理论、算法两手抓,UIUC 助理教授孙若愚 60 页长文综述深度学习优化问题
作者:Ruoyu Sun
参与:魔王、杜伟
神经网络何时才算训练成功?成功背后的原因是什么?本文概述了用于训练神经网络的优化算法和理论。


个人主页:https://ise.illinois.edu/directory/profile/ruoyus
论文地址:https://arxiv.org/pdf/1912.08957.pdf
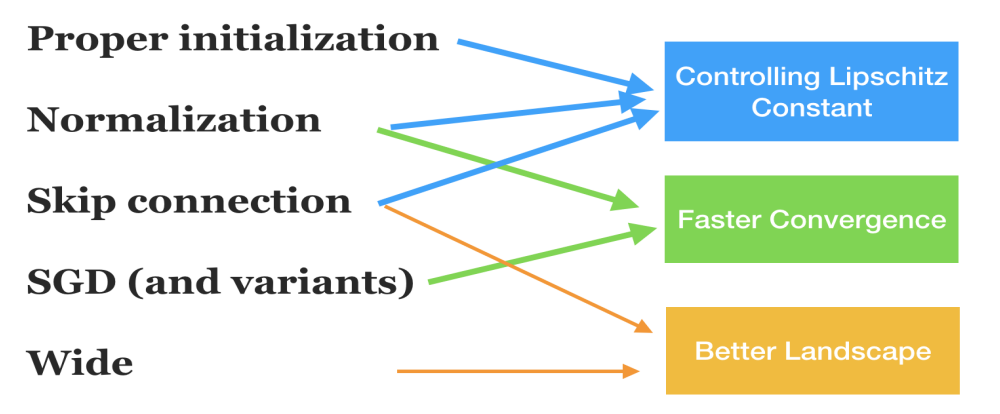
登录查看更多
相关内容

伊利诺伊大学香槟分校(UIUC)工程学院是美国顶尖工程学院之一。其中,计算机系近年来排名稳居全美前五(US News)。根据学术排名权威网站 CSRankings.org,在软件工程方向(根据软件工程四大顶级会议发表情况), UIUC 目前位列全美第一。
专知会员服务
145+阅读 · 2019年12月28日
Arxiv
5+阅读 · 2019年8月27日
Arxiv
4+阅读 · 2019年8月27日



相关VIP内容
专知会员服务
145+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年8月27日
Arxiv
4+阅读 · 2019年8月27日