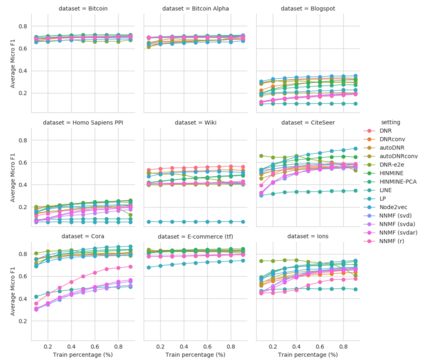
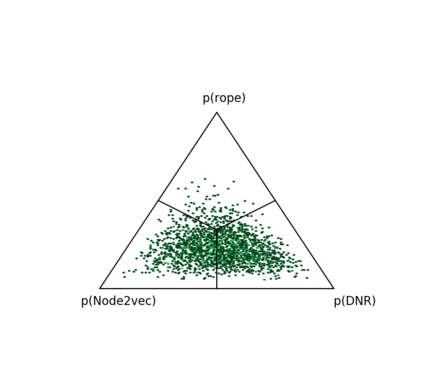
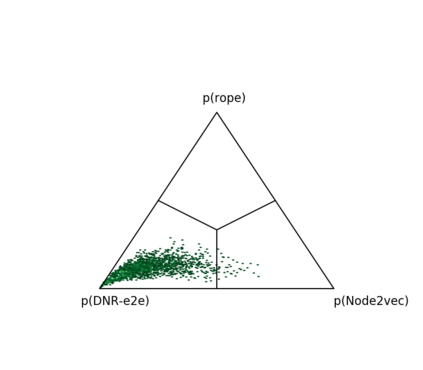
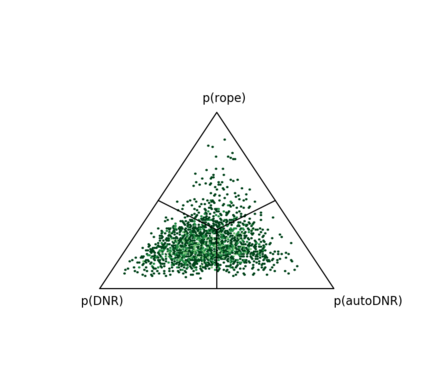
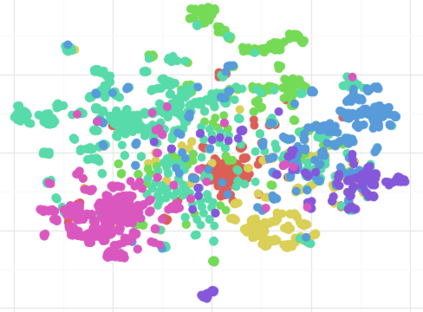
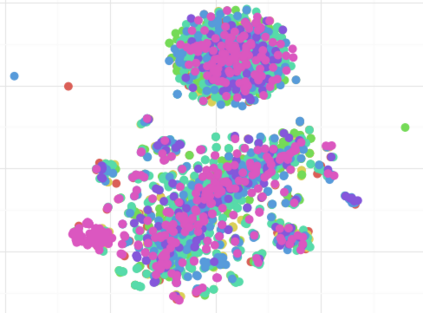
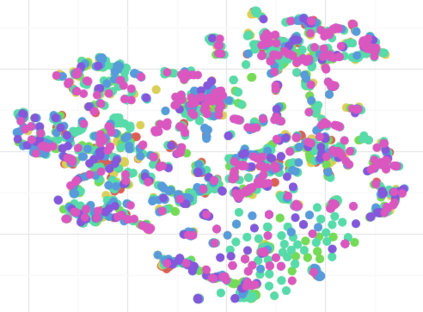
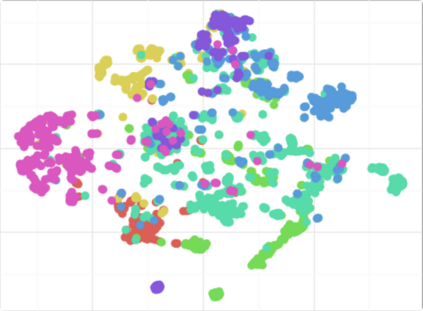
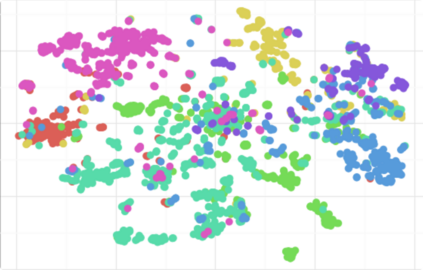
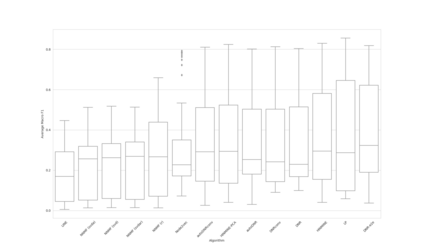
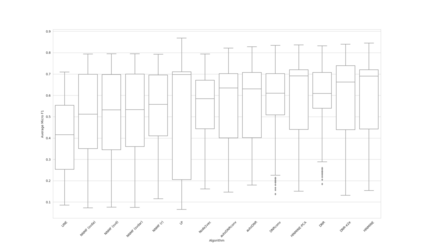
Complex networks are used as an abstraction for systems modeling in physics, biology, sociology, and other areas. We propose an algorithm based on a fast personalized node ranking and recent advancements in deep learning for learning supervised network embeddings as well as to classify network nodes directly. Learning from homogeneous, as well as heterogeneous networks, our algorithm outperforms strong baselines on nine node-classification benchmarks from the domains of molecular biology, finance, social media and language processing---one of the largest node classification collections to date. The results are comparable or better than current state-of-the-art in terms of speed as well as predictive accuracy. Embeddings, obtained by the proposed algorithm, are also a viable option for network visualization.
翻译:复杂网络被用作物理学、生物学、社会学和其他领域系统建模的抽象模型; 我们提出基于快速个人化节点排序和最近深层次学习进展的算法,以学习受监督的网络嵌入,并直接对网络节点进行分类; 从同质和多种网络学习,我们的算法在分子生物学、金融、社交媒体和语言处理等领域的九种节点分类基准上优于强的基线,这是迄今为止最大的节点分类集合之一; 其结果在速度和预测准确性方面比目前最先进的水平可比较或更好; 由拟议的算法获得的嵌入也是网络可视化的一个可行选择。