KDD 2019 | 一文详解微软亚洲研究院7篇精选论文
编者按:KDD 2019于8月4-8日在美国阿拉斯加州的安克雷奇举行。本届大会上,微软亚洲研究院有多篇论文入选,内容涉及在线预测任务、 在线影响力最大化、AI金融、推荐系统、异常检测等多个前沿领域。本文将为大家介绍其中有代表性的7篇论文。
下周一(8月12日),我们还将邀请论文作者为大家在线深度解读其中一篇,直播信息详见文末海报。
DeepGBM: A Deep Learning Framework Distilled by GBDT for Online Prediction Tasks
论文链接:https://dl.acm.org/citation.cfm?id=3330858
在线预测任务是在实践中常见的任务,如点击率预测、推荐系统等。在这些任务里面,数据有如下两个重要特性:第一是包含大量的表格特征,既有稀疏的离散类别特征,如用户 ID、商品类别等,又有稠密的连续数值特征,如用户年龄、商品价格等;第二是这些数据会在实际业务场景中实时增加,且分布可能会随时间发生变化。
而目前广泛用于这些任务的机器学习模型都没有完美适配这两个重要的特性。常用的机器学习模型大致可分为三类:梯度提升树(GBDT)、神经网络(NN)和二者(GBDT+NN)结合的模型。其中 GBDT 可以很好地处理连续的数值特征,但很难处理好稀疏的类别特征,并且 GBDT 是利用全量数据学习的,很难高效地进行在线更新;而 NN(如Wide&Deep、DeepFM等)虽然可以用 embedding 技术处理好稀疏类别特征,且可以高效地在线更新,但其难以很好地处理数值特征;常见的 GBDT+NN 方法会单独使用 GBDT 再使用 NN,但同样由于 GBDT 的缘故,难以在线更新。综上,其特点对比如表1所示:

表1:不同机器学习模型之间对比
本文提出了 DeepGBM 的端对端模型,结合 GBDT 和 NN 的优势。DeepGBM 主要包含两个子模块——面向类别特征的 CatNN 和面向数值特征的 GBDT2NN。CatNN 主要继承了 NN 中对类别特征友好的 Deep 模块和 FM 模块;GBDT2NN 是文章最主要的贡献之一,其基于 GBDT 进行知识蒸馏构造了一个 NN 模块,可以有效地处理类别特征并可以在线更新。综上,DeepGBM 既支持含有类别特征和数值特征的表格型数据输入,还能利用实时产生的数据进行学习和更新,其基本框架如图1所示:
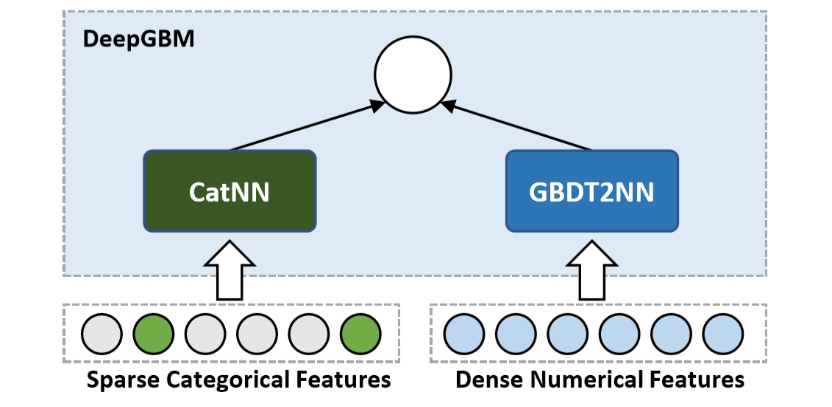
图1:DeepGBM模型框架
GBDT2NN 主要包含了3个部分:特征选择、结构蒸馏和决策树输出,其数学形式表达和大致框架如下所示:
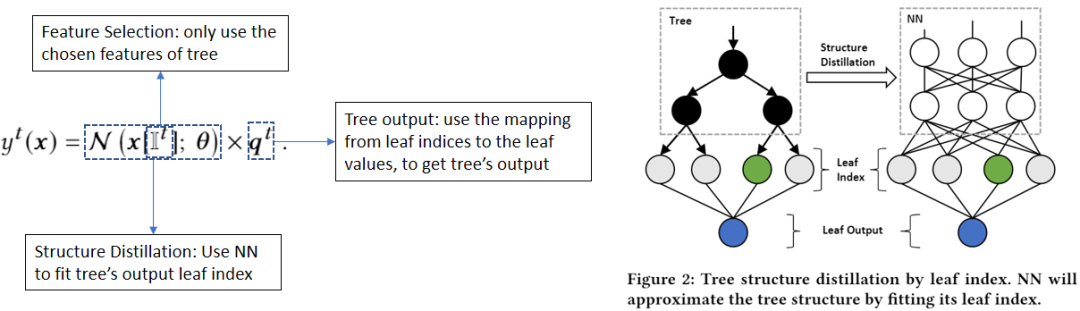
图2:GBDT2NN 数学形式表达(左)和框架(右)
考虑到 GBDT 中远不止一棵树,且每棵树的叶子数量很多,这样一个 NN 对应一棵树的转化代价太大。因此,我们引入 Tree Grouping 和 Leaf Embedding Distillation 的技术。具体来说,我们先将树进行分组,在每一组里面先把稀疏离散的叶子索引输出映射到稠密的 embedding,再把这个 embedding 作为蒸馏的目标,如图3所示。结合这两个技术,可以大大降低蒸馏多棵树的代价。
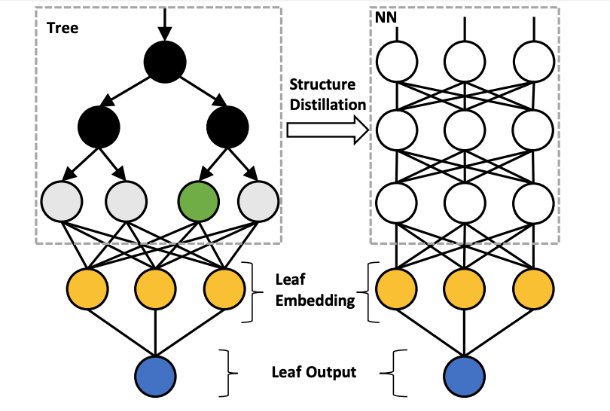
图3:使用Leaf Embedding Distillation进行结构蒸馏
该论文使用了7个数据集来验证 DeepGBM 模型的效果。离线实验和在线实验的结果分别如表2和图4所示。离线实验表明:1)基于 GBDT 的模型较 NN 模型有更好的表现;2)GBDT2NN 在 GBDT 的基础上还有一定提升;3)DeepGBM 的表现比所有的基线模型都要好。在线实验表明:DeepGBM 契合在线场景,且效果比所有的基线模型都要好。
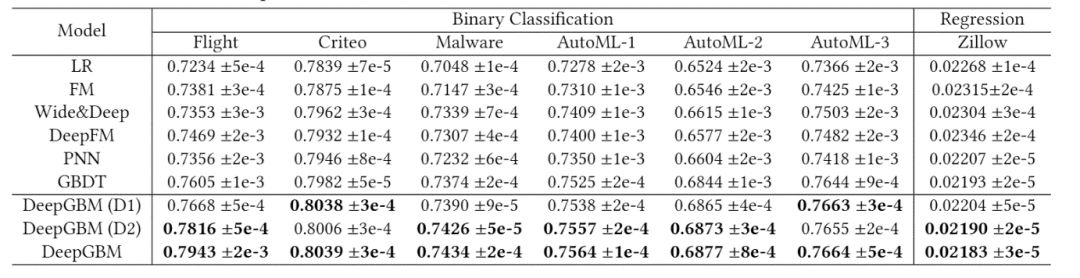
表2:DeepGBM 模型的离线实验结果
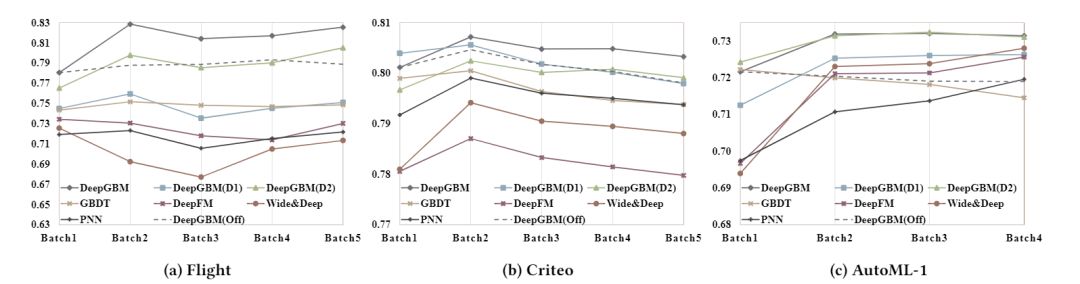
图4:DeepGBM 模型的在线实验结果
目前,这项工作已经在 GitHub 上开源。
GitHub 地址:https://github.com/motefly/DeepGBM
Factorization Bandits for Online Influence Maximization
论文链接:https://arxiv.org/abs/1906.03737
影响力最大化(influence maximization)是在一个社交网络中找到少数种子结点使得从种子结点出发传播达到范围最大的优化问题。但是传播过程是一个随机过程,由网络中每个边上的参数决定,而这些参数需要从传播数据中学习得到。在线影响力最大化(online influence maximization)就是在网络中反复优化和学习相结合的迭代过程:每一轮我们选出一个种子集合,观察这些从种子集合出发的传播过程,通过传播反馈更新边上的参数,再用更新过的参数选取新的种子集合作为下一轮最大化的起始结点,使得在多轮传播中总的效果最好。
之前的工作将每个边作为独立的参数进行学习,这导致参数过多,学习过程较慢。在本文中,我们依据社会科学研究中提出的人际影响力主要由发出方的影响因子(influence factor)和接收方的易感因子(susceptibility factor)联合决定的思想,将每个结点建模为两个低维的向量,一个对应于影响因子,一个对应于易感因子,而从结点 u 到结点 v 的有向边的影响力参数就是 u 的影响因子与 v 的易感因子的点积。基于这一模型,我们给出了在线影响力最大化的学习和优化方法,我们称之为因子分解老虎机(factorization bandit)方法。我们给出了如何从观察数据反推结点的影响因子和易感因子的方法和估计参数置信度的方法,并由此给出了算法遗憾度的理论分析。通过实验,我们验证了该算法比已有算法能更快地学习,从而在同样轮次内达到更好的影响力效果。
Individualized Indicator for All: Stock-wise Technical Indicator Optimization with Stock Embedding
论文链接:https://dl.acm.org/citation.cfm?id=3330833
在金融市场的风险决策中,金融特征因子是通过对过去一段时间内市场价格的进行数学运算而形成的,它们往往能反映对应股票的一系列特征,从而对构建金融投资策略起到重要的作用。然而我们发现不同股票对于同一个金融特征因子的亲和度往往是不同的,也就是说即使两个股票拥有相同的金融特征因子的数值,这并不意味着它们此刻的状态是相同的。如图5所示,对于两只不同的股票(ID 601558和ID 000892),即使在特征因子bias-in-30-days上拥有同样的值(例如-0.1),但对两只股票来讲,含义是非常不同的。
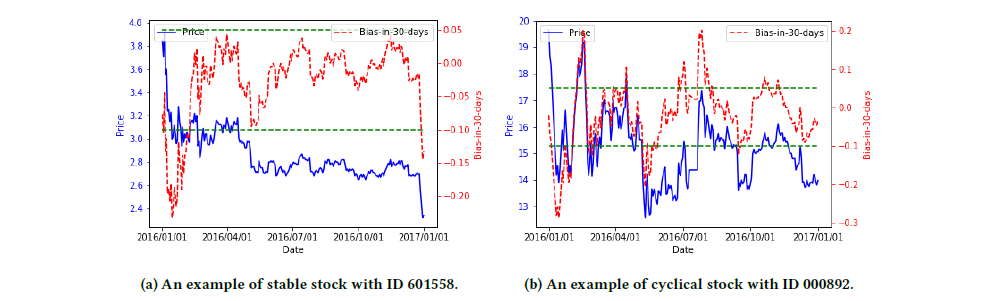
图5:拥有相同特征因子的不同股票的市场表现
为此,我们提出了一个针对金融特征因子的优化模型,它能够根据不同的股票性质去对原始的金融特征因子进行相应地调整优化,使得优化后的因子能够更准确地反映股票此时的状态和特征。为了得到对于每支股票性质的合理表示方法,我们注意到基金经理们对于股票有自己的偏好,例如有的更喜欢投资稳定股,有的更喜欢投资成长股。
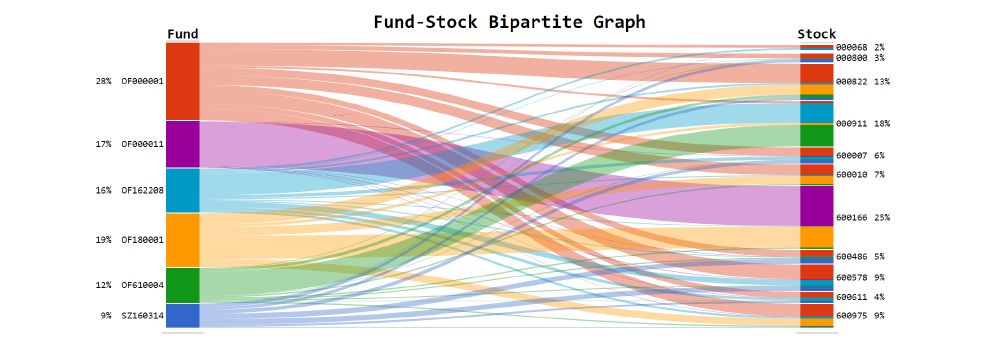
图6:基金经理与投资股票的二分图
所以我们认为,被相同基金经理投资的股票之间会具有相似的性质,从而可以从基金经理们的行为模式中学习得到股票的性质的表达方式。因此,我们将过去时间内基金经理们对股票的投资构建出一个二分图(如图6),其中点表示为基金和股票,边表示投资的份额。然后我们通过图嵌入的算法得到股票的向量表达方式。最后通过一个神经网络模型,以股票的向量表征方式和原始的因子作为输入,学习出优化后的因子数值。实验证明,相比于原始特征因子而言,优化后的因子对于金融投资具有更好的借鉴意义。
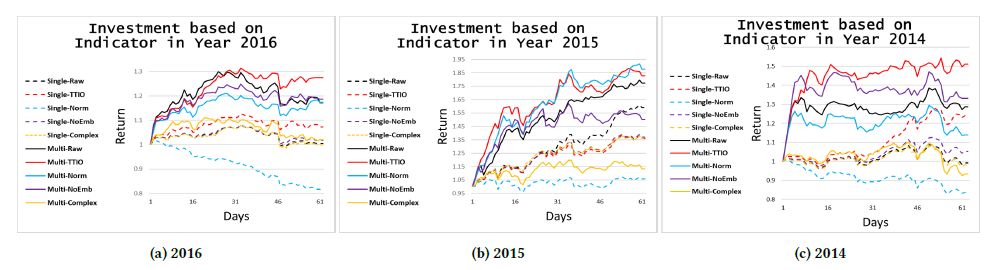
图7:不同投资策略导致的累计收益在不同年份之间的对比图
Investment Behaviors Can Tell What Inside: Exploring Stock Intrinsic Properties for Stock Trend Prediction
论文链接:https://www.kdd.org/kdd2019/accepted-papers/view/investment-behaviors-can-tell-what-inside-exploring-stock-intrinsic-propert
随着计算机技术的快速发展,量化分析逐渐成为了一项重要的投资参考。股市专家们根据基本面、技术面和实时新闻等信息推断股票价格从而实现利润最大化。为了快速计算和发掘新的价格波动模式,大量的研究者尝试使用各种各样的机器学习模型来预测股票。尽管如此,相比于已有的模型,股票专家投资仍然能够获得较好的投资回报。其中的原因之一是股市专家通过长时间的学习和观察对股票的本质特征有着专业的理解,而这些本质特征却很难被清晰的表述出来。基于上述原因,本文主要聚焦于发掘股票的这些本质特征并将其用于改进已有的股票预测模型。
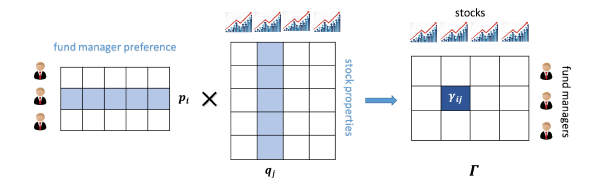
图8:对投资者的行为偏好进行建模
事实上,投资者的行为偏好透露了其对股票本质的理解(如图8建模)。比如,有些投资者偏好成长型股票,有些偏好周期型股票;有些投资者更了解重工业,而有些更多地投资了高新技术。基于这样的情景,我们尝试从投资者的投资行为中学习股票的本质特征。
由于基金经理是一群特殊的金融投资专家,他们对股票的理解更加专业;而且根据相关规定,他们的投资方案会定期公布,这有利于数据的采集和学习。因此本文使用基金经理的投资数据来发掘股票的本质特征。接下来,为了能够将相对静态的股票本质特征应用到频繁波动的价格预测,本文提出了一种新的框架来改进已有的股价预测模型,从而实现特征输出同步。
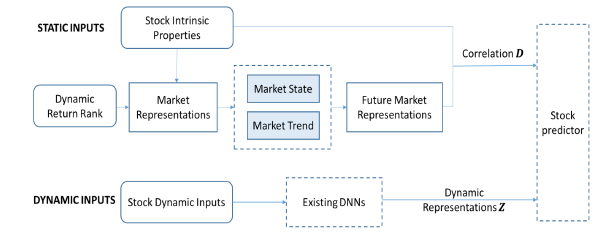
图9:股价预测模型新框架
LambdaOpt: Learn to Regularize Recommender Models in Finer Levels
论文链接: https://arxiv.org/abs/1905.11596
推荐系统经常涉及大量的类别型变量,例如用户、商品 ID 等,这样的类别型变量通常是高维、长尾的——头部用户的行为记录可能多达百万条,而尾部用户则仅有几十条记录。这样的数据特性使得我们在训练推荐模型时容易遭遇数据稀疏的问题,因而适度的模型正则化对于推荐系统来说十分重要。正则化超参的调校十分具有挑战性。常用的网格搜索需要消耗大量计算资源,且通常无法顾及更细粒度的正则化。针对推荐模型和推荐数据集的特性,我们提出了一种新的、更加细粒度的自动正则化超参选择方案 λOpt。
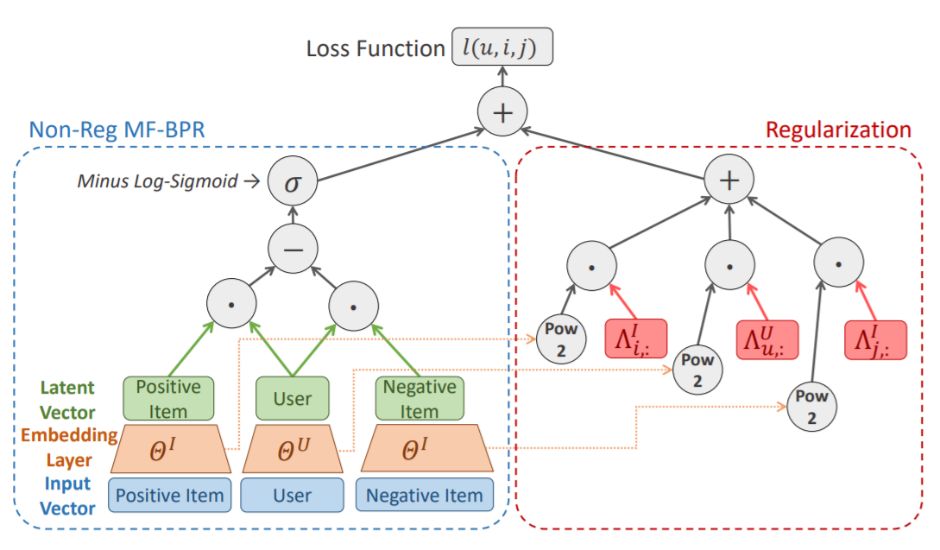
图10:细粒度正则化的 MF-BPR 为每个用户、商品、维度选择合适的正则化超参
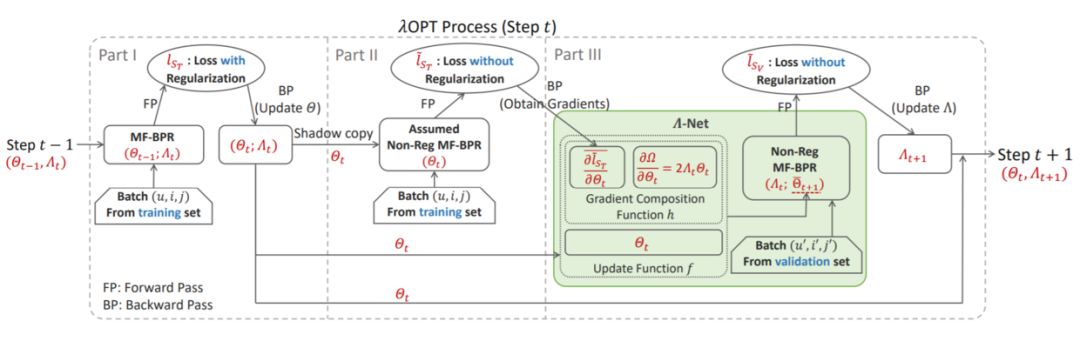
图11:λOpt 整体流程
除了正常的模型更新之外,在每一步迭代中,λOpt 基于验证集的表现调整正则化超参:1)在训练集上,预估使用当前超参 Λ 进行一步模型更新后的模型参数 Θ ̅_(t+1)。为了实现更便捷的自适应细粒度正则化,λOpt 以目前流行的自动求导框架为基础,将梯度拆分为未正则化与正则化两部分分别计算;2)在验证集上,求解图12所示约束优化问题。考虑到方法的通用性,λOpt 采用了一个单独的网络 Λ-Net 来更新Λ。
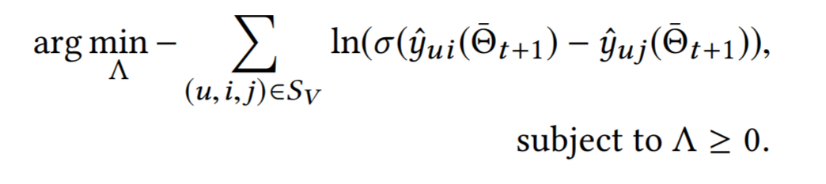
图12:基于预估的模型参数,最小化验证集上的损失函数
我们在矩阵分解模型上展示了如何使用 λOpt 来进行细粒度超参的选择。在 Amazon Food Review 和 MovieLens 10M 两个数据集上,考虑用户+商品+维度的细粒度正则化后,λOpt 可以同时照顾到不同频率的用户、商品,显著提高推荐性能(如表3所示)。
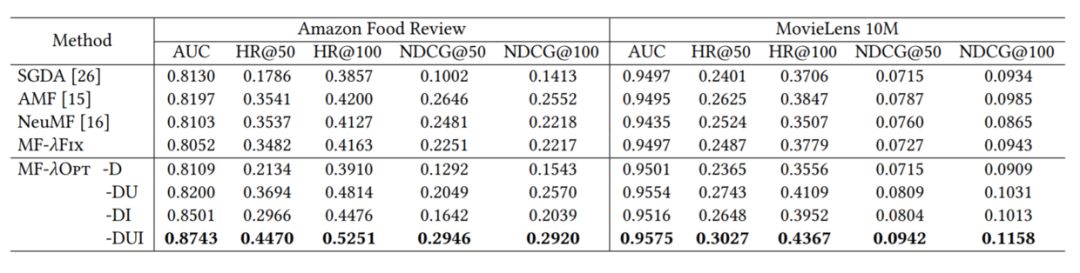
表3:λOpt的性能表现
NPA: Neural News Recommendation with Personalized Attention
论文链接:https://arxiv.org/pdf/1907.05559.pdf
每天都有大量用户在微软新闻等在线新闻平台阅读电子新闻,然而,面对互联网上每天都在产生的海量新闻,用户从中逐个寻找感兴趣的内容是不现实的。因此,新闻推荐是在线新闻平台的一项重要任务。可以帮助用户找到他们感兴趣的新闻文章,并减轻信息过载。在浏览新闻时,不同的用户通常具有不同的兴趣,并且对于同一篇新闻,不同的用户往往会关注其不同方面。然而已有的新闻推荐方法往往无法建模不同用户对同一新闻的兴趣差异。
该论文提出了一种 neural news recommendation with personalized attention(NPA) 模型,可在新闻推荐任务中应用个性化注意力机制来建模用户对于不同上下文和新闻的不同兴趣。该模型的核心是新闻表示、用户表示和点击预估。
在新闻表示模块中,我们基于新闻标题学习新闻表示。新闻标题中的每个词语先被映射为词向量,之后我们使用 CNN 来学习词语的上下文表示,最后通过词语级的注意力网络选取重要的词语,构建新闻标题的表示。
在用户表示模块中,我们基于用户点击的新闻来学习用户的表示。由于不同新闻表示用户具有不同的信息量,我们应用新闻级的注意力网络选取重要的新闻文章,构建用户的表示。
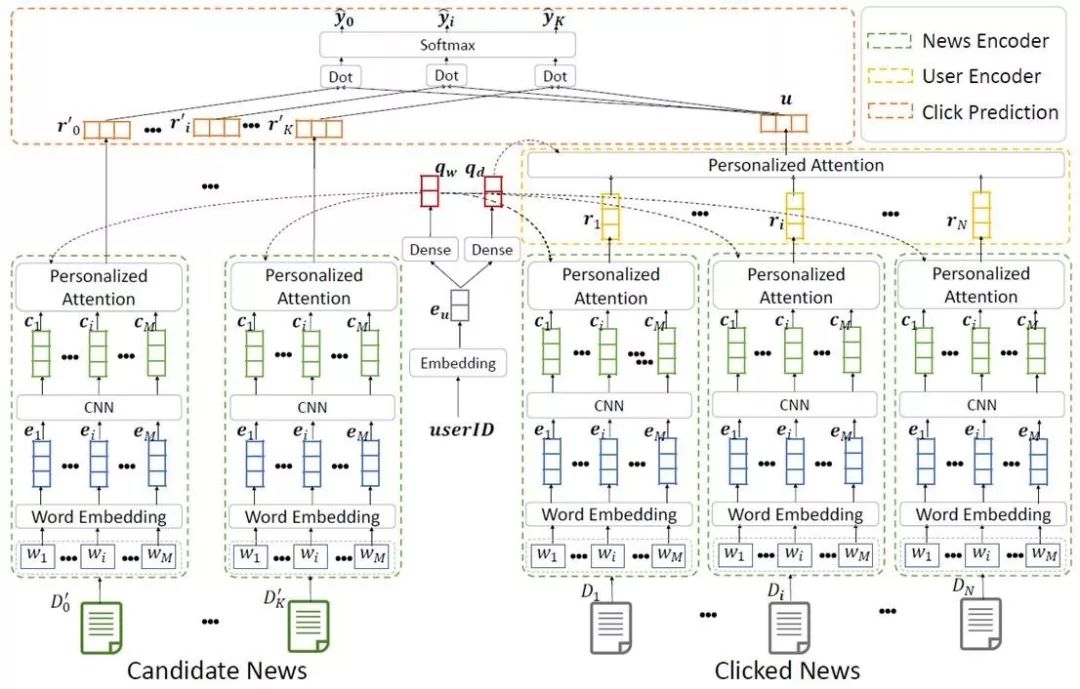
图13:NPA 模型的架构
另外,相同的新闻和词语可能对表示不同的用户具有不同的信息量。因此,我们提出了一种个性化的注意力网络,其利用用户 ID 的嵌入向量来生成用于词和新闻级注意的查询向量其结构如图14所示。
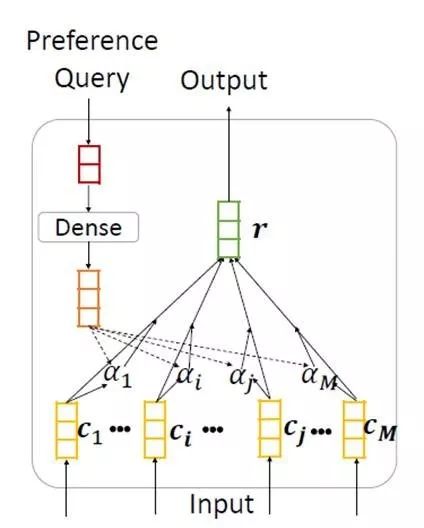
图14:个性化注意力网络的结构
最终候选新闻的点击预估分数通过用户和新闻表示向量之间的内积计算,作为对用户进行个性化新闻推荐时的排序依据。
该论文在微软新闻推荐的真实数据集上进行了实验,并和一系列基线方法进行了对比,结果如表4所示。
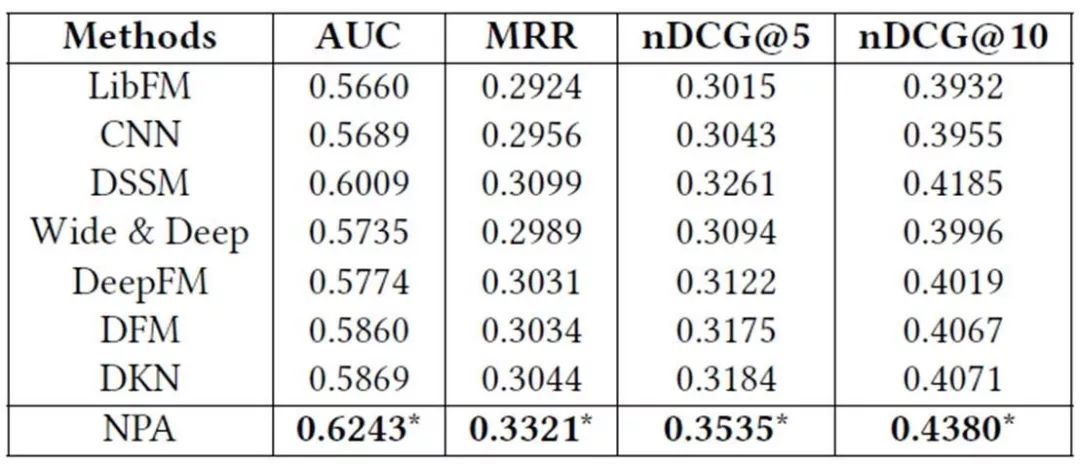
表4:不同模型在微软新闻推荐数据集上的实验结果。*相对基线方法的改进显著水平为 p <0.001。
实验结果表明,应用个性化注意力机制能够有效地提升新闻个性化推荐的效果,因此该论文提出的方法在多个指标上一致地优于基线方法。
Time-Series Anomaly Detection Service at Microsoft
论文链接:https://arxiv.org/abs/1906.03821
时序数据的异常检测在实际生产环境中有着重要且广泛的应用,包括业务指标、DevOps 数据以及 IOT Sensor 数据的监控等。及时地发现异常可以有效降低企业成本,增加服务的稳定性。构建一个准确并实用的异常检测算法主要有以下几点挑战:1)缺乏标注:在系统中有百万级别的时间序列,我们很难对每种类型的数据进行足够的标注;2)泛化:时间序列的模式多种多样,产品要求算法对各式各样的时间序列具备很好的泛化能力;3)效率:线上服务对算法的执行效率有较高要求,一些复杂的模型虽然精度不错,但效率达不到产品的要求。
在微软内部,AI Platform of Cloud+AI 产品组构建了一个异常检测平台,应用于包括 Azure、Office 以及必应在内的多个产品组,同时在微软认知服务上提供 API 供外部客户使用。我们针对该产品面临的挑战,发明了一种准确、高效的异常检测算法,带来了显著的效果提升。
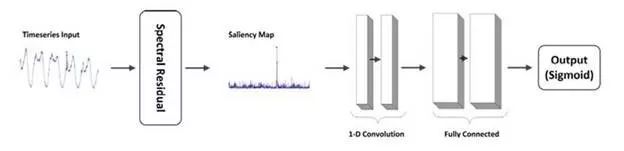
图15:异常检测算法示意图
算法示意如图15所示。一个时间序列输入首先经过 Spectral Residual(SR) 模块。SR 是一种基于傅里叶变换的非监督模型,在视觉显著性领域取得了非常好的效果。经过 SR 变换的时间序列被称为 Saliency Map,在此基础之上,我们应用了一个额外的 CNN 网络输出预测结果。我们首次在时间序列异常检测问题中迁移使用了 SR 模型,该方法显著地提升了 SOTA 的精度。同时,我们首次将 SR 与 CNN 相结合,进一步改进了 SR 的性能(评测如表5所示)。在我们的应用中,CNN 可以由完全虚构的数据训练,从而解决了数据标注的问题。
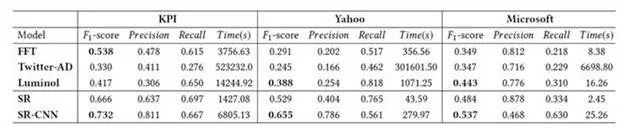
表5:SR 性能评测结果
API说明:
https://azure.microsoft.com/en-us/services/cognitive-services/anomaly-detector/
开源代码:https://github.com/microsoft/anomalydetector





