
背景:给定行人的可见光(或红外)相机照片,跨模态行人重识别(VI-ReID)旨在从数据库匹配出该行人的红外(或可见光)照片。一个流行的VI-ReID范式是利用行人标注提高不同行人间判别性,同时构建跨模态正负样本对并进行跨模态学习以缩减模态间鸿沟。由于红外模态下的识别度较差,行人训练数据中将不可避免地存在一些噪声标注(Noisy Annotation,NA)。我们发现,这些NA将进一步导致所构建的跨模态正负样本呈现噪声关联(Noisy Correspondence,NC [1-2])。换言之,跨可见光-红外行人重标识任务将面临孪生噪声标签(Twin Noisy Labels,TNL)挑战。针对该挑战,论文[3]提出了一种新的鲁棒VI-ReID方法,名为双重鲁棒训练器(DuAlly Robust Training,DART),其首先利用神经网络的记忆效用来计算标注的置信度。基于置信度,DART将跨模态正负样本分为不同子集并进一步校正其中的关联。最后,DART利用所设计的双重鲁棒损失函数来实现对孪生噪声标签鲁棒的跨模态行人重识别。需要说明的是,过去多年,针对分类任务中“噪声标注”问题(Learning with Noisy Labels)已有许多卓有成效的解决方案。然而,过去多年的大多研究主要针对单模态的图像分类任务,忽视了跨模态任务中潜在的错误关联问题(Learning with Noisy Correspondence)[1-2],更没有实际需求出发,对噪声标注伴生噪声关联的孪生噪声标签现象的揭示和研究。
创新:一方面,本论文在国际上率先揭示了跨模态Re-ID学习中存在但一直被忽略的一个问题——孪生噪声标签学习。其与噪声标签存在以下显著区别:简要地,与传统的噪声标注不同,孪生噪声标签指的是训练数据中同时存在单一样本的标注错误和成对数据的关联错误。另一方面,为解决孪生噪声标签问题,该文提出了一种新的鲁棒学习方法,即双重鲁棒训练(DART)。DART的一个主要创新点是,利用所估计的标注置信度将样本对自适应地划分为四个不同子集并校正其中的关联,从而实现鲁棒的跨模态行人重识别。DART在跨模态行人重识别的两个数据集上进行了大量实验,较为充分验证了提出方法在对孪生噪声标签的鲁棒性。
方法:具体地,针对标签含噪的可见光输入数据和红外光输入数据,通常将不同模态下同一行人(即相同标签)的样本作为正样本对,不同行人(即不同标签)的样本作为负样本对。然而,由于标签含噪,所以正、负样本对中可能分别存在假阳性和假阴性样本对,即错误关联。为处理含噪标签及其所导致的错误关联,得到鲁棒的跨模态行人重识别模型,如图1所示,利用互学习(Co-teaching)思想,本文分别训练两个相同结构但不同初始化的神经网络,通过模型预热、样本置信度建模、样本对划分及关联修正,和双重鲁棒训练五个阶段的建模和训练得到两个鲁棒的神经网络模型,融合两个模型得到最终模型,并用于跨模态行人重识别。
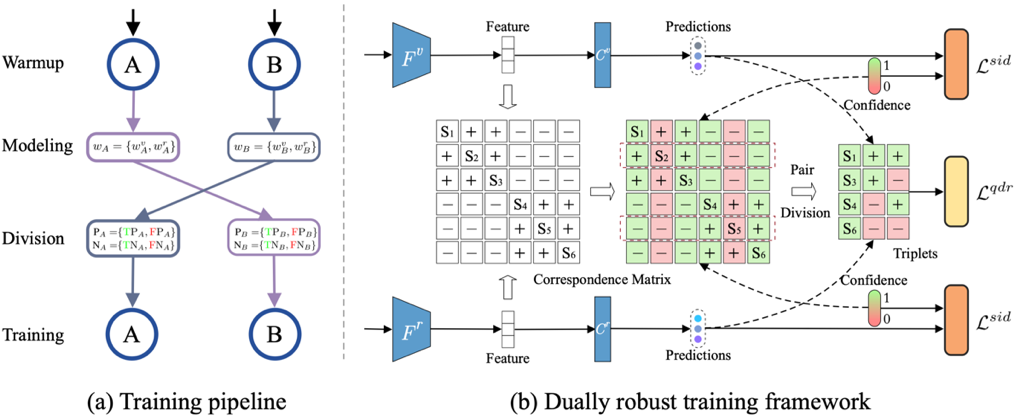
- 模型预热阶段:使用行人重识别中常用的交叉熵损失函数进行模型的初始训练。

具体地,该步骤基于神经网络的记忆效应,即神经网络在拟合复杂的噪声样本之前倾向于优先拟合简单的干净数据样本。利用该效应,在初始的第1个epoch利用上述loss进行模型训练,可得到每个样本的损失值。

- 样本置信度建模:利用一个二成分的高斯混合模型(GMM),对模型预热后得到的所有训练数据的样本损失函数值进行拟合。

为优化GMM,采用了期望最大化算法(EM)。基于记忆效应。将均值较低(即损失较小)的成分作为干净数据集,另一个作为噪声数据集集,同时将每个样本属于较小成分的后验概率作为第i个样本的干净置信度,计算如下:

- 样本对划分及关联修正:对于构成的跨模态样本对,DART通过设置一阈值(实验中固定为0.5),将它们划分成如下干净和噪声集合:

使用如下操作修正样本对的关联:

进一步地,使用如下操作召回可能误判的假阴性样本对:

- 双重鲁棒训练:使用如下的损失函数进行训练

其中,是针对噪声标注的损失函数,其主要利用所估计的样本标注置信度进行惩罚:

是针对噪声关联的损失函数,其实一个新的自适应四元组损失:

其中

针对可能存在的样本对组合,真阳性-真阴性(TP-TN),真阳性-假阴性(TP-FN),假阳性-真阴性(FP-TN),假阳性-假阴性(FP-FN),将会分别自适应地(如图2所示)变成以下形式:

TP-TN:

FP-FN:

TP-FN:

FP-TN:

重复步骤2-4直至网络收敛,即可得到鲁棒的跨模态行人重识别模型。
实验:本文在VI-ReID的两个数据集上进行了实验,包括:SYSU-MM01和RegDB。为验证DART的鲁棒性和有效性,论文分别在噪声率为0%,20%和50%下和包括ADP在内的目前SOTA方法进行对比。由于目前跨模态行人重识别方法无法标签含噪数据,为保证公平性,对比方法中包含了ADP-C,其抛弃了含噪数据,只在干净数据上训练。以下展示部分实验结果,更多结果和分析详见原文。



总结:本文是彭玺教授CVPR2021工作[1]和NeurIPS2021 Oral工作[2]的深入延续。[1]通过探索了对比学习中的假阴性(False Negative)样本对问题,在国际上以对比学习为背景,初步揭示了数据错配和样本对错误关联现象,并构造了一个鲁棒的损失函数,赋予对比学习对假阴性样本的鲁棒性。[2]以跨模态匹配任务为背景,基于对真实数据集(Conceptual Captions)的观察,揭示了假阳性(False Positive)的错误配对现象,首次正式提出了噪声关联学习的概念和方向,并给出了解决方案。而本文则以跨模态行人重识别任务为应用,揭露了噪声标注和其带来的噪声关联,即孪生噪声标签问题(Twin Noisy Labels)对跨模态行人重标识任务中的影响。

