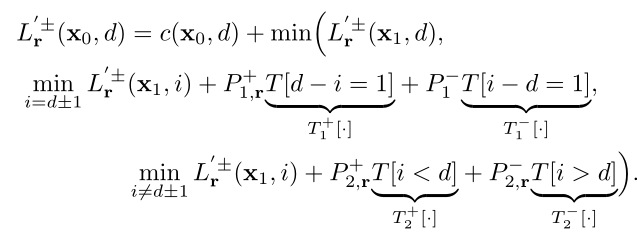
变为:
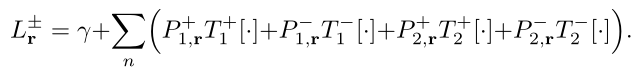
邻域代价中的 则变为:
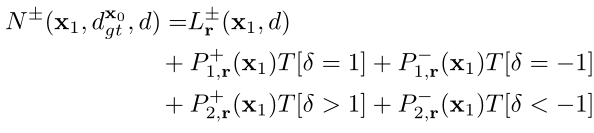
边界像素 变为:

倾斜像素 则变为:
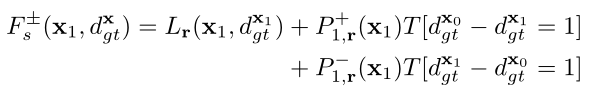
平坦区域的 不变。
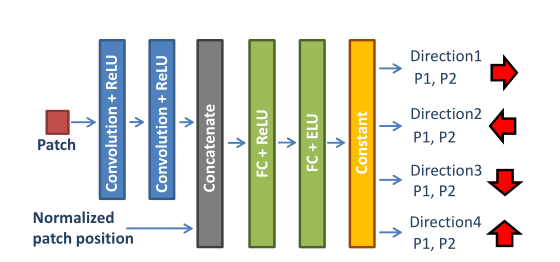
2.5 SGM-Net 网络架构
如图六所示,网络的输入为5*5大小的灰度图像块以及其归一化的位置,网络含有两个卷积层,每个卷积层分别含有16个3 * 3大小的滤波器,且每个卷积层后带着一个ReLU层,再往后跟着一个级联层,用来进行信息结合,第四层为size为128的全连接层以及ReLU层,第五层为size为128的全连接层以及 的ELU层(Exponential Linear Unit),为使SGM的惩罚恒为正数,最后再加上一个常量1。
3. 实验
SGM-Net的训练在 NVIDIA(R) Titan X上利用Torch7进行。在测试SGD和Adam后,发现Adam所达到的误差较小,故而选取了Adam进行优化。网络的初始化是随机的。
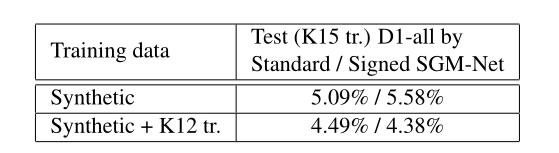
在实验过程中,该研究使用SceneFlow中的“Driving”数据集作为合成影像,KITTI 2012和KITTI 2015作为真实影像。SceneFlow数据提供像素级的真实视差,因此,邻域代价可被利用。表一为以不同数据为训练数据时的测试精度比较表,可以看到,对真实影像进行训练有助于提高SGM-Net的精度。
图七为手动调整惩罚参数,标准SGM-Net以及有向SGM-Net的实验结果图,其中黄色箭头代表明显的错误,右上角的数字表示 Out-Noc 误差。

表二为在K12训练,K12训练以及在K15训练,K12测试的总体准确率表。

截至2016年的10月18日,该方法名列K12和K15的榜首,如今随着深度学习在立体匹配领域的深入,该方法虽然已经在榜上占不住一席之地,但文章思想仍值得借鉴与学习。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿欢迎联系:simiter@126.com
推荐阅读
最新AI干货,我在看



