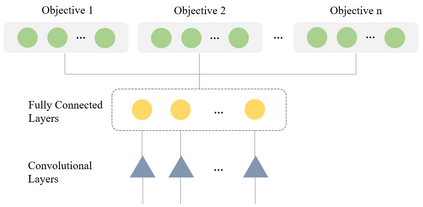
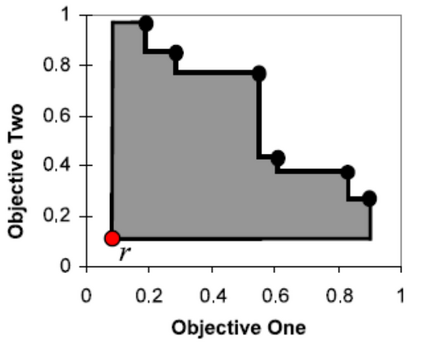
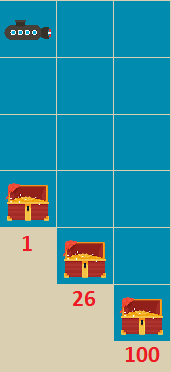
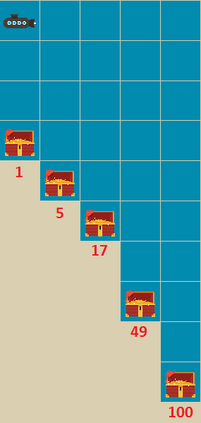
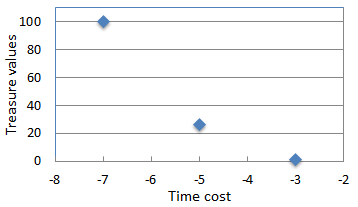
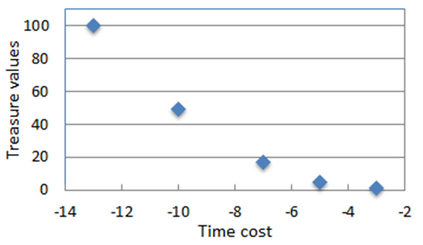
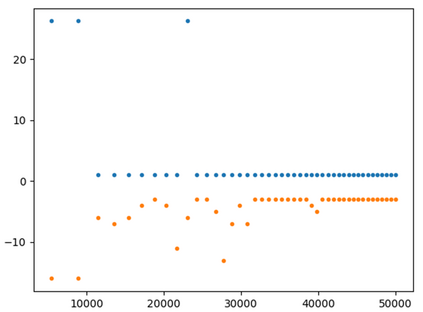
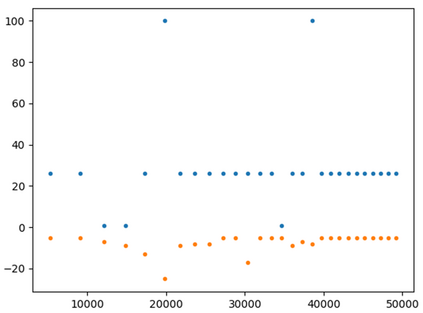
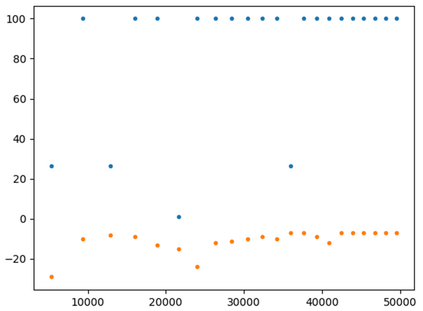
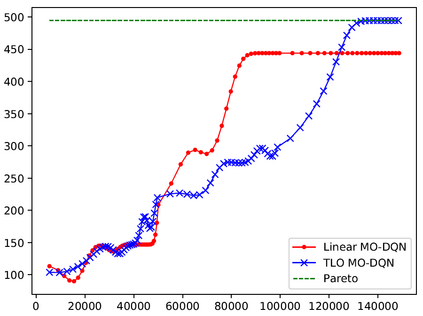
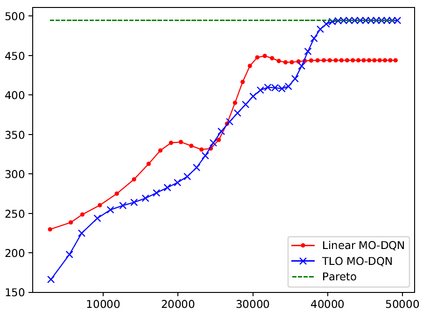
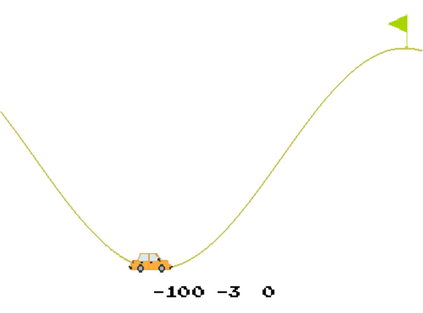
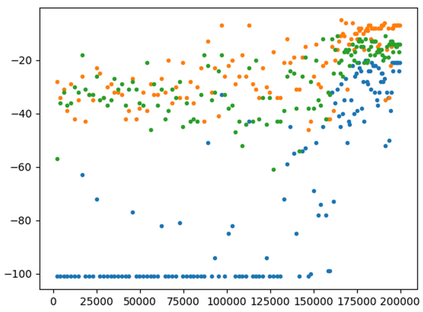
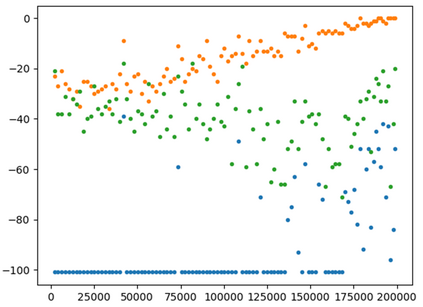
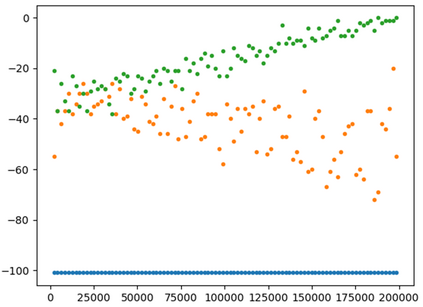
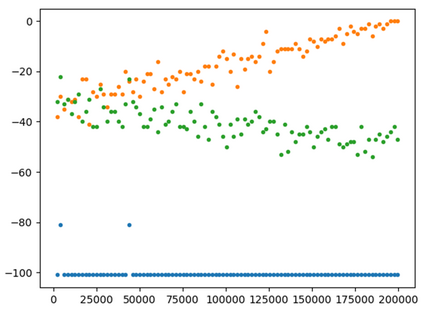
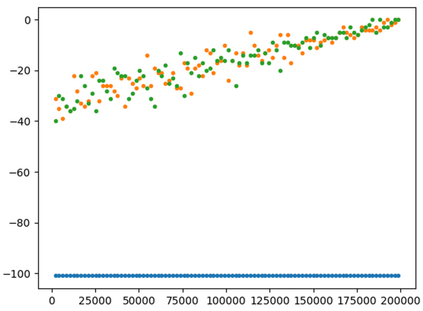
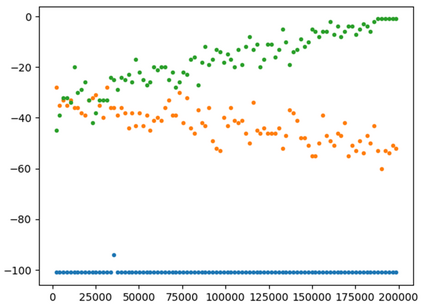
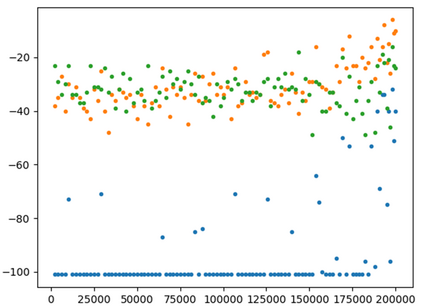
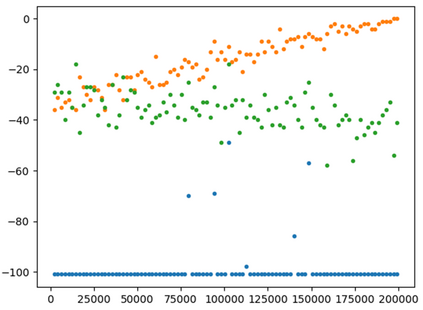
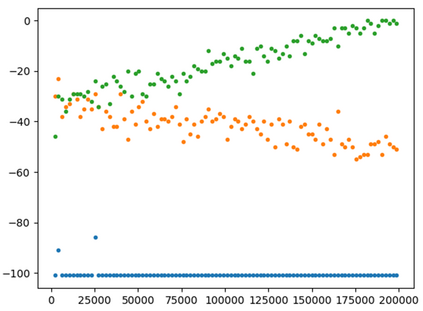
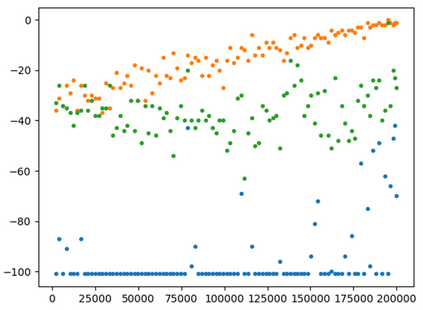
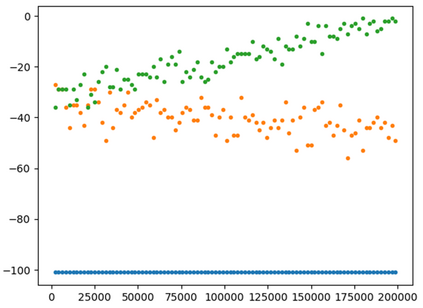
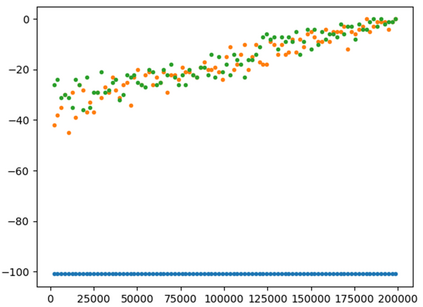
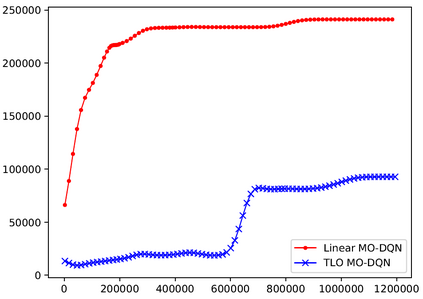
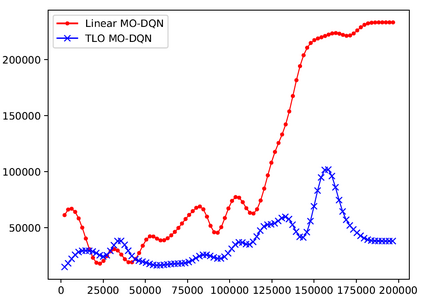
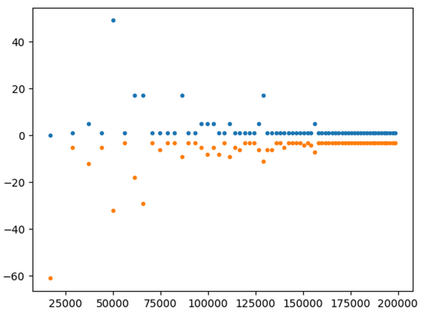
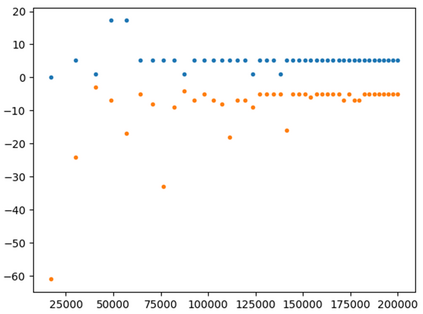
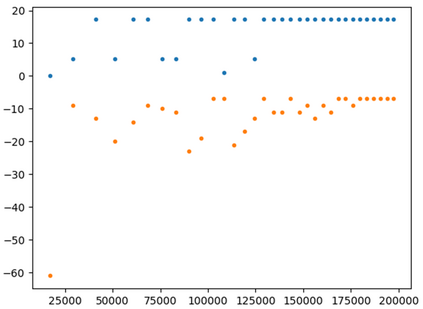
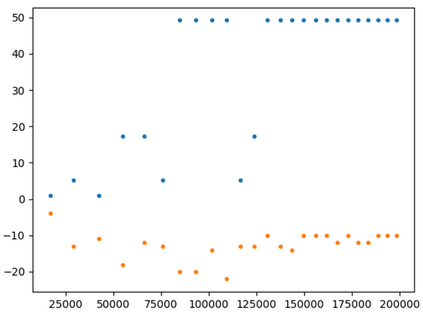
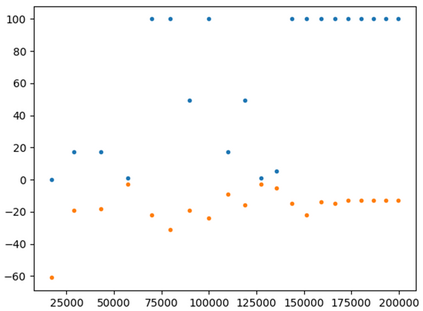
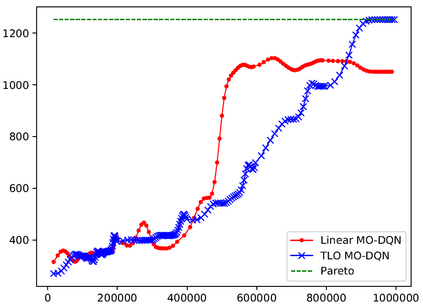
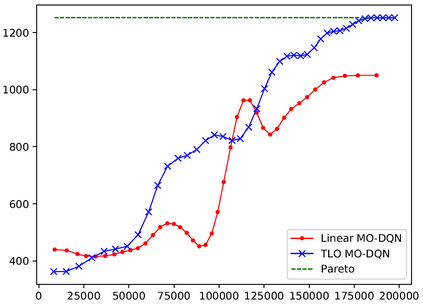
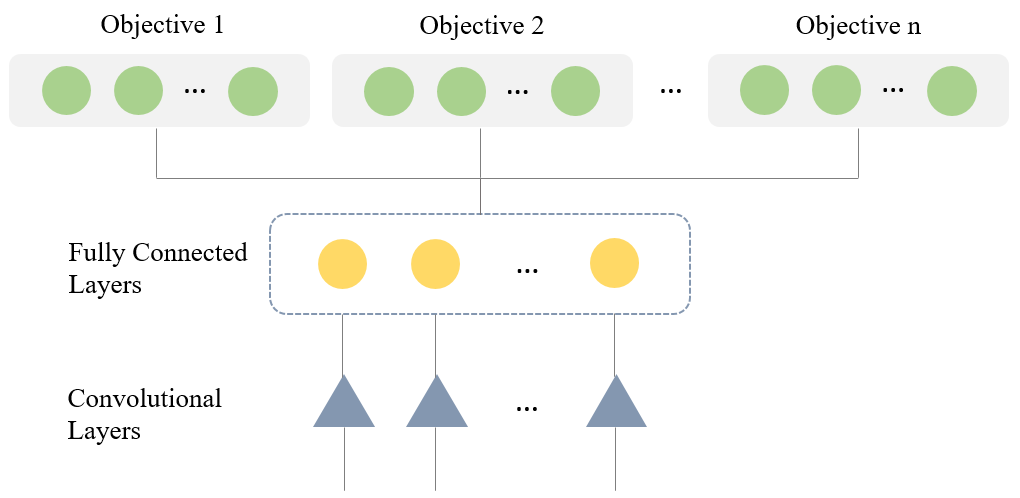
This paper presents a new multi-objective deep reinforcement learning (MODRL) framework based on deep Q-networks. We propose the use of linear and non-linear methods to develop the MODRL framework that includes both single-policy and multi-policy strategies. The experimental results on two benchmark problems including the two-objective deep sea treasure environment and the three-objective mountain car problem indicate that the proposed framework is able to converge to the optimal Pareto solutions effectively. The proposed framework is generic, which allows implementation of different deep reinforcement learning algorithms in different complex environments. This therefore overcomes many difficulties involved with standard multi-objective reinforcement learning (MORL) methods existing in the current literature. The framework creates a platform as a testbed environment to develop methods for solving various problems associated with the current MORL. Details of the framework implementation can be referred to http://www.deakin.edu.au/~thanhthi/drl.htm.
翻译:本文件介绍了基于深层次Q网络的新的多目标深层强化学习(MODRL)框架,我们提议使用线性和非线性方法来制定包含单一政策和多政策战略的MODRL框架,在两个基准问题上的实验结果,包括两个目标深海宝藏环境和三个目标山车问题,表明拟议的框架能够有效地与最佳的Pareto解决方案相融合,拟议的框架是通用的,允许在不同复杂的环境中实施不同的深层强化学习算法,从而克服了当前文献中现有的标准的多目标强化学习(MORL)方法所涉及的许多困难。框架创造了一个平台,作为测试环境,用以制定解决与当前MOL有关的各种问题的方法。 框架执行的详细情况可参见http://www.deakin.edu.au/~thanhthi/drl.htm。