全网最详细!油管1小时视频详解AlphaTensor矩阵乘法算法

新智元报道
新智元报道
【新智元导读】为加速矩阵乘法,DeepMind的AlphaTensor都有什么神操作?1小时超长视频,带你读懂这篇Nature封面。由浅入深,全网最细。
DeepMind前不久发在Nature上的论文Discovering faster matrix multiplication algorithms with reinforcement learning引发热议。
这篇论文在德国数学家Volken Strassen「用加法换乘法」思路和算法的基础上,构建了一个基于AlphaZero的强化学习模型,更高效地探索进一步提高矩阵乘法速度的通用方法。
最近,Youtube播主Yannic Kilcher发布了一个长达近1小时的自制视频,由浅入深地沿着论文的脉络,对这个登上Nature封面的工作进行了解读。
基本思路:用加法换乘法
众所周知,矩阵乘法的传统算法是:两个矩阵行列交换相乘,然后求和,作为新矩阵的对应元素。其中涉及到大量的加法和乘法运算。
对于计算机来说,运算加法的速度要远远快于乘法,所以提升运算速度的关键,就是尽量减少乘法运算的次数,即使为此增加加法运算次数,对于计算加速的效果也是非常明显的。
遵循这个「用加法换乘法」的基本思路,德国数学家Volken Strassen于1969年发现了更高效、占用计算资源更少的矩阵乘法算法。

实际上,这个思路在一些最基础的数学公式中就已经有充分体现。比如平方差公式:
a^2-b^2 =(a+b)*(a-b)
等号左侧计算两次乘法、一次加法,等号右侧计算一次乘法、两次加法。实际上,如果按照多项式乘法对等号右侧展开,实际上发生了正负ab的消去,将乘法运算的次数从4次降低为2次。
Strassen的算法是,利用原矩阵构造一些加乘结合的中间量,每个中间量只包含一次乘法计算,将原矩阵乘法转换为这些中间量的加法运算,将一些符号相反的乘法消去,实现降低乘法运算次数的目的。
在2*2矩阵的乘法中,Strassen的算法将乘法运算次数由8次降为7次。
矩阵乘法的张量表示和低秩分解
那么下一个问题就是,如何找到一种算法,构建能够消去乘法运算的中间量,同时更方便地利用强化学习技术?
DeepMind给出的答案是:将矩阵乘法转换为「低秩分解」问题。
同样以2*2矩阵为例,使用三维张量来表示 AB=C 的矩阵乘法运算过程,其中左右维度(列)为A,上下维度(行)为B,前后维度(深)为C。
用{0,1}对这个表示张量进行填充。C中取到值的部分,填充为1,其余填充为0。如下图所示。
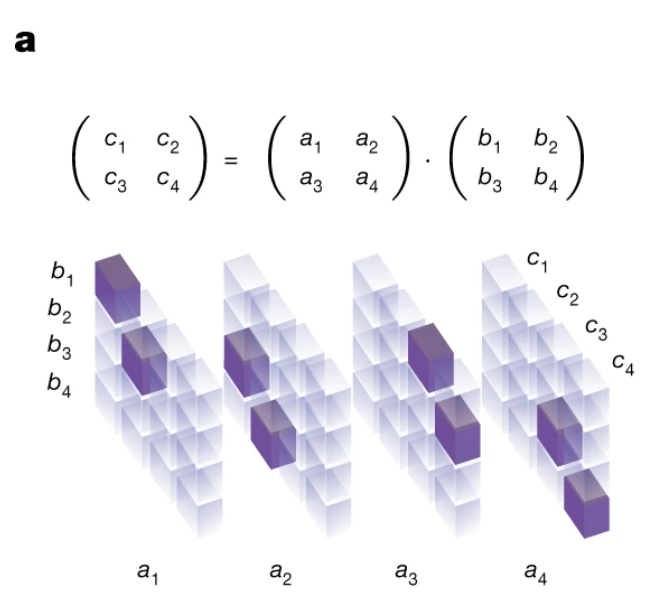
比如,c1=a1*b1+a2*b3,在「最深一层」所表示的c1上,可以看到左上方(第1行第1列)的a1b1,和第3行第2列的a2b3被表示为紫色1,其余为白色0。
在张量表示后,可以通过对矩阵的「低秩分解」,设张量Tn为两个 n×n 矩阵相乘的表示张量。将Tn分解为r个秩一项(rank-one term)的外积。
两个n维向量的外积可以得到一个n×n的矩阵,三个n维向量的外积可以得到一个 n×n×n 的张量。
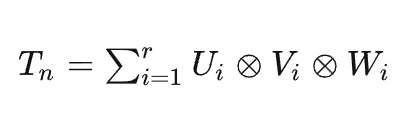
仍以Strassen的算法为例,低秩分解后的结果,即上式中的U、V、W对应为3个7秩矩阵。这里的分解矩阵的秩决定原矩阵乘法中乘法运算的次数。
实际上,用这个方法可以将n×n矩阵乘法的计算复杂度降低至 O(Nlogn(R)) 。
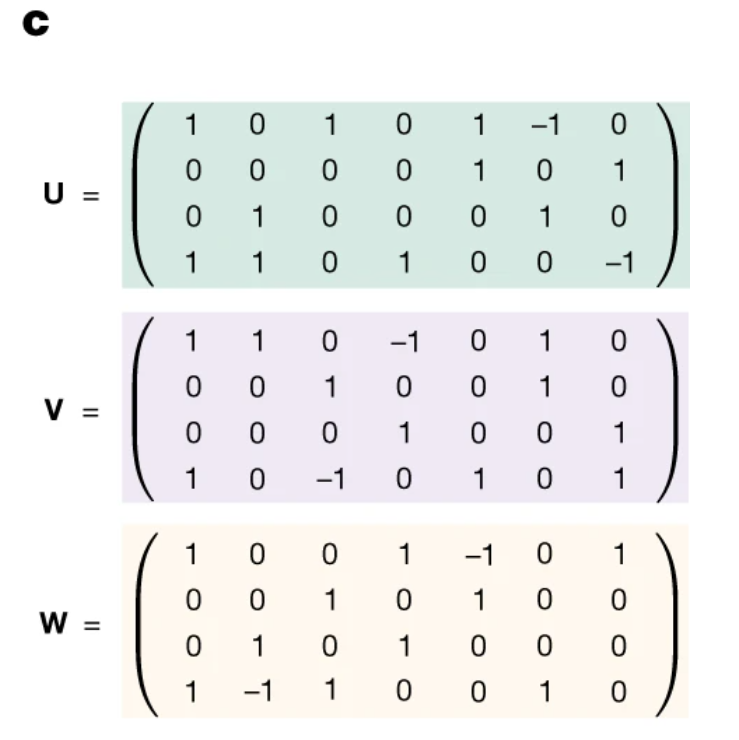
由此可以设计一种规则,一一对应地得到图(b)中的矩阵乘法算法,即论文中的「算法1」:

建模:基于强化学习的AlphaTensor
DeepMind利用强化学习训练了一个AlphaTensor智能体来玩一个单人游戏(Tensor Game),开始时没有任何关于现有矩阵乘法算法的知识。
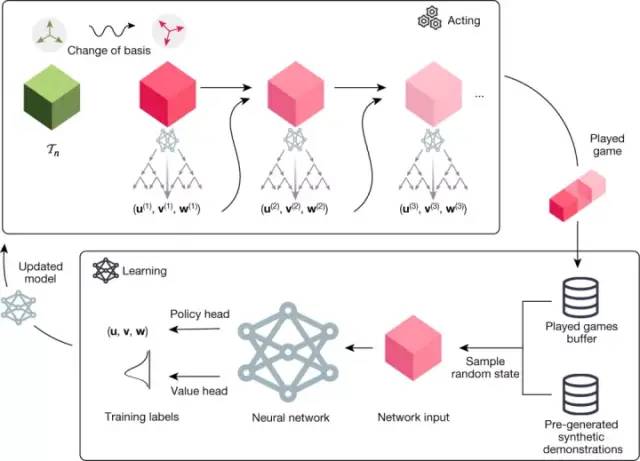
这个强化学习模型正是基于此前的AI围棋大师AlphaZero。
那么这个游戏要如何设计,才能将其与矩阵乘法的简化建立联系,从而解决实际问题呢?
应用AlphaZero时,作者有一些特殊的网络架构技巧。
他们使用了线性代数的某些属性,比如,即使我们改变了线性运算的某些基础,问题也是同样的。因此,即使我们改变了矩阵的基础,它在本质上仍然代表同样的转换。
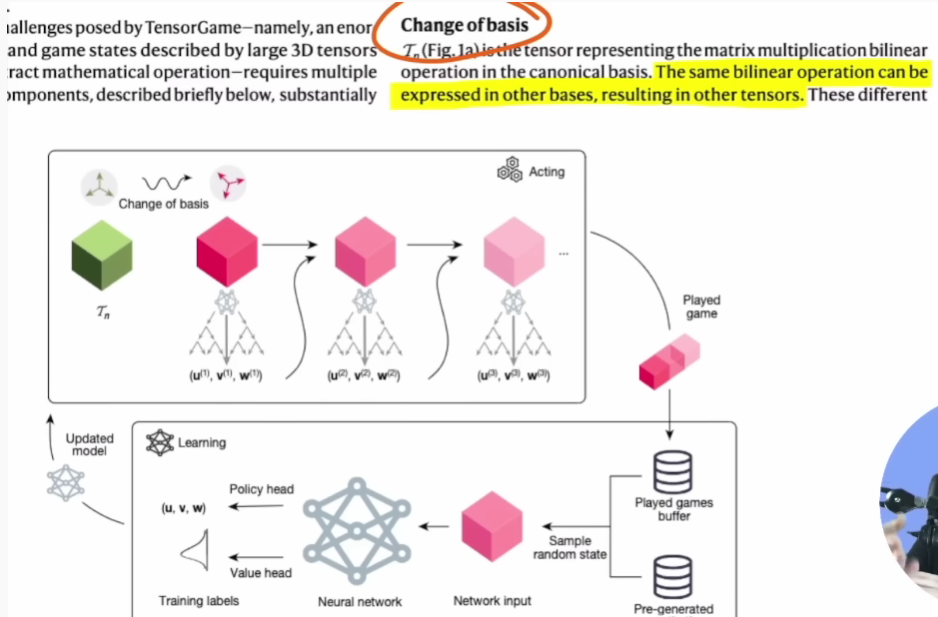
然而,对于这个算法来说,却不是这样的。
有了不同的数字,算法看起来就不同了,因为它是一种对彼此的转换。在这里,作者就很好地利用了线性代数的基本属性,创建出了更多的训练数据。
另外,分解3D张量看起来很难,但创造一个3D张量,就很容易。

我们只需对添加的3个向量进行采样,把它们加在一起,就有了一个三维张量。经过正确的分解,它们还可以创建合成训练数据。
这些技巧都非常聪明,提供了更多的数据给系统。系统经过训练,可以准确地提供这些分解。
让我们分析一下神经网络架构,它是一个基于Transformer的网络。
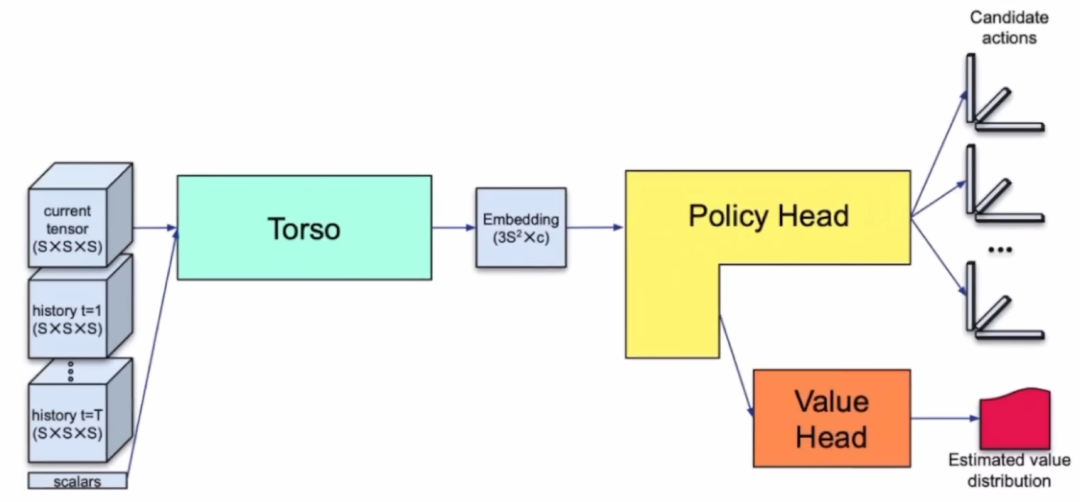
本质上,它是一个强化学习算法。
首先要输入当前的张量以及张量的历史,接着是躯干(Torso),然后是嵌入(Embedding),最后是Policy Head和Value Head。
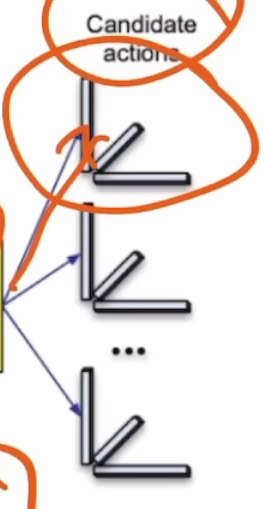
在上图所指的位置,我们要选择三个向量u,v,w,进行相应计算。
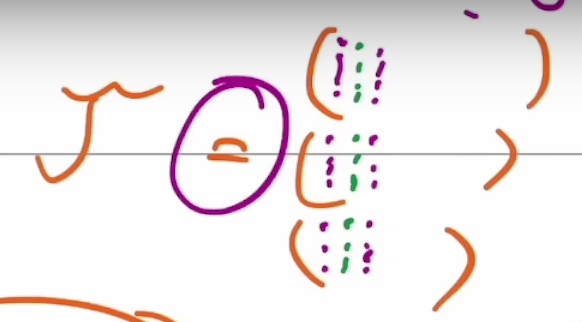
一旦我们有三个向量的动作,我们就可以从原始张量中减去它。然后的目标是,找到从原始张量中减去的下一个动作。所有张量的Entry都是0的时候,游戏正好结束。

这显然是一个离散问题。如果张量的阶数高于2,就属于NP hard。
这个任务实际上很艰巨,我们使用的是3个向量,每个向量都有对应的Entry,因此这是一个巨大的动作空间,比国际象棋或围棋之类的空间都大得多,因此也困难得多。
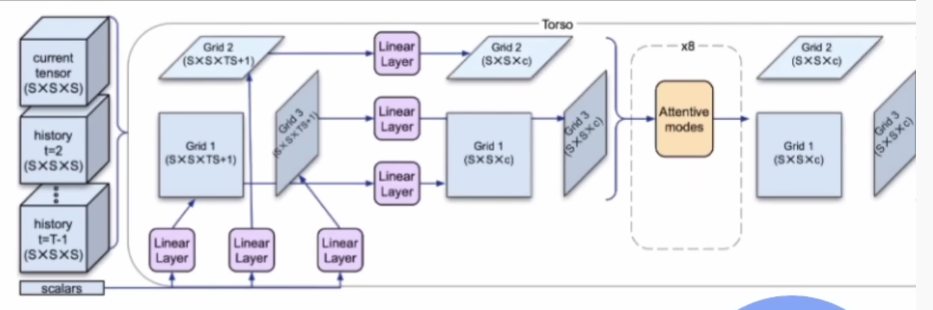
这是一个更精细的架构图。他们把最后一个时间步中出现的张量的历史,用各种方式把投影到这个网格层上,然后线性层Grid 2将其转换为某种C维向量(这里时间维度就减少了)。
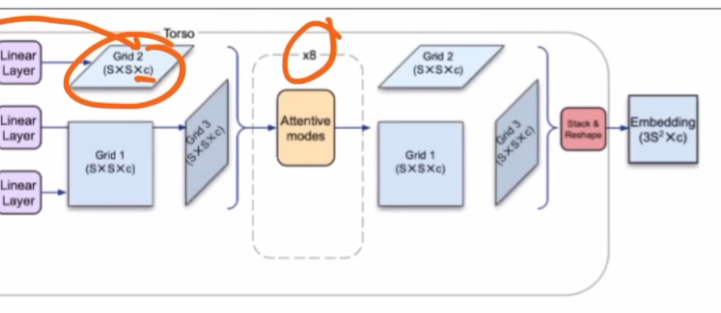
在这里,我们输出一个策略,这个策略是我们动作空间上的一个分布,还有一个输出到Value Head。
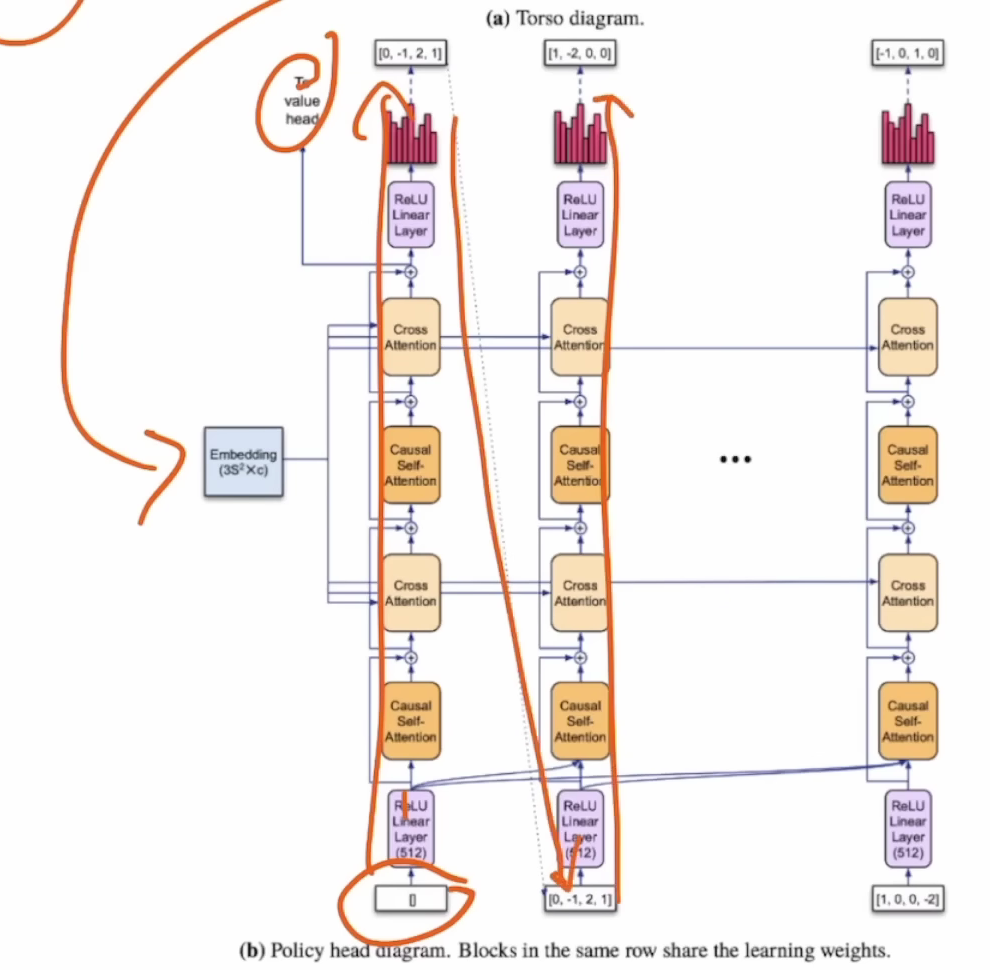
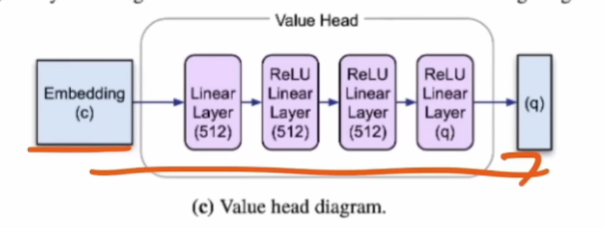
Value Head是从Policy Head中获取嵌入,然后通过一些神经网络推动。
要点就是,将网络与蒙特卡洛树搜索匹配。
总结一下:为了解决这些游戏,开始,我们的矩阵是满的,棋盘处于初始状态,然后就要考虑不同的动作,每一步动作都会包含更多的动作,包括你的对手可能考虑到的动作。
这其实就是一个树搜索算法。现在Alpha Zero style的蒙特卡洛树搜索,就是通过神经网络的策略和价值函数,引导我们完成这个树搜索。
它在用蓝线圈出的节点,就会向你提出建议,让你获得更成功的张量分解,也就是说,让你有更高的机率获胜。并且,它会直接排除掉你不该尝试的步骤,缩小你的考虑范围。
你只需要搜索,然后通过迭代训练,在某个节点,得到Zero Tensor,就意味着你胜利了。
没有完成游戏的话,奖励就非常低,反馈到训练神经网络之后,会做出更好的预测。
实际上,奖励不止是0或1, 为了鼓励模型发现最短路径, 作者还设定了一个-1的奖励。

这就比只给0或1的奖励好得多,因为它鼓励了低阶的分解,还提供了更密集的奖励信号。
因为问题很难,胜利具有很高的偶然性,奖励是稀少的。而如果走每一步都会得到奖励,也有可能是-1的奖励,就会敦促模型采取更少的步骤。
更重要的是,在这个合成演示中,他们会匹配一个监督奖励。

因为作者不仅可以生成数据,他们实际上是知道正确的步骤的,所以他们可以以监督的方式训练神经网络——因为是我们提出的问题,所以我们已经知道你该采取哪些步骤了。
再回顾一下整个算法。
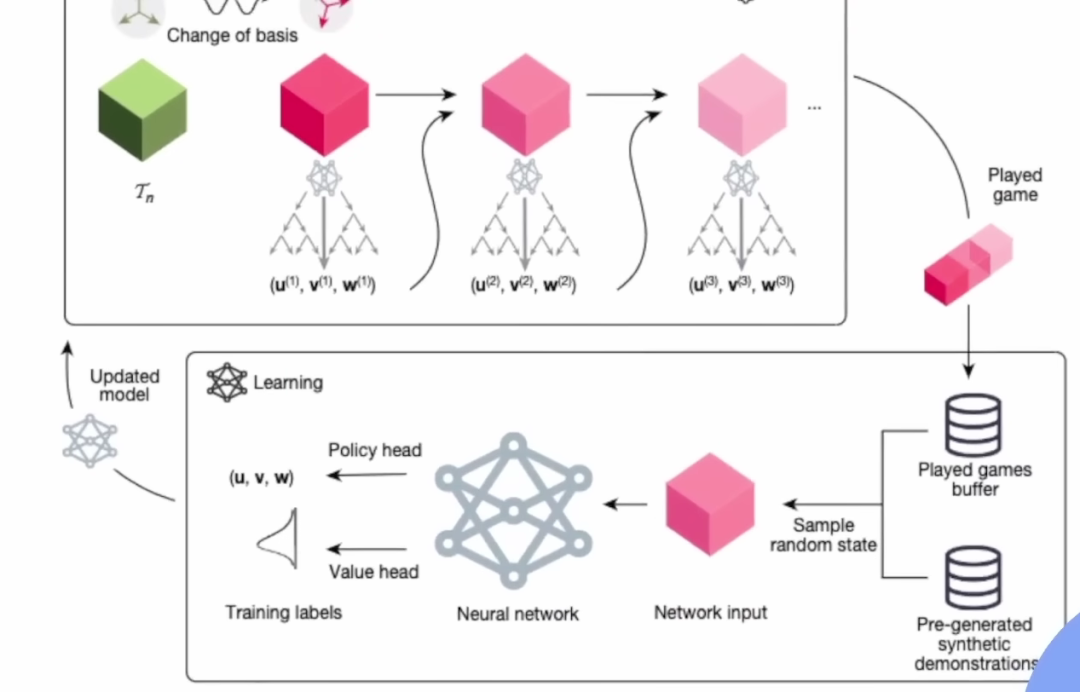
针对原始游戏,作者改变了basis,将数据增强,然后进行蒙特卡洛树搜索。几个树搜索之后,游戏结束,根据结果的输赢,会得到相应的奖励,然后来训练。
把它放在游戏缓冲区,就可以更好地预测要执行的操作。
Policy Head会指导你走哪条路,在某个节点,你可以问Value Head:现在的状态值是多少?把所有内容汇总到顶部,选择最有希望的步骤。这就是MCTS Alpha Zero style的简介。
作者的另一个巧思是:除了-1的奖励,还在终端提供额外的奖励。如果算法在英伟达V100或TPUv2上运行得很快,还会得到额外的奖励。

AlphaTensor当然不知道V100是什么,但通过强化学习的力量,我们就可以找到在特定硬件上速度非常快的算法。
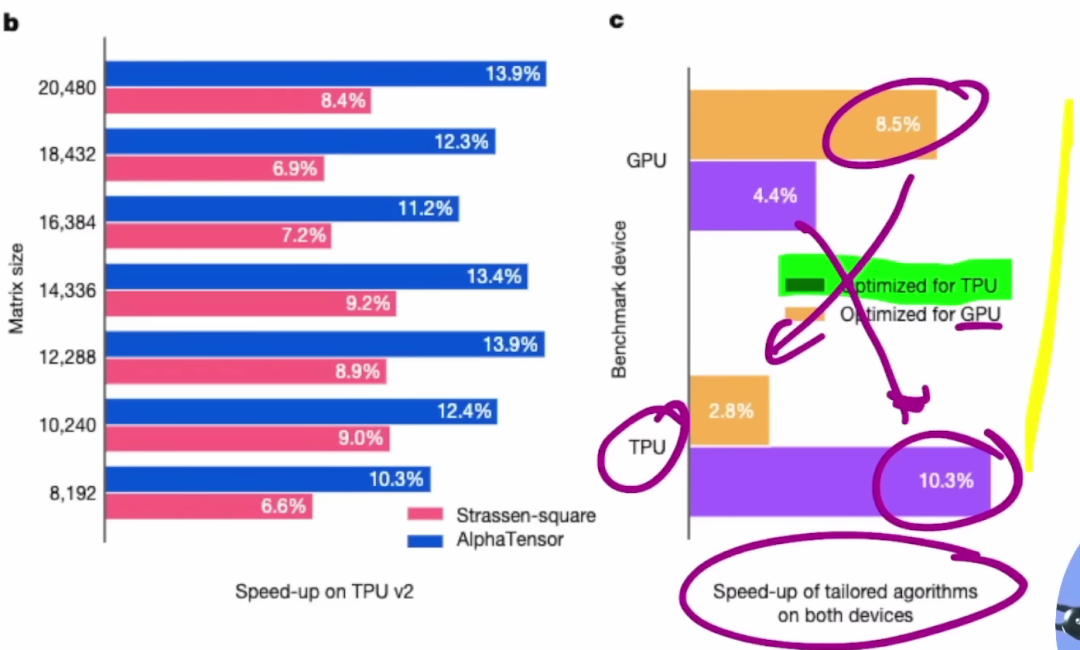
这样,我们就可以让算法提出定制的解决方案。
不仅是矩阵乘法,编译器也是这种原理。我们可以用这种方法,为特定的硬件优化速度、内存等。显然,它的应用领域已经远远超出了矩阵乘法。
对于数学的变革
作者还发现,对于两个四乘四矩阵相乘的得到的T4,AlphaTensor发现了超过14,000个非等价分解。

每种大小的矩阵乘法算法多达数千种,表明矩阵乘法算法的空间比以前想象的要丰富。
对于关心复杂性理论的数学家来说,这是一个巨大的发现。



