ResNet到底在解决一个什么问题呢?
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货

Resnet到底在解决一个什么问题呢?
https://www.zhihu.com/question/64494691/answer/220989469
 到了
到了
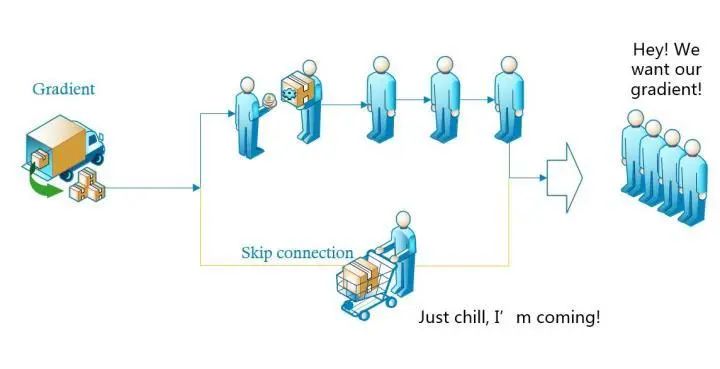
 )。这一点其实也很好理解,从梯度流来看,有一路梯度是保持原样不动地往回传,这部分的相关性是非常强的。
)。这一点其实也很好理解,从梯度流来看,有一路梯度是保持原样不动地往回传,这部分的相关性是非常强的。
https://www.zhihu.com/question/64494691/answer/271335912
https://www.zhihu.com/question/64494691/answer/786270699
一、引言:为什么会有ResNet?Why ResNet?
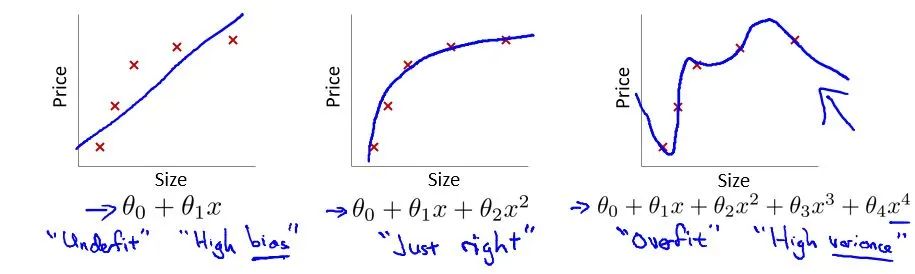
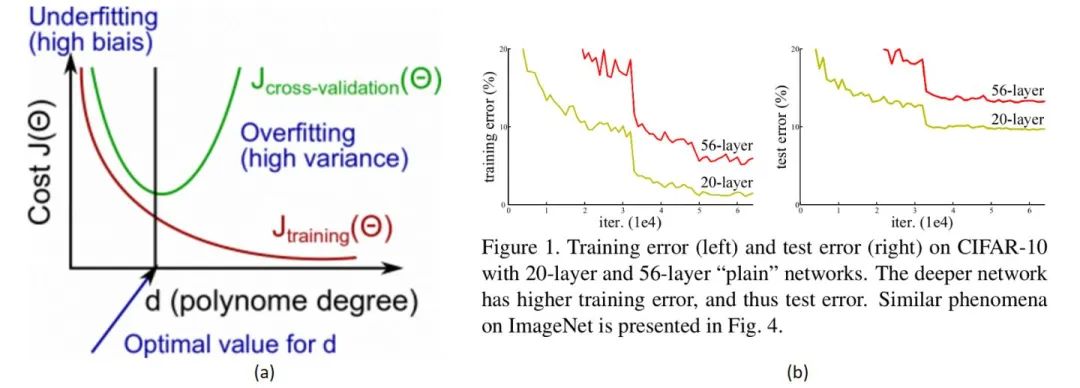
1. 过拟合?Overfitting?
2. 梯度爆炸/消失?Gradient Exploding/Vanishing?
 ,
,
 ,
,
 ,
,
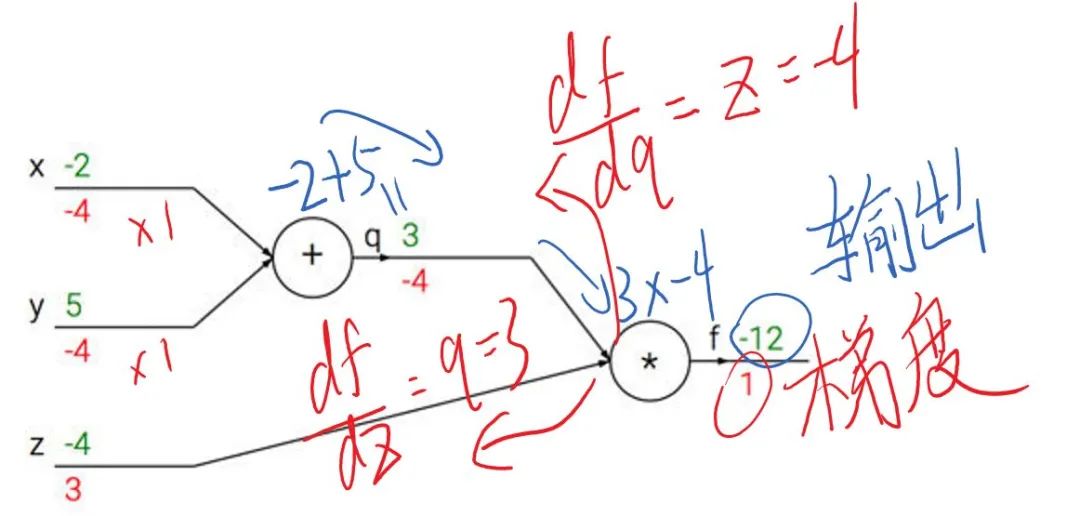
 在时的梯度,那么首先可以做出如下所示的计算图。
,
,
带入,其中,令
在时的梯度,那么首先可以做出如下所示的计算图。
,
,
带入,其中,令
 ,一步步计算,很容易就能得出
,一步步计算,很容易就能得出
 。
。
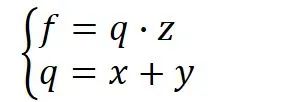
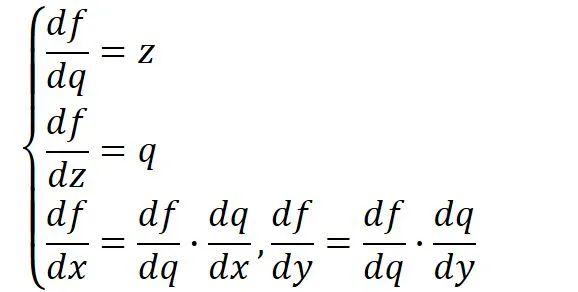
3. 为什么模型退化不符合常理?

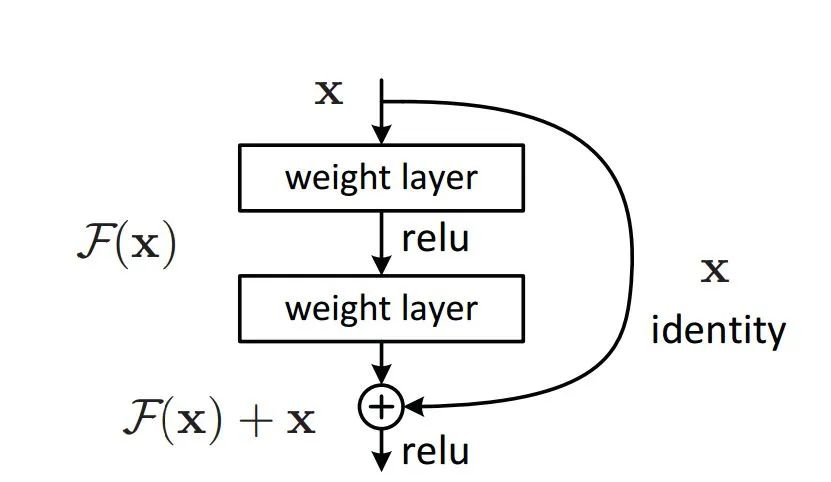
二、深度残差学习 Deep Residual Learning
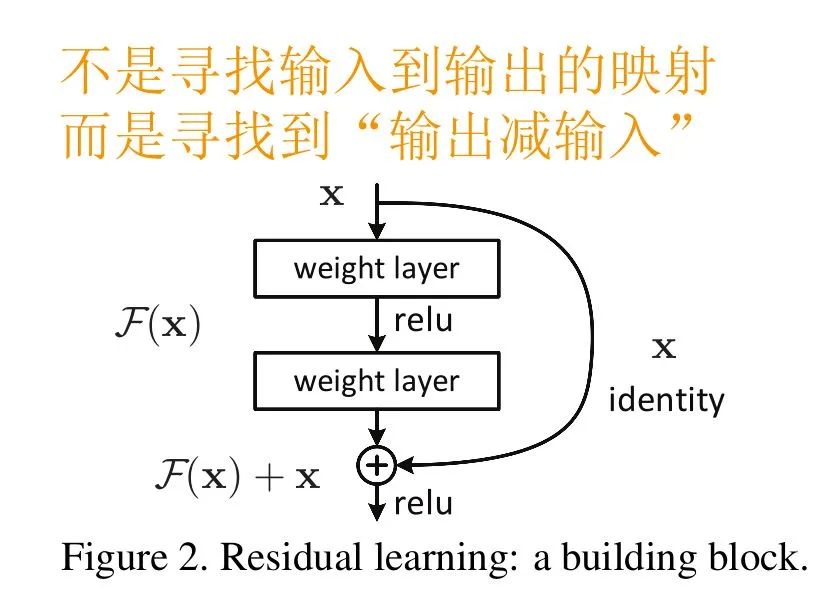
 ,则输出
,则输出
 等于:
等于:
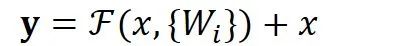
 是我们学习的目标,即输出输入的残差
是我们学习的目标,即输出输入的残差
 。以上图为例,残差部分是中间有一个Relu激活的双层权重,即:
。以上图为例,残差部分是中间有一个Relu激活的双层权重,即:
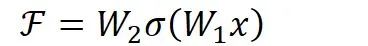
 指代Relu,而
指代Relu,而
 指代两层权重。
指代两层权重。
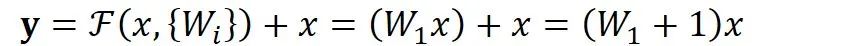
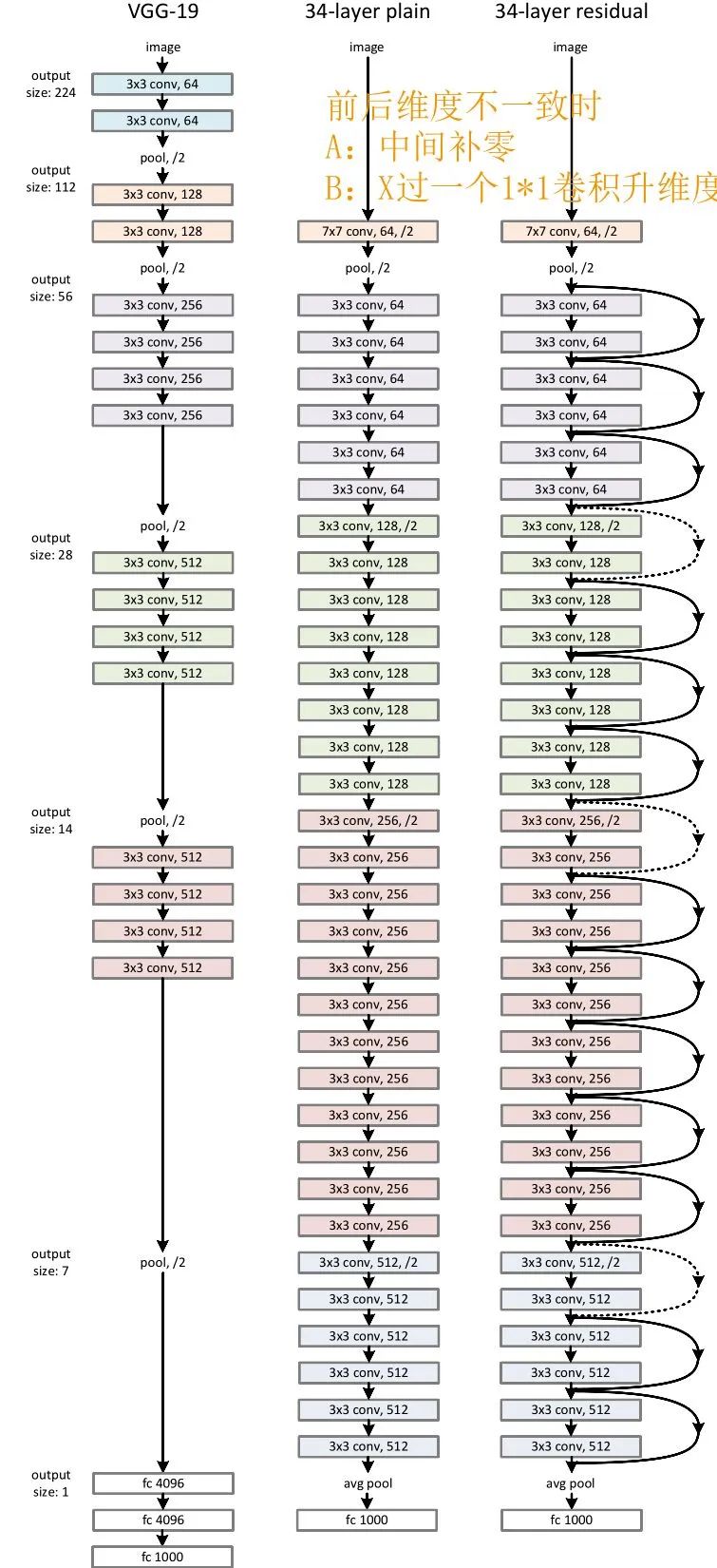
空间上不一致
深度上不一致
 ,即:
,即:
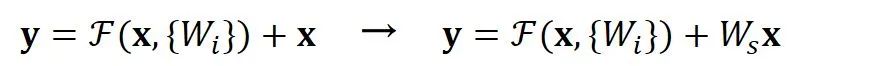
3. torchvision中的官方实现
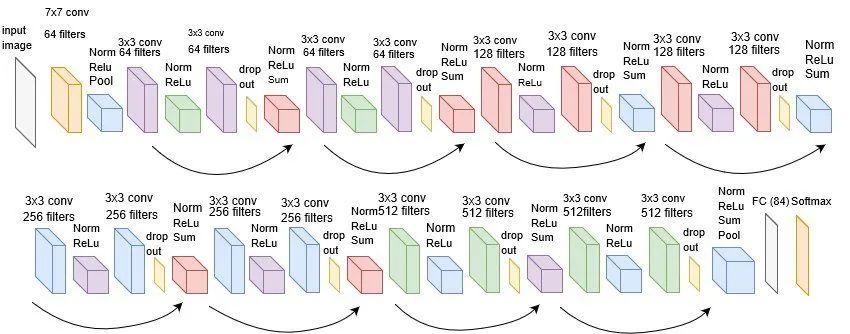
import torchvision
model = torchvision.models.resnet18(pretrained=False) #我们不下载预训练权重
print(model)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
薰风说 Thinkings
 层的网络来说,没有残差表示的Plain Net梯度相关性的衰减在
,而ResNet的衰减却只有
。这也验证了ResNet论文本身的观点,网络训练难度随着层数增长的速度不是线性,而至少是多项式等级的增长(如果该论文属实,则可能是指数级增长的)
层的网络来说,没有残差表示的Plain Net梯度相关性的衰减在
,而ResNet的衰减却只有
。这也验证了ResNet论文本身的观点,网络训练难度随着层数增长的速度不是线性,而至少是多项式等级的增长(如果该论文属实,则可能是指数级增长的)
参考文献
[2]Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[J]. 2018.
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
给优秀的自己点个赞

登录查看更多
相关内容
Arxiv
4+阅读 · 2019年2月11日
Arxiv
8+阅读 · 2018年11月21日
Arxiv
8+阅读 · 2018年4月26日
Arxiv
8+阅读 · 2018年4月11日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年2月11日
Arxiv
8+阅读 · 2018年11月21日
Arxiv
8+阅读 · 2018年4月26日
Arxiv
8+阅读 · 2018年4月11日