ICLR 2020 | 浅谈 GNN:能力与局限
本文简要阐述三篇与此相关的文章,它们分别研究了基于信息传递的图神经网络 GNNmp 的计算能力,GNNs 的推理能力和阻碍 GCN 变深的问题---over-fitting 与 over-smoothing。
本文涉及的 3 篇 ICLR 原文:
What graph neural networks cannot learn: depth vs width
What Can Neural Networks Reason About?
DropEdge: Towards Deep Graph Convolutional Networks on Node Classification
机器学习中一个很基础的问题是判断什么是一个模型可以学习和不能学习的。在深度学习中,已经有很多工作在研究如 RNNs、Transformers 以及 Neural GPUs 的表现力。我们也可以看到有工作在研究普遍意义上的 GNNs 相关的理论,如以图作为输入的神经网络。普遍性的表述使得我们可以更好地研究模型的表现力。
理论上,给定足够的数据和正确的训练方式,一个这种架构下的网络可以解决任何它所面对的任务。但这并不应该是一切,只是知道”一个足够大的网络可以被用来解决任何问题”无法使我们合理地设计这个网络,而另一方面,我们需要通过研究他们的局限来获取更多关于这个模型的认知。
本文研究了基于信息传递的图神经网络 GNNmp 的表达能力,包括 GCN、gated graph neural networks 等,并回答了如下问题:
(1)什么是 GNNmp 可以计算的?
本文证明了在一定条件下,GNNmp 可以计算任何可以被图灵机计算的函数。这个证明通过建立 GNNmp 和 LOCAL 之间的关系来实现。而 LOCAL 是一个经典的分布式计算中的模型,本身是具有图灵普遍性的。简言之,GNNmp 如果满足如下的几个较强的条件,即具有足够多的层数和宽度、节点之间可以相互区分,即被证明是普遍的。
(2)什么是 GNNmp 不可以计算的?
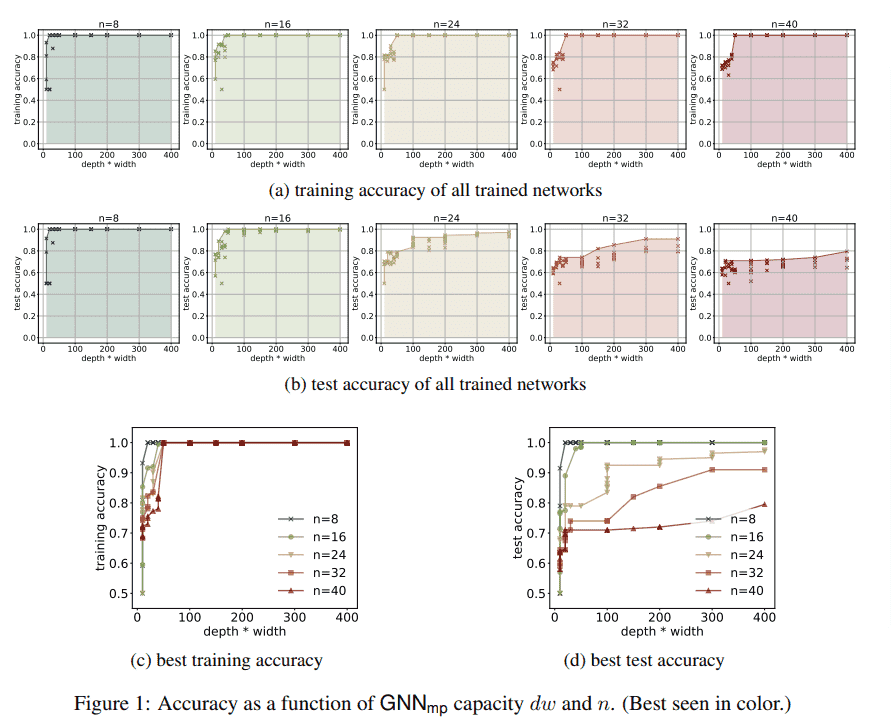
本文证明了如果乘积 dw 被限制,GNNmp 的能力会损失很大一部分。具体的,本文对于以下的几个问题展示了 dw 的下限,即检测一个图中是否含有一个指定长度的环,确认一个子图是否是联通的、是否包含环、是否是一个二分图或是否具有哈密顿回路等。

本文展现了 GNNmp 在和合成数据上的实验结果,选取 4-cycle 分类问题,即将图根据它们是否包含有 4 个节点的回路来将其分类的问题来检验 GNNmp 的能力,目的在于验证 GNNmp 的 dw 乘积,节点数 n 和 GNNmp 解决问题的能力之间的关系。
What Can Neural Networks Reason About?
近来,有很多关于构建可以学会推理的神经网络的尝试。推理任务多种多样,如视觉或文本问答、预测物体随时间的演化、数学推理等。神奇的是那些在推理任务中表现较好的神经网络通常具有特定的结构,而很多成功的模型均采用 GNN 的架构,这种网络可以显示的建模物体两两之间的关系,并可以逐步的通过结合某个物体和其它物体的关系来更新该物体的表示。同时,其他的模型,如 neural symbolic programs、Deep Sets 等,也都可以在特定问题上取得较好的效果。但是关于模型泛化能力和网络结构之间关系的研究仍然较少,我们自然会问出这样的问题:怎样的推理任务可以被一个神经网络学习到?这个问题的回答对我们如何理解现有模型的表现力和其局限性至关重要。本文通过建立一个理论框架来回答这个问题,我们发现如果可以在推理问题和网络之间建立良好的对应关系,那么这个问题可以被很好地解决。
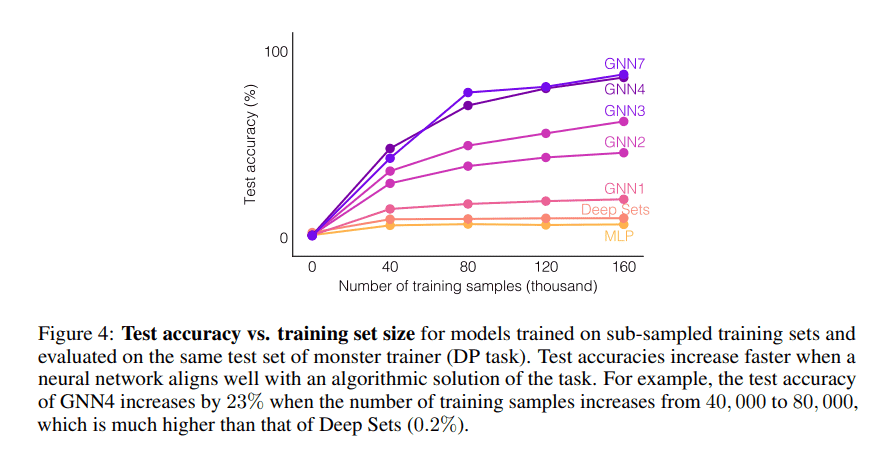
例如,在 Bellman-Ford 算法求解任意两点间最短路径的问题上,虽然可以证明 MLP 可以表示任何 GNN 可以表示的函数,但 GNN 的泛化能力更强,而后者决定了 GNN 的效果更好,或者说,GNN 学到了如何去推理。究其原因,GNN 可以通过学习一个很简单的步骤,即该算法中的松弛过程,来很好地模拟 Bellman-Ford 算法,而与此相对应地,MLP 却必须去模拟整个 for 循环才可以模拟 Bellman-Ford 算法。

DropEdge: Towards Deep Graph Convolutional Networks on Node Classification
GCNs 在图的很多任务上取得了 SOTA 的表现,如节点分类,社交推荐,关联预测等,而 over-fitting 和 over-smoothing 是两个阻碍 GCNs 在节点分类等任务上进一步发展的问题。
over-fitting 来源于使用一个具有过多参数的模型去拟合一个受限的训练集数据分布,其削弱了模型的泛化能力,而 over-smoothing 则是另一个极端,它指的是因为图卷积操作将一个节点和它邻居的特征向量混合起来,从而在有限步之后所有节点的表示都会收敛到一个相同的值的现象,这同时也会导致梯度消失,直接使得我们无法构建比较深的 GCNs,实际上经典的 GCNs 是比较浅的。受启发于深层的CNNs在图像分类任务上的良好表现,我们也希望探索在节点分类任务上如何可以建构出深层的 GCNs。通过探索这两个阻碍 GCNs 变深的因素---over-fitting 与 over-smoothing,本文提出了 DropEdge,可以同时缓解如上的两个问题,一方面,它可以看做是一种无偏的数据增强方式,通过随机地将原图变形,可以增加输入数据的多样性,从而可以缓解 over-fitting 的现象;另一方面,它可以减少信息在节点间传递,使得节点之间的连接更加稀疏,从而可以一定程度上避免 over-smoothing。
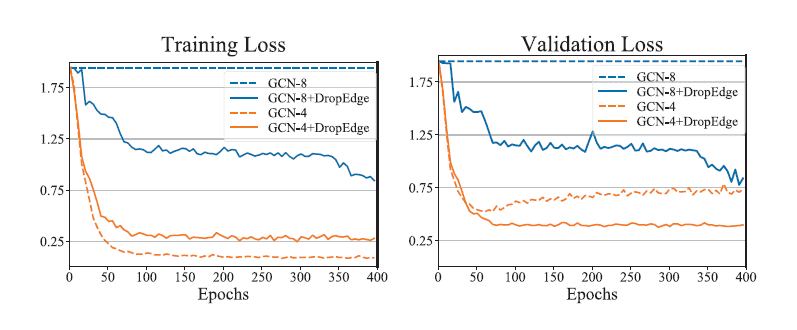
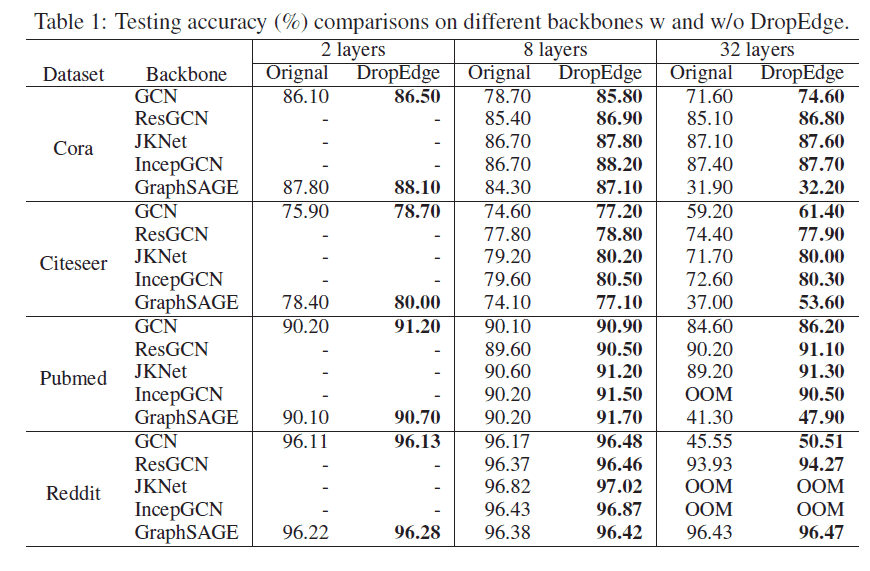
我们在四个数据集上验证 DropEdge 的效果,说明其可以提高 GCNs 的表现里并确实具有防止 over-smoothing 的作用。
更多 ICLR 论文话题,可通过微信“Moonnn01”加入 ICLR 2020 交流群讨论。

点击左下角“阅读原文”,一键直达 ICLR 2020 专题




