本文介绍浙江大学、威斯康星大学麦迪逊分校等机构的最新工作 PiCO,相关论文已被 ICLR 2022 录用(Oral, Top 1.59%)!
偏标签学习 (Partial Label Learning, PLL) 是一个经典的弱监督学习问题,它允许每个训练样本关联一个候选的标签集合,适用于许多具有标签不确定性的的现实世界数据标注场景。然而,现存的 PLL 算法与完全监督下的方法依然存在较大差距。
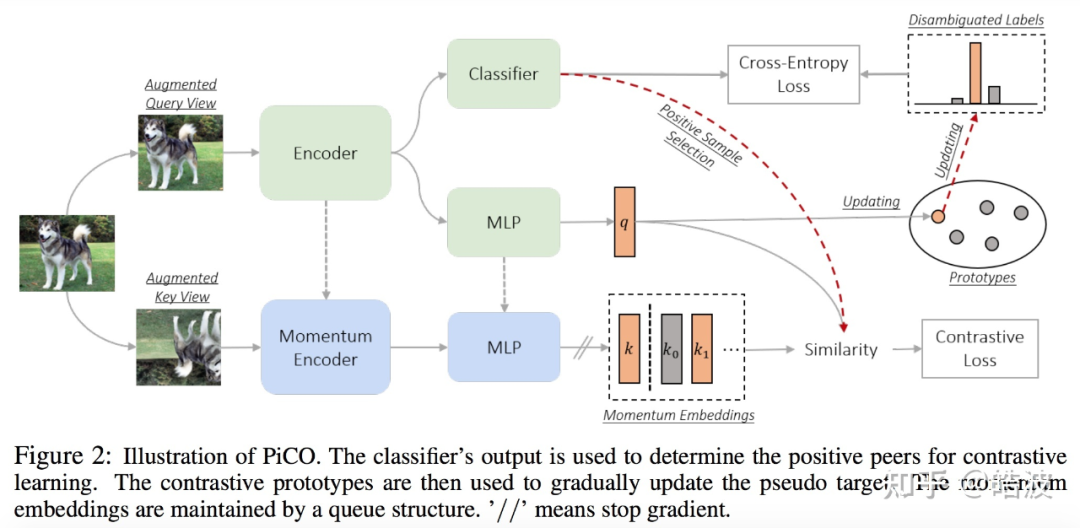
为此,本文提出一个协同的框架解决 PLL 中的两个关键研究挑战 —— 表征学习和标签消歧。具体地,
研究者提出的 PiCO 由一个对比学习模块和一个新颖的基于类原型的标签消歧算法组成。PiCO 为来自同一类的样本生成紧密对齐的表示,同时促进标签消歧
。从理论上讲,研究者表明这两个组件能够互相促进,并且可以从期望最大化 (EM) 算法的角度得到严格证明。大量实验表明,PiCO 在 PLL 中显着优于当前最先进的 PLL 方法,甚至可以达到与完全监督学习相当的结果。
![]()
深度学习的兴起依赖于大量的准确标注数据,然而在许多场景下,数据标注本身存在较大的不确定性。例如,大部分非专业标注者都无法确定一只狗到底是阿拉斯加还是哈士奇。这样的问题称为
标签歧义(Label Ambiguity)
,源于样本本身的模糊性和标注者的知识不足,在更需要专业性的标注场景中十分普遍。此时,要获得准确的标注,通常需要聘用具有丰富领域知识的专家进行标注。为了减少这类问题的标注成本,本文研究偏标签学习 [1](Partial Label Learning,PLL),在该问题中,研究者允许样本
![]() 关联一个候选标签集合
关联一个候选标签集合
![]() ,
其中包含了真实的标签
,
其中包含了真实的标签
![]() 。
在 PLL 问题中,最重要的问题为
标签消歧(Disambiguation)
,即从候选标签集合中识别得到真实的标签。为了解决 PLL 问题,现有的工作通常假设样本具有良好的表征,然后基于平滑假设进行标签消歧,即假设特征接近的样本可能共享相同的真实标签。然而,对表征的依赖致使 PLL 方法陷入了
表征 - 消歧困境
:标注的不确定性会严重影响表征学习,表征的质量又反向影响了标签消歧。因此,现有的 PLL 方法的性能距离完全监督学习的场景,依然存在一定的差距。
。
在 PLL 问题中,最重要的问题为
标签消歧(Disambiguation)
,即从候选标签集合中识别得到真实的标签。为了解决 PLL 问题,现有的工作通常假设样本具有良好的表征,然后基于平滑假设进行标签消歧,即假设特征接近的样本可能共享相同的真实标签。然而,对表征的依赖致使 PLL 方法陷入了
表征 - 消歧困境
:标注的不确定性会严重影响表征学习,表征的质量又反向影响了标签消歧。因此,现有的 PLL 方法的性能距离完全监督学习的场景,依然存在一定的差距。
为此,研究者提出了一个协同的框架 PiCO,引入了对比学习技术(Contrastive Learning,CL),来同时解决表示学习和标签消歧这两个高度相关的问题。本文的主要贡献如下:
方法:本论文率先探索了部分标签学习的对比学习,并提出了一个名为 PiCO 的新框架。作为算法的一个组成部分,研究者还引入了一种新的基于原型的标签消歧机制,有效利用了对比学习的 embeddings。
实验:研究者提出的 PiCO 框架在多个数据集上取得了 SOTA 的结果。此外,研究者首次尝试在细粒度分类数据集上进行实验,与 CUB-200 数据集的最佳基线相比,分类性能提高了 9.61%。
理论:在理论上,研究者证明了 PiCO 等价于以 Expectation-Maximization 过程最大化似然。研究者的推导也可推广到其他对比学习方法,证明了 CL 中的对齐(Alignment)性质 [2] 在数学上等于经典聚类算法中的 M 步。
![]()
简而言之,PiCO 包含两个关键组件,分别进行表示学习和标签消歧。这两个组件系统地作为一个整体运行并相互反哺。后续,研究者也会进一步从 EM 的角度对 PiCO 的进行严格的理论解释。
分类损失(Classification Loss)
给定数据集
![]() ,每个元组包含
,每个元组包含
![]() 和一个候选标签集合
和一个候选标签集合
![]() 。
为了有效解决 PLL 问题,研究者为每个样本
。
为了有效解决 PLL 问题,研究者为每个样本
![]() 维护一个伪标签向量
维护一个伪标签向量
![]() 。
在训练过程中,研究者会不断更新这个伪标签向量,而模型则会优化以下损失进行更新分类器
。
在训练过程中,研究者会不断更新这个伪标签向量,而模型则会优化以下损失进行更新分类器
![]() ,
,
![]()
PLL的对比表征学习(Contrastive Representation Learning For PLL)
受到监督对比学习(SCL)[3] 的启发,研究者旨在引入对比学习机制,为来自同一类的样本学习相近的表征。PiCO 的基本结构和 MoCo [4] 类似,均由两个网络构成,分别为 Query 网络
![]() 和 Key 网络
和 Key 网络
![]() 。
给定一个样本
。
给定一个样本
![]() ,研究者首先利用随机数据增强技术获得两个增广样本,分别称为 Query View 和 Key View。
然后,它们会被分别输入两个网络,获得一对
,研究者首先利用随机数据增强技术获得两个增广样本,分别称为 Query View 和 Key View。
然后,它们会被分别输入两个网络,获得一对
![]() - 归一化的 embeddings,即
- 归一化的 embeddings,即
![]() 和
和
![]() 。
实现时,研究者让 Query 网络与分类器共享相同的卷积块,并增加一个额外的投影网络。
和 MoCo 一样,研究者利用 Query 网络的动量平均(Momentum Averaging)技术对 Key 网络进行更新。
并且,研究者引入一个队列 queue,存储过去一段时间内的 Key embedding。
由此,研究者获得了以下的对比学习 embedding pool:
。
实现时,研究者让 Query 网络与分类器共享相同的卷积块,并增加一个额外的投影网络。
和 MoCo 一样,研究者利用 Query 网络的动量平均(Momentum Averaging)技术对 Key 网络进行更新。
并且,研究者引入一个队列 queue,存储过去一段时间内的 Key embedding。
由此,研究者获得了以下的对比学习 embedding pool:
![]() 。
接着,研究者根据如下公式计算每个样本的对比损失:
。
接着,研究者根据如下公式计算每个样本的对比损失:
![]()
其中
![]() 是对比学习中的正样本集,而
是对比学习中的正样本集,而
![]() 。
。
![]() 是温度参数。
是温度参数。
Positive Set 选择
。可以发现,对比学习模块中,最重要的问题即为正样本集合的构建。然而,在 PLL 问题中,真实标签是未知的,因此无法直接选择同类样本。因此,研究者采用了一个简单而有效的策略,即直接使用分类器预测的标签:
![]() ,构建如下正样本集:
,构建如下正样本集:
![]()
为了节约计算效率,研究者还维护一个标签队列来存储之前几个 Batch 的预测。尽管该策略很简单,却能得到非常好的实验结果,并且能够从理论上被证明该策略是行之有效的。
基于原型的标签消歧(Prototype-based Label Disambiguation)
值得注意的是,对比学习依然依赖于准确的分类器预测,因此依然需要一个有效的标签消歧策略,获取准确的标签估计。为此,研究者提出了一个新颖的基于原型的标签消歧策略。具体的,研究者为每个标签
![]() 维护了一个原型 embedding 向量
维护了一个原型 embedding 向量
![]() ,它可以被看作一组具有代表性的 embedding 向量。
伪标签更新
。在学习过程中,研究者首先将 S
初始化为 Uniform 向量
,它可以被看作一组具有代表性的 embedding 向量。
伪标签更新
。在学习过程中,研究者首先将 S
初始化为 Uniform 向量
![]() 。
接着,基于类原型,研究者采用一个滑动平均的策略更新伪标签向量,
。
接着,基于类原型,研究者采用一个滑动平均的策略更新伪标签向量,
![]()
即,研究者选择最近的原型对应的标签,逐步更新伪标签 S
。
此处,采用滑动平均原因是对比学习网络输出的 embeddings 在初始阶段并不可靠,此时拟合 Uniform 伪目标能够很好地初始化分类器。
然后,滑动平均策略伪标签平滑地更新为正确的目标,以确保一个稳定的 Traning Dynamic。
原型更新
。为了更新伪标签,一个简单的方法是每个迭代或者 Epoch 中都计算一次每个类的中心,不过这会引起较大的计算代价。因此研究者再一次使用滑动平均技术更新原型,
![]()
即,当
![]() 被预测为类别
被预测为类别
![]() 时,则令
时,则令
![]() 往对应的
往对应的
![]() 向量方向步进一些。
向量方向步进一些。
Insights. 值得注意的是,这两个看似独立的模块实际上能够协同工作。首先,对比学习在 embeddings 空间中具有聚类效果,因此能够被标签消歧模块利用,以获得更准确的类中心。其次,经过标签消歧后,分类器预测的标签更准确,能够反哺对比学习模块构造更精准的 Positive Set。当两个模块达成一致时,整个训练过程就会收敛。研究者在接下来在理论上更严格地讨论 PiCO 与经典 EM 聚类算法的相似之处。
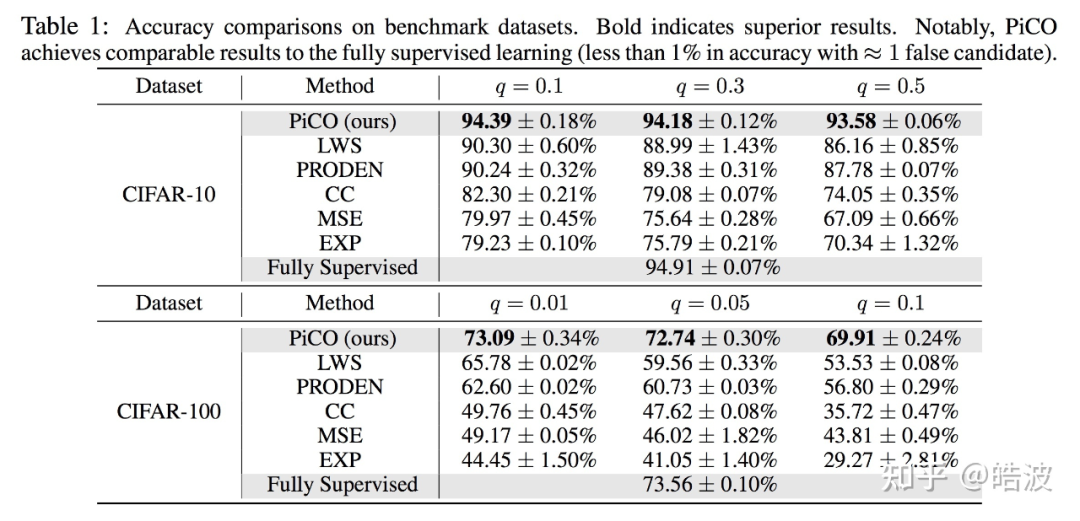
在展开理论分析之前,研究者首先看一下 PiCO 优异的实验效果。首先是在 CIFAR-10、CIFAR-100 上的结果,其中,
![]() 表示每个 Negative Label 成为候选标签的概率。
表示每个 Negative Label 成为候选标签的概率。
![]()
如上图,PiCO 达到了十分出色的实验结果,在两个数据集、不同程度的歧义下(对应
![]() 的大小),均取得了 SOTA 的结果。
值得注意的是,之前的工作 [5][6] 均只探讨了标签量较小的情况(
的大小),均取得了 SOTA 的结果。
值得注意的是,之前的工作 [5][6] 均只探讨了标签量较小的情况(
![]() )
,研究者在 CIFAR-100 上的结果表明,即使在标签空间较大,PiCO 依然具有十分优越良好的性能。
最后,值得注意的是,当
)
,研究者在 CIFAR-100 上的结果表明,即使在标签空间较大,PiCO 依然具有十分优越良好的性能。
最后,值得注意的是,当
![]() 相对较小的时候,PiCO 甚至达到了接近全监督的结果!
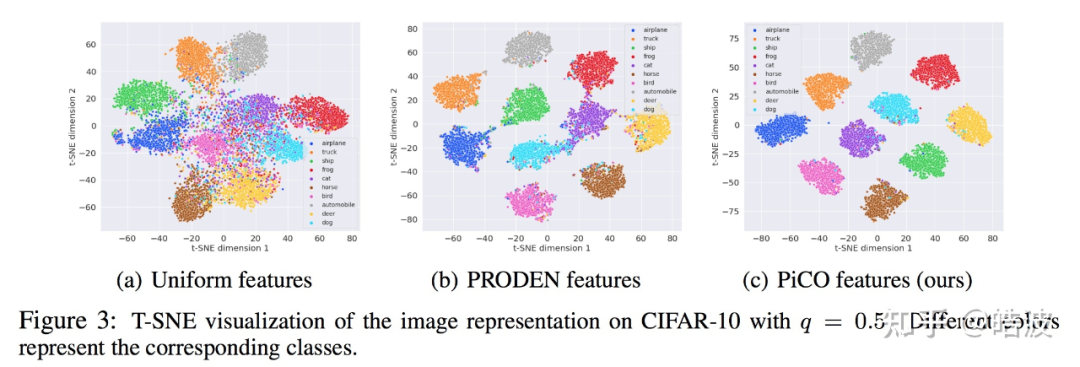
除此之外,研究者还可视化了不同方法学习到的表征,可以看到 Uniform 标签导致了模糊的表征,PRODEN 方法学习到的簇则存在重叠,无法完全分离。相比之下,PiCO 学习的表征更紧凑,更具辨识度。
相对较小的时候,PiCO 甚至达到了接近全监督的结果!
除此之外,研究者还可视化了不同方法学习到的表征,可以看到 Uniform 标签导致了模糊的表征,PRODEN 方法学习到的簇则存在重叠,无法完全分离。相比之下,PiCO 学习的表征更紧凑,更具辨识度。
![]()
最后,研究者展示不同的模块对实验结果的影响,可以看到,标签消歧模块和对比学习模块都会带来非常明显的性能提升,消融其中一个会带来
![]() 的性能下降。
更多的实验结果请详见原论文。
的性能下降。
更多的实验结果请详见原论文。
![]()
终于到了最激动人心的部分!相信大家都有一个疑问:为什么 PiCO 能够获得如此优异的结果?本文中,研究者从理论上分析对比学习得到的原型有助于标签消歧。研究者将会展示,对比学习中的对齐性质(Alignment)本质上最小化了 embedding 空间中的类内协方差,这与经典聚类算法的目标是一致的。这促使研究者从期望最大化算法(Expectation-Maximization,EM)的角度来解释 PiCO。
首先,研究者考虑一个理想的 Setup:在每个训练步骤中,所有数据样本都是可访问的,并且增广的样本也包含在训练集中,即
![]() 。
然后,可以如下计算对比损失:
。
然后,可以如下计算对比损失:
![]()
研究者主要关注第一项 (a),即 Alignment 项 [2],另一项 Uniformity 则被证明有利于 Information-Preserving。在本文中,研究者将其与经典的聚类算法联系起来。研究者首先将数据集划分为
![]() 个子集
个子集
![]() ,
其中每个子集中的样本包含具有相同的预测标签。
实际上,PiCO 的 Positive Set 选择策略也是通过从相同的策略来构造 Positive Sets。
因此,研究者有,
,
其中每个子集中的样本包含具有相同的预测标签。
实际上,PiCO 的 Positive Set 选择策略也是通过从相同的策略来构造 Positive Sets。
因此,研究者有,
![]()
其中
![]() 是一个常数,
是一个常数,
![]() 是
是
![]() 的均值中心。
这里研究者近似
的均值中心。
这里研究者近似
![]() 因为
因为
![]() 通常很大。
为简单起见,研究者省略了
通常很大。
为简单起见,研究者省略了
![]() 符号。
可以看到,Alignment 这一项能够最小化类内方差!
至此,研究者可以将 PiCO 算法解释为优化一个生成模型的 EM 算法。在 E 步,分类器将每个样本分配到一个特定的簇。在 M 步,对比损失将 embedding 集中到他们的簇中心方向。最后,训练数据将被映射到单位超球面上的混合 von Mises-Fisher 分布。
EM-Perspective
。为了估计似然
符号。
可以看到,Alignment 这一项能够最小化类内方差!
至此,研究者可以将 PiCO 算法解释为优化一个生成模型的 EM 算法。在 E 步,分类器将每个样本分配到一个特定的簇。在 M 步,对比损失将 embedding 集中到他们的簇中心方向。最后,训练数据将被映射到单位超球面上的混合 von Mises-Fisher 分布。
EM-Perspective
。为了估计似然
![]() ,研究者额外引入一个假设来建立候选标签集合与真实标签的联系,
,研究者额外引入一个假设来建立候选标签集合与真实标签的联系,
![]()
由此,研究者证明 PiCO 隐式地最大化似然如下,
E-Step
。首先,研究者在引入一组分布
![]() ,
且
,
且
![]() 若
若
![]() ,
,
![]() 。
令
。
令
![]() 为
为
![]() 的参数。
研究者的目标是最大化如下似然,
的参数。
研究者的目标是最大化如下似然,
![]()
最后一步推导使用了 Jensen 不等式。由于
![]() 函
数是凹函数,当
函
数是凹函数,当
![]() 是某些常数时等式成立。
因此,研究者有,
是某些常数时等式成立。
因此,研究者有,
![]()
即为类后验概率。在 PiCO 中,研究者使用分类器输出对其进行估计。
为了估计
![]() ,经典的无监督聚类方法直接将样本分配给最近的聚类中心,如 k-Means 方法;
在完全监督学习情况下,研究者可以直接使用 ground-truth 标签。
然而,在 PLL 问题中,监督信号处于完全监督和无监督之间。
根据研究者的实验观察,候选标签在开始时对后验估计更可靠;
而随着模型训练,对比学习的原型会变得更加可信。
这促使研究者以滑动平均方式更新伪标签。
因此,研究者在估计类后验时有一个很好的初始化信息,并且在训练过程中会被平滑地改善。
最后,由于每个样本对应一个唯一的标签,研究者采用 One-hot 预测
,经典的无监督聚类方法直接将样本分配给最近的聚类中心,如 k-Means 方法;
在完全监督学习情况下,研究者可以直接使用 ground-truth 标签。
然而,在 PLL 问题中,监督信号处于完全监督和无监督之间。
根据研究者的实验观察,候选标签在开始时对后验估计更可靠;
而随着模型训练,对比学习的原型会变得更加可信。
这促使研究者以滑动平均方式更新伪标签。
因此,研究者在估计类后验时有一个很好的初始化信息,并且在训练过程中会被平滑地改善。
最后,由于每个样本对应一个唯一的标签,研究者采用 One-hot 预测
![]() ,
研究者有
,
研究者有
![]() 。
M-Step
。在这一步,研究者假设后验类概率已知,并最大化似然。下述定理表明,最小化对比损失能够也最大化似然的一个下界,
。
M-Step
。在这一步,研究者假设后验类概率已知,并最大化似然。下述定理表明,最小化对比损失能够也最大化似然的一个下界,
![]()
![]()
证明见原文。当
![]() 接
近
1 时,下界较紧,这意味着超球面的类内集中度很高。
直观地说,当假设空间足够丰富时,研究者有可能在欧几里得空间中得到较低的类内协方差,从而导致均值向量
接
近
1 时,下界较紧,这意味着超球面的类内集中度很高。
直观地说,当假设空间足够丰富时,研究者有可能在欧几里得空间中得到较低的类内协方差,从而导致均值向量![]() 的范数很大。
然后,超球面中的归一化 embedding 在也具有较强的类内集中度,因为大的
的范数很大。
然后,超球面中的归一化 embedding 在也具有较强的类内集中度,因为大的![]() 也会导致大的 K 值 [7]。
根据实验结果中的可视化结果,研究者发现 PiCO 确实能够学习紧凑的簇。
因此,研究者认为最小化对比损失也能够最大化似然。
在本文中,研究者提出了一种新颖的偏标签学习框架 PiCO。其关键思想是通过使用对比学习的 embdding 原型从候选集合中识别真实标签。全面的实验结果表明 PiCO 达到了 SOTA 的结果,并在部分情况下达到了接近完全监督的效果。理论分析表明,PiCO 可以被解释为一种 EM 算法。研究者希望研究者的工作能够引起社区的更多关注,以更广泛地使用对比学习技术进行偏标签学习。
欢迎大家加入研究者赵俊博老师所在的浙江大学数据智能实验室和带领的M3 Group(与宝马那辆跑车没啥关系)!!实验室在计算机学院院长陈刚老师带领下,曾获 VLDB 2014/2019 best paper,近年来在 VLDB、ICLR、ICML、ACL、KDD、WWW 等顶级会议和期刊上成果颇丰,多次获得国家级、省级奖项。赵俊博老师是浙江大学百人计划研究员、博士生导师,师承 Yann LeCun,Google 引用 1w+,知乎万粉小 V,AI 赛道连续创业者。
赵俊博主页:http://jakezhao.net/
1. 实际上,PLL 有更直接的别名:Ambiguous Label Learning(模糊 / 歧义标签学习),或 Superset Label Learning(超集标签学习)。本文遵循最常用的名称,称作偏标签学习。
2. Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In ICML, volume 119 of Proceedings of Machine Learning Research, pp. 9929–9939. PMLR, 2020.
3. Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. In NeurIPS, 2020.
4. Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, pp. 9726–9735. IEEE, 2020.
5. Jiaqi Lv, Miao Xu, Lei Feng, Gang Niu, Xin Geng, and Masashi Sugiyama. Progressive identification of true labels for partial-label learning. In ICML, volume 119 of Proceedings of Machine Learning Research, pp. 6500–6510. PMLR, 2020.
6. Lei Feng, Jiaqi Lv, Bo Han, Miao Xu, Gang Niu, Xin Geng, Bo An, and Masashi Sugiyama. Provably consistent partial-label learning. In NeurIPS, 2020b.
7. Arindam Banerjee, Inderjit S. Dhillon, Joydeep Ghosh, and Suvrit Sra. Clustering on the unit hypersphere using von mises-fisher distributions. J. Mach. Learn. Res., 6:1345–1382, 2005.
也会导致大的 K 值 [7]。
根据实验结果中的可视化结果,研究者发现 PiCO 确实能够学习紧凑的簇。
因此,研究者认为最小化对比损失也能够最大化似然。
在本文中,研究者提出了一种新颖的偏标签学习框架 PiCO。其关键思想是通过使用对比学习的 embdding 原型从候选集合中识别真实标签。全面的实验结果表明 PiCO 达到了 SOTA 的结果,并在部分情况下达到了接近完全监督的效果。理论分析表明,PiCO 可以被解释为一种 EM 算法。研究者希望研究者的工作能够引起社区的更多关注,以更广泛地使用对比学习技术进行偏标签学习。
欢迎大家加入研究者赵俊博老师所在的浙江大学数据智能实验室和带领的M3 Group(与宝马那辆跑车没啥关系)!!实验室在计算机学院院长陈刚老师带领下,曾获 VLDB 2014/2019 best paper,近年来在 VLDB、ICLR、ICML、ACL、KDD、WWW 等顶级会议和期刊上成果颇丰,多次获得国家级、省级奖项。赵俊博老师是浙江大学百人计划研究员、博士生导师,师承 Yann LeCun,Google 引用 1w+,知乎万粉小 V,AI 赛道连续创业者。
赵俊博主页:http://jakezhao.net/
1. 实际上,PLL 有更直接的别名:Ambiguous Label Learning(模糊 / 歧义标签学习),或 Superset Label Learning(超集标签学习)。本文遵循最常用的名称,称作偏标签学习。
2. Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In ICML, volume 119 of Proceedings of Machine Learning Research, pp. 9929–9939. PMLR, 2020.
3. Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. In NeurIPS, 2020.
4. Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, pp. 9726–9735. IEEE, 2020.
5. Jiaqi Lv, Miao Xu, Lei Feng, Gang Niu, Xin Geng, and Masashi Sugiyama. Progressive identification of true labels for partial-label learning. In ICML, volume 119 of Proceedings of Machine Learning Research, pp. 6500–6510. PMLR, 2020.
6. Lei Feng, Jiaqi Lv, Bo Han, Miao Xu, Gang Niu, Xin Geng, Bo An, and Masashi Sugiyama. Provably consistent partial-label learning. In NeurIPS, 2020b.
7. Arindam Banerjee, Inderjit S. Dhillon, Joydeep Ghosh, and Suvrit Sra. Clustering on the unit hypersphere using von mises-fisher distributions. J. Mach. Learn. Res., 6:1345–1382, 2005.
知乎原文:https://zhuanlan.zhihu.com/p/463255610
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

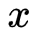 关联一个候选标签集合
关联一个候选标签集合
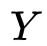 ,
其中包含了真实的标签
,
其中包含了真实的标签
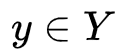 。
。
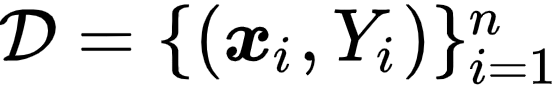 ,每个元组包含
,每个元组包含
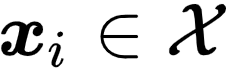 和一个候选标签集合
和一个候选标签集合
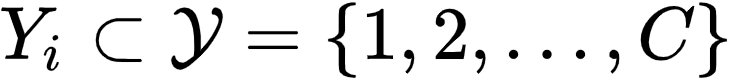 。
为了有效解决 PLL 问题,研究者为每个样本
。
为了有效解决 PLL 问题,研究者为每个样本
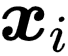 维护一个伪标签向量
维护一个伪标签向量
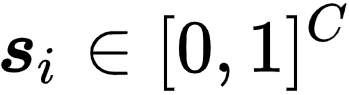 。
在训练过程中,研究者会不断更新这个伪标签向量,而模型则会优化以下损失进行更新分类器
。
在训练过程中,研究者会不断更新这个伪标签向量,而模型则会优化以下损失进行更新分类器
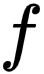 ,
,
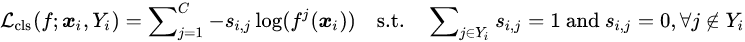
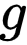 和 Key 网络
和 Key 网络
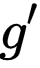 。
给定一个样本
。
给定一个样本
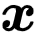 ,研究者首先利用随机数据增强技术获得两个增广样本,分别称为 Query View 和 Key View。
然后,它们会被分别输入两个网络,获得一对
,研究者首先利用随机数据增强技术获得两个增广样本,分别称为 Query View 和 Key View。
然后,它们会被分别输入两个网络,获得一对
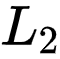 - 归一化的 embeddings,即
- 归一化的 embeddings,即
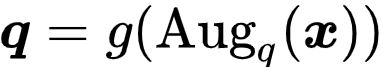 和
和
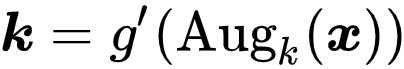 。
。
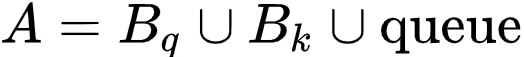 。
接着,研究者根据如下公式计算每个样本的对比损失:
。
接着,研究者根据如下公式计算每个样本的对比损失:
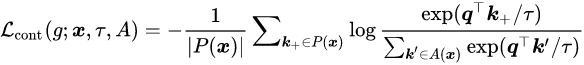
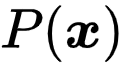 是对比学习中的正样本集,而
是对比学习中的正样本集,而
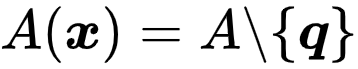 。
。
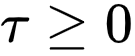 是温度参数。
是温度参数。
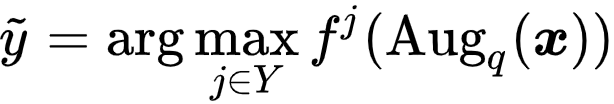 ,构建如下正样本集:
,构建如下正样本集:
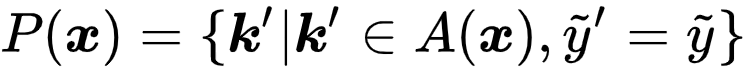
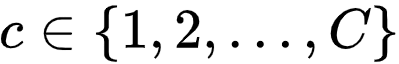 维护了一个原型 embedding 向量
维护了一个原型 embedding 向量
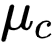 ,它可以被看作一组具有代表性的 embedding 向量。
,它可以被看作一组具有代表性的 embedding 向量。
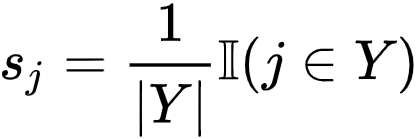 。
接着,基于类原型,研究者采用一个滑动平均的策略更新伪标签向量,
。
接着,基于类原型,研究者采用一个滑动平均的策略更新伪标签向量,
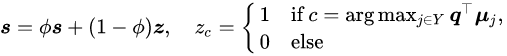
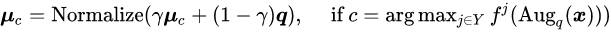
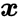 被预测为类别
被预测为类别
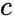 时,则令
时,则令
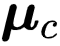 往对应的
往对应的
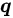 向量方向步进一些。
向量方向步进一些。
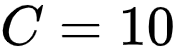 )
,研究者在 CIFAR-100 上的结果表明,即使在标签空间较大,PiCO 依然具有十分优越良好的性能。
最后,值得注意的是,当
)
,研究者在 CIFAR-100 上的结果表明,即使在标签空间较大,PiCO 依然具有十分优越良好的性能。
最后,值得注意的是,当
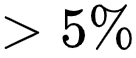 的性能下降。
更多的实验结果请详见原论文。
的性能下降。
更多的实验结果请详见原论文。

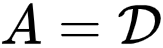 。
然后,可以如下计算对比损失:
。
然后,可以如下计算对比损失:
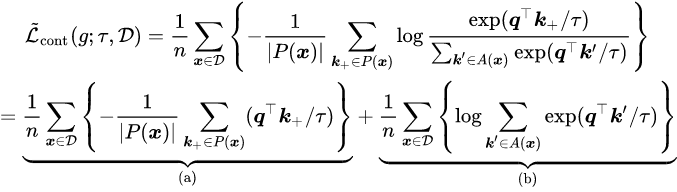
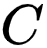 个子集
个子集
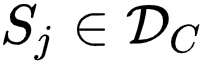 ,
其中每个子集中的样本包含具有相同的预测标签。
实际上,PiCO 的 Positive Set 选择策略也是通过从相同的策略来构造 Positive Sets。
因此,研究者有,
,
其中每个子集中的样本包含具有相同的预测标签。
实际上,PiCO 的 Positive Set 选择策略也是通过从相同的策略来构造 Positive Sets。
因此,研究者有,
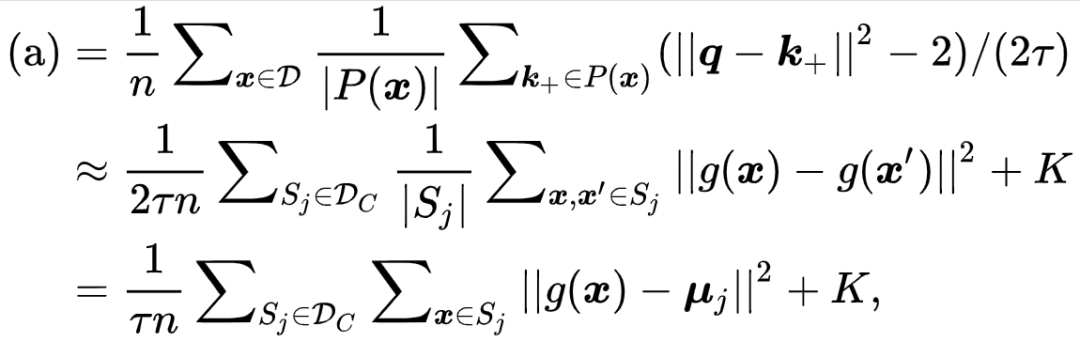
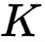 是一个常数,
是一个常数,
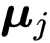 是
是
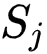 的均值中心。
这里研究者近似
的均值中心。
这里研究者近似
 因为
因为
 通常很大。
为简单起见,研究者省略了
通常很大。
为简单起见,研究者省略了
 符号。
可以看到,Alignment 这一项能够最小化类内方差!
符号。
可以看到,Alignment 这一项能够最小化类内方差!
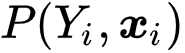 ,研究者额外引入一个假设来建立候选标签集合与真实标签的联系,
,研究者额外引入一个假设来建立候选标签集合与真实标签的联系,

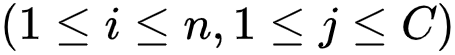 ,
且
,
且
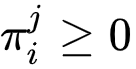 若
若
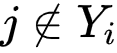 ,
,
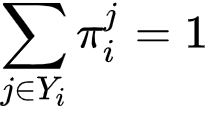 。
令
。
令
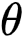 为
为
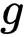 的参数。
研究者的目标是最大化如下似然,
的参数。
研究者的目标是最大化如下似然,
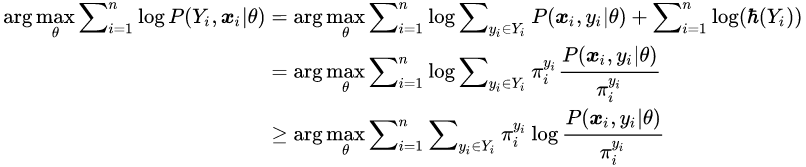
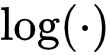 函
数是凹函数,当
函
数是凹函数,当
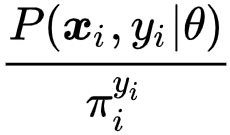 是某些常数时等式成立。
因此,研究者有,
是某些常数时等式成立。
因此,研究者有,
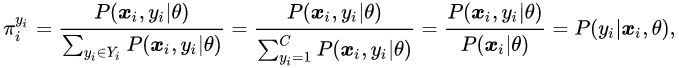
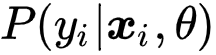 ,经典的无监督聚类方法直接将样本分配给最近的聚类中心,如 k-Means 方法;
在完全监督学习情况下,研究者可以直接使用 ground-truth 标签。
然而,在 PLL 问题中,监督信号处于完全监督和无监督之间。
根据研究者的实验观察,候选标签在开始时对后验估计更可靠;
而随着模型训练,对比学习的原型会变得更加可信。
这促使研究者以滑动平均方式更新伪标签。
因此,研究者在估计类后验时有一个很好的初始化信息,并且在训练过程中会被平滑地改善。
最后,由于每个样本对应一个唯一的标签,研究者采用 One-hot 预测
,经典的无监督聚类方法直接将样本分配给最近的聚类中心,如 k-Means 方法;
在完全监督学习情况下,研究者可以直接使用 ground-truth 标签。
然而,在 PLL 问题中,监督信号处于完全监督和无监督之间。
根据研究者的实验观察,候选标签在开始时对后验估计更可靠;
而随着模型训练,对比学习的原型会变得更加可信。
这促使研究者以滑动平均方式更新伪标签。
因此,研究者在估计类后验时有一个很好的初始化信息,并且在训练过程中会被平滑地改善。
最后,由于每个样本对应一个唯一的标签,研究者采用 One-hot 预测
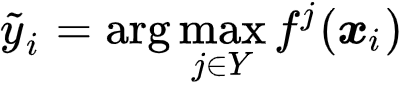 ,
研究者有
,
研究者有
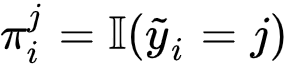 。
。

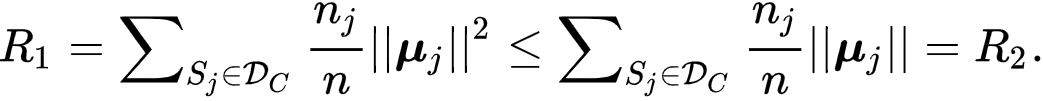
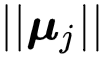 接
近
1 时,下界较紧,这意味着超球面的类内集中度很高。
直观地说,当假设空间足够丰富时,研究者有可能在欧几里得空间中得到较低的类内协方差,从而导致均值向量
接
近
1 时,下界较紧,这意味着超球面的类内集中度很高。
直观地说,当假设空间足够丰富时,研究者有可能在欧几里得空间中得到较低的类内协方差,从而导致均值向量



