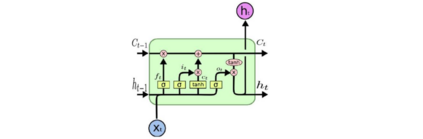
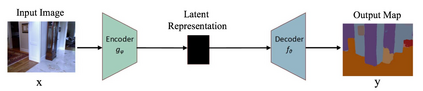
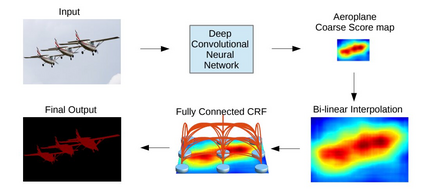
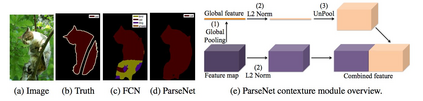
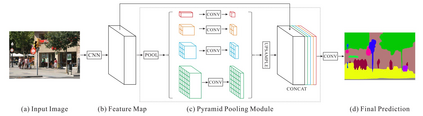
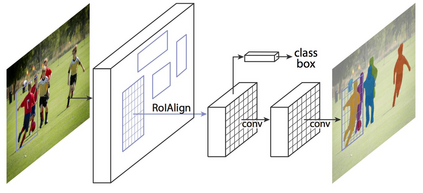
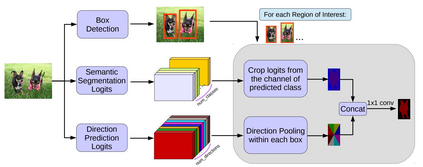
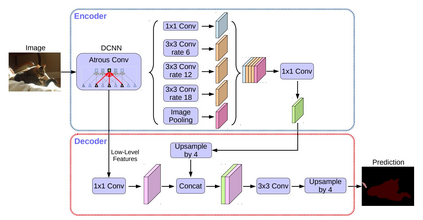
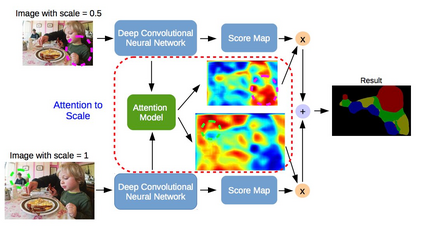
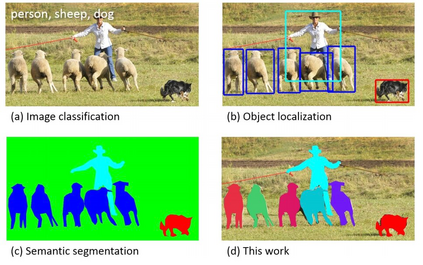
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
翻译:图像分割是图像处理和计算机视觉中的一个关键主题,其应用包括现场理解、医学图像分析、机器人感知、视频监视、增强现实和图像压缩等。文献中已经开发了图像分割的各种算法。最近,由于在各种视觉应用中深思熟虑模型的成功,利用深思熟虑模型开发图像分割方法的工作相当多。在本次调查中,我们全面审查了本文编写时的文献,包括一系列关于语义和实例分解的开拓性工作,包括完全的相形像素标签网络、编码-解码结构、多尺度和金字塔法、经常性网络、视觉关注模型和对抗环境中的基因模型。我们调查这些深思熟虑模型的相似性、长处和挑战,研究最广泛使用的数据集、报告业绩,并讨论该领域有希望的未来研究方向。