用迁移学习创造的通用语言模型ULMFiT,达到了文本分类的最佳水平
编者按:这篇文章作者是数据科学家Jeremy Howard和自然语言处理专家Sebastian Ruder,目的是帮助新手和外行人更好地了解他们的新论文。该论文展示了如何用更少的数据自动将文本分类,同时精确度还比原来的方法高。本文会用简单的术语解释自然语言处理、文本分类、迁移学习、语言建模、以及他们的方法是如何将这几个概念结合在一起的。如果你已经对NLP和深度学习很熟悉了,可以直接进入项目主页,查看相关技术信息:nlp.fast.ai/category/classification.html
简介
5月14日,我们发表了论文Universal Language Model Fine-tuning for Text Classification(ULMFiT),这是一个预训练模型,同时用Python进行了开源。论文已经经过了同行评议,并且将在ACL 2018上作报告。上面的链接提供了对论文方法的深度讲解视频,以及所用到的Python模块、与训练模型和搭建自己模型的脚本。

这一模型显著提高了文本分类的效率,同时,代码和与训练模型能让每位用户用这种新方法更好地解决以下问题:
找到与某一法律案件相关的文件;
辨别垃圾信息、恶意评论或机器人回复;
对商品积极和消极的评价进行分类;
对文章进行政治倾向分类;
其他
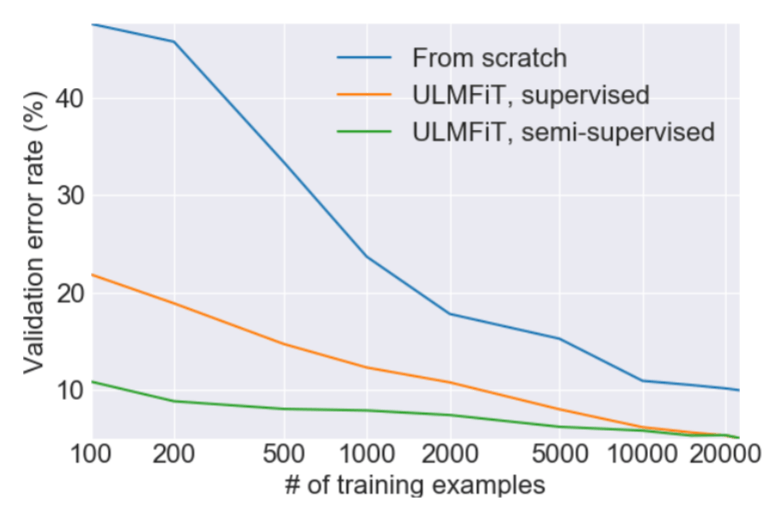
ULMFiT所需的数量比其他方法少
所以,这项新技术到底带来了哪些改变呢?首先让我们看看摘要部分讲了什么,之后在文章的其他部分我们会展开来讲这是什么意思:
迁移学习为计算机视觉带来了巨大改变,但是现有的NLP技术仍需要针对具体任务改进模型,并且从零开始训练。我们提出了一种有效的迁移学习方法,可以应用到NLP领域的任何一种任务上,同时提出的技术对调整语言模型来说非常关键。我们的方法在六种文本分类任务上比现有的技术都要优秀,除此之外,这种方法仅用100个带有标签的样本进行训练,最终的性能就达到了从零开始、拥有上万个训练数据的模型性能。
NLP、深度学习和分类
自然语言处理是计算机科学和人工智能领域的特殊任务,顾名思义,就是用计算机处理世界上的语言。自然语言指的是我们每天用来交流的话语,例如英语或中文,与专业语言相对(计算机代码或音符)。NLP的应用范围十分广泛,例如搜索、私人助理、总结等等。总的来说,由于编写的计算机代码很难表达出语言的不同情感和细微差别,缺少灵活性,就导致自然语言处理是一项非常具有挑战性的任务。可能你在生活中已经体验过与NLP打交道的事了,例如与自动回复机器人打电话,或者和Siri对话,但是体验不太流畅。
过去几年,我们开始看到深度学习正超越传统计算机,在NLP领域取得了不错的成果。与之前需要由程序定义一系列固定规则不同,深度学习使用的是从数据中直接学到丰富的非线性关系的神经网络进行处理计算。当然,深度学习最显著的成就还是在计算机视觉(CV)领域,我们可以在之前的ImageNet图像分类竞赛中感受到它快速的进步。
深度学习同样在NLP领域取得了很多成功,例如《纽约时报》曾报道过的自动翻译已经有了许多应用。这些成功的NLP任务都有一个共同特征,即它们在训练模型时都有大量标记过的数据可用。然而,直到现在,这些应用也只能用于能够收集到大量带标记的数据集的模型上,同时还要求有计算机群组能长时间计算。
深度学习在NLP领域最具挑战性的问题正是CV领域最成功的问题:分类。这指的是将任意物品归类到某一群组中,例如将文件或图像归类到狗或猫的数据集中,或者判断是积极还是消极的等等。现实中的很多问题都能看作是分类问题,这也是为什么深度学习在ImageNet上分类的成功催生了各类相关的商业应用。在NLP领域,目前的技术能很好地做出“识别”,例如,想要知道一篇影评是积极还是消极,要做的就是“情感分析”。但是随着文章的情感越来越模糊,模型就难以判断,因为没有足够可学的标签数据。
迁移学习
我们的目标就是解决这两个问题:
在NLP问题中,当我们没有大规模数据和计算资源时,怎么办?
让NLP的分类变得简单
研究的参与者(Jeremy Howard和Sebastian Ruder)所从事的领域恰好能解决这一问题,即迁移学习。迁移学习指的是用某种解决特定问题的模型(例如对ImageNet的图像进行分类)作为基础,去解决与之类似的问题。常见方法是对原始模型进行微调,例如Jeremy Howard曾经将上述分类模型迁移到CT图像分类以检测是否有癌症。由于调整后的模型无需从零开始学习,它所能达到的精度要比数据较少、计算时间较短的模型更高。
许多年来,只使用单一权重层的简单迁移学习非常受欢迎,例如谷歌的word2vec嵌入。然而,实际中的完全神经网络包含很多层,所以只在单一层运用迁移学习仅仅解决了表面问题。
重点是,想要解决NLP问题,我们应该从哪里迁移学习?这一问题困扰了Jeremy Howard很久,然而当他的朋友Stephen Merity宣布开发出AWD LSTM语言模型,这对语言建模是重大进步。一个语言模型是一个NLP模型,它可以预测一句话中下一个单词是什么。例如,手机内置的语言模型可以猜到发信息时下一步你会打哪个字。这项成果之所以非常重要,是因为一个语言模型要想正确猜测接下来你要说什么,它就要具备很多知识,同时对语法、语义及其他自然语言的元素有着非常全面的了解。我们在阅读或分类文本时也具备这种能力,只是我们对此并不自知。
我们发现,将这种方法应用于迁移学习,有助于成为NLP迁移学习的通用方法:
不论文件大小、数量多少以及标签类型,该方法都适用
它只有一种结构和训练过程
它无需定制特殊的工程和预处理
它无需额外的相关文件或标签
开始工作
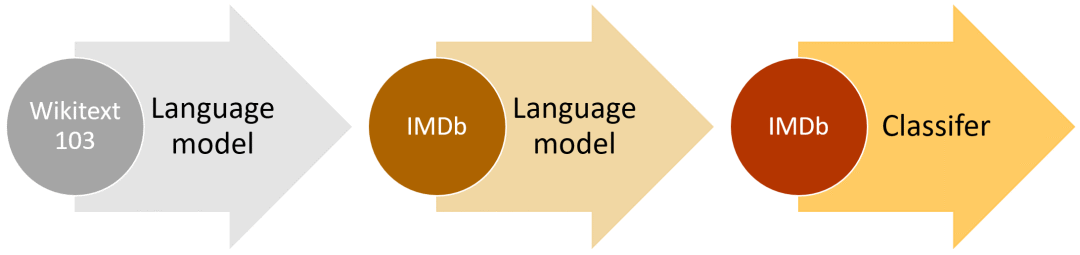
ULMFiT的高层次方法(以IMDb为例)
这种方法之前曾尝试过,但是为了达到合格的性能,需要上百万个文本。我们发现,通过调整语言模型,就能达到更好的效果。特别是,我们发现如果仔细控制模型的学习速度,并更新预训练模型以保证它不会遗忘此前所学内容,那么模型可以在新数据集上适应得更好。令人激动的是,我们发现模型能够在有限的样本中学得更好。在含有两种类别的文本分类数据集上,我们发现将我们的模型在100个样本上训练达到的效果和从零开始、在10000个标记样本上训练的效果相同。
另外一个重要的特点是,我们可以用任何足够大且通用的语料库建立一个全球通用的语言模型,从而可以针对任意目标语料进行调整。我们决定用Stephen Merity的WikiText 103数据集来做,其中包含了经过与处理的英文维基百科子集。
NLP领域的许多研究都是在英文环境中的,如果用非英语语言训练模型,就会带来一系列难题。通常,公开的非英语语言数据集非常少,如果你想训练泰语的文本分类模型,你就得自己收集数据。收集非英语文本数据意味着你需要自己标注或者寻找标注者,因为类似亚马逊的Mechanical Turk这种众筹服务通常只有英文标注者。
有了ULMFiT,我们可以非常轻松地训练英语之外的文本分类模型,目前已经支持301种语言。为了让这一工作变得更容易,我们未来将发布一个模型合集(model zoo),其中内置各种语言的预训练模型。
ULMFiT的未来
我们已经证明,这项技术在相同配置下的不同任务中表现得都很好。除了文本分类,我们希望ULMFiT未来能解决其他重要的NLP问题,例如序列标签或自然语言生成等。
计算机视觉领域迁移学习和预训练ImageNet模型的成功已经转移到了NLP领域。许多企业家、科学家和工程师目前都用调整过的ImageNet模型解决重要的视觉问题,现在这款工具已经能用于语言处理,我们希望看到这一领域会有更多相关应用产生。
尽管我们已经展示了文本分类的最新进展,为了让我们的NLP迁移学习发挥最大作用,还需要很多努力。在计算机视觉领域有许多重要的论文分析,深度分析了迁移学习在该领域的成果。Yosinski等人曾试着回答:“深度神经网络中的特征是如何可迁移的”这一问题,而Huh等人研究了“为什么ImageNet适合迁移学习”。Yosinski甚至创造了丰富的视觉工具包,帮助参与者更好地理解他们计算机视觉模型中的特征。如果你在新的数据集上用ULMFiT解决了新问题,请在论坛里分享反馈!
原文地址:nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html
项目地址:nlp.fast.ai/category/classification.html






