SIGKDD前主席裴健当选加拿大皇家科学院院士!被引超8万次

新智元报道
新智元报道
编辑:肖琴
【新智元导读】加拿大皇家科学院2019新科院士公布,京东集团副总裁、加拿大西蒙弗雷泽大学计算科学学院教授裴健成为入选的华人计算机科学学者。
近日,加拿大皇家学会(The Royal Society of Canada, RSC)官方网站发布新闻公告,93位学者当选为2019年度新科院士,分散于艺术与人文学院、社会科学学院和科学学院。
其中,加拿大皇家科学院新增49位院士,包括4 名外籍院士、3 名特别院士和 1 名荣誉院士。其中 9 位华人学者当选为皇家科学院院士,中科院院长白春礼当选为外籍院士。
新当选的华人学者中,京东集团副总裁、加拿大西蒙弗雷泽大学计算科学学院教授裴健是其中一名计算机科学学者。

裴健的当选理由是:
裴健 - 计算机科学学院,西蒙弗雷泽大学
裴健对数据挖掘、数据分析和应用的基础做出了开创性的贡献。特别是,他发明了最先进的模式挖掘原理和一系列方法,这些方法得到了业界的高度引用和广泛应用,并被数据挖掘学科的教科书和开源软件工具包所采用。
裴健是加拿大西蒙弗雷泽大学计算科学学院教授,统计学与精算系及健康科学学院兼职教授,加拿大一级研究讲席教授 (Canada Research Chair, Tier 1)。2018 年,裴健加入京东,任京东集团副总裁。
裴健在数据科学、大数据、数据挖掘和数据库系统等领域,是世界领先的研究学者,擅长为数据密集型应用设计开发创新性的数据业务产品和高效的数据分析技术。2017 年 07 月 01 日至 2021 年 06 月 30 日期间,裴健担任 ACM SIGKDD 主席。
他是国际计算机协会(ACM)院士和国际电气电子工程师协会(IEEE)院士,ACM SIGKDD(数据挖掘及知识发现专委会)现任主席。因其在数据挖掘基础、方法和应用方面的杰出贡献,裴健曾获得数据科学领域技术成就最高奖 ACM SIGKDD Innovation Award(ACM SIGKDD 创新奖)和 IEEE ICDM Research Contributions Award(IEEE ICDM 研究贡献奖)。
裴健于 2002 年在加拿大西蒙弗雷泽大学获计算科学博士学位, 于 1991 年和 1993 年分别于上海交通大学计算机科学与工程系获学士与硕士学位。
在此,祝贺裴健教授获得加拿大皇家科学院院士这一荣誉。新智元此前对裴健教授进行过专访,我们再次将采访内容呈现,更多地了解这位学者。
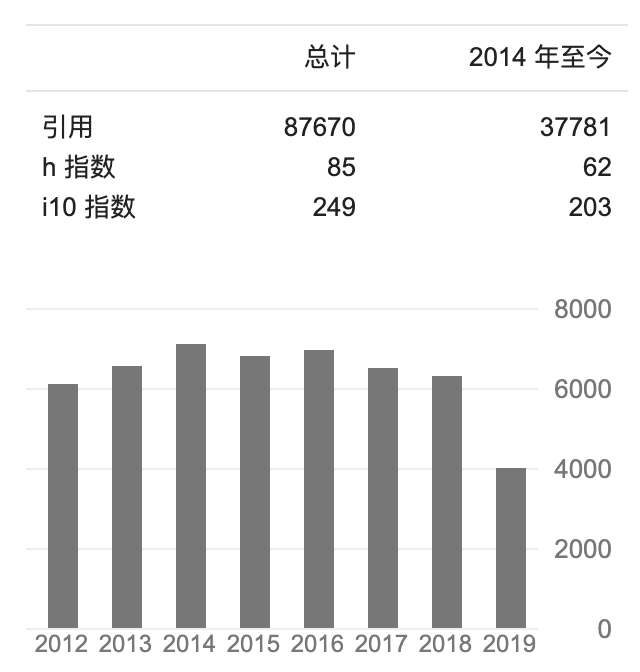
在数据挖掘、数据库系统和信息检索方面,裴健是学术界被引用次数最多的作者之一。自 2000 年以来,他在国际顶级学术期刊与会议上发表二百多篇论文,被引用超过八万七千次。
不过,裴健对于学术十分谦虚。
他说:“每篇论文发表之后就会留下遗憾,因为总有可以改进的地方。回头看,对自己的每篇论文我都能说出自己的遗憾。与其选自己最满意的论文,还不如说自己最常有的遗憾。 我经常遗憾对一个问题的本质认识不足,忽略了更简洁的算法,对别的领域不够了解,未能借用别的领域已有的技术和方法。”
数据挖掘其实是一个非常跨学科的领域,与众多学科相互促进,共同发展。以人工智能和机器学习为例,可以结合的点非常多。对于这种跨界的合作,裴健教授对新智元介绍说:“我和机器学习的专家合作很多,自己也可以滥竽充数地说懂一点机器学习。我在数据库、数据挖掘、机器学习和信息检索多个领域都做一点,和不同的学者合作,从他们身上学到不同的东西,如不同的思维方式和领域知识,收益非浅。多跟不同的人合作是很有帮助的。”
KDD 领域近年来向机器学习靠拢的趋势很明显。从大会评选出的最佳论文,以及组织举办的 Workshop 就能够看出,话题与实际应用结合非常紧密,keynote 演讲里还有专门请投资人从 VC 视角讲解机器学习。
那么,这算是一个大趋势吗?
裴健教授在接受新智元的专访时表示,机器学习本身就是数据挖掘的一个重要工具,20 年前数据挖掘创始的时候的三大主要内容就包括机器学习。机器学习与数据密不可分,数据挖掘是打通从数据到业务的端到端流程。
再具体到深度学习,裴健说:“深度学习最近的发展很 Disruptive。在数据挖掘领域,很多工作用深度学习作为工具。KDD 上有很多文章提出了很有趣的问题,然后用深度学习作为工具巧妙地解决了问题。建议感兴趣的读者去浏览一下今年来的 KDD 论文集。”
人工智能的发展很大程度上依赖于数据的获取,有人曾说,如果人工智能是火箭,数据就是燃料,从你在数据挖掘多年的经历来看,怎样才能获得高效的、优质的 “燃料”,确保火箭不会出事?现在深度学习领域出现了各种各样的数据集,数据的量非常大,在图像领域就出现了比著名的 Imagenet 要大很多的数据库,那么,是不是数据永远是越大越好?对于研究者来说,怎样才算是适合的数据?
在 “数据” 上有着多年研究经验的裴健对新智元介绍说:“一般来说,数据是越多越好。深度学习需要大量的数据来产生可以 generalize 的模型。在实际应用中,数据往往是有成本的。有很多应用场景不容易获取大量的高质量数据。所以说我们需要针对具体问题,获取合适的数据。在这方面,统计学对数据的采集评价有一系列的方法和原则,值得深入学习。另一个方面,要很好利用大量的数据,通常需要比较复杂的模型,对计算的要求也相应地比较高,所以我们要根据数据量和应用来选择合适的模型。”
提到大数据和好数据,人工智能发展的另一个前沿方向就是能减少数据依赖,实现无监督学习。裴健认为,无监督学习的一个难点在于其没有绝对的评价标准。例如病人可以按病因、症状、并发症、风险等很多方面进行分群。因此,无监督学习的一个难点就是如何形成合适的类别,特别是结合问题的上下文,如常识,去形成合理有意义的类别。
采访的最后,新智元提到,最近 “程序员自动化” 的讨论比较多,那么在数据发现和挖掘领域,是不是也可以实现 “自动化”,由机器来完成数据的挖掘工作?裴健表示,数据挖掘就是致力于数据的挖掘工作自动化。这是我们数据挖掘领域专家正在努力做的。
加拿大皇家学会2019新科院士名单列表:
https://rsc-src.ca/sites/default/files/Class%20of%202019.pdf




