LSTM还没「死」!
作者:Nikos Kafritsas
机器之心编译
编辑:杜伟、陈萍
如果说「LSTM」已死,它为何依然能够在Kaggle竞赛中成为赢家呢?

长短期记忆(Long Short-Term Memory,LSTM)是一种时间循环神经网络(RNN),论文首次发表于1997年。由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。
在过去几十年里,LSTM发展如何了?
密切关注机器学习的研究者,最近几年他们见证了科学领域前所未有的革命性进步。这种进步就像20世纪初,爱因斯坦的论文成为量子力学的基础一样。只是这一次,奇迹发生在AlexNet论文的推出,该论文一作为Alex Krizhevsky,是大名鼎鼎Hinton的优秀学生代表之一。AlexNet参加了2012年9月30日举行的ImageNet大规模视觉识别挑战赛,达到最低的15.3%的Top-5错误率,比第二名低10.8个百分点。这一结果重新燃起了人们对机器学习(后来转变为深度学习)的兴趣。
我们很难评估每次技术突破:在一项新技术被引入并开始普及之前,另一项技术可能变得更强大、更快或更便宜。技术的突破创造了如此多的炒作,吸引了许多新人,他们往往热情很高,但经验很少。
深度学习领域中一个被误解的突破就是循环神经网络(Recurrent neural network:RNN)家族。如果你用谷歌搜索诸如「LSTMs are dead」「RNNs have died」短语你会发现,搜索出来的结果大部分是不正确的或者结果太片面。
本文中数据科学家Nikos Kafritsas撰文《Deep Learning: No, LSTMs Are Not Dead!》,文中强调循环网络仍然是非常有用的,可应用于许多实际场景。此外,本文不只是讨论LSTM和Transformer,文中还介绍了数据科学中无偏评估这一概念。
以下是原文内容,全篇以第一人称讲述。
LSTM 曾经主导了 NLP 领域
早在1997年,LSTM在论文 《LONG SHORT-TERM MEMORY 》中被提出,直到2014年才进入高速发展阶段。它们属于循环神经网络家族- RNN,以及门控循环单元GRU。
随着GPU的可访问性和第一个深度学习框架的出现,LSTM成为支配NLP领域的SOTA模型。2013 年词嵌入的出现促进了迁移学习机制的构建。事实上,当时几乎所有 NLP 任务的标准组件都是:a)预训练词嵌入,b)LSTM 和 c)序列到序列架构。
在那个时期,每个数据科学家都同意 LSTM 主导了 NLP 领域:它们被用于语音识别、文本到语音合成、语言建模和机器翻译。每家大型科技公司都接受了LSTM ;毫不夸张的说没有 LSTM 就没有 NLP。
谷歌为机器翻译创建的最佳模型之一,如下图1所示:
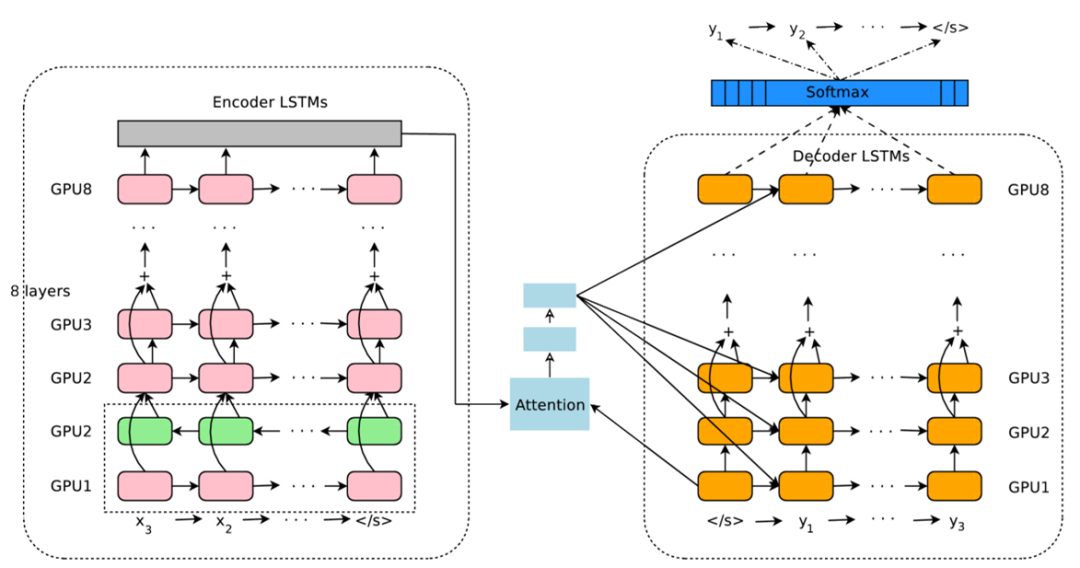 图1:谷歌神经机器翻译- GNMT架构。
图1:谷歌神经机器翻译- GNMT架构。
这个复杂的模型存在于谷歌翻译服务中,与之前的版本相比,GNMT减少了60%的翻译错误。正如我们看到的,GNMT大量使用了LSTM,形成了著名的编码器-解码器拓扑(包括一个双向LSTM)。
此外,GNMT还利用了Attention,这是一种允许模型在需要时关注输入序列相关部分的机制。如图1 所示,其中编码器的顶部向量使用注意力分数加权。换句话说,每个时间步骤中的每个单词都有一个可学习的分数,以最小化错误。要了解更多信息,请查看资料:
博客地址:https://smerity.com/articles/2016/google_nmt_arch.html
论文地址:https://arxiv.org/abs/1609.08144
打开Transformers的世界
2017年,谷歌在论文《Attention Is All You Need》中推出Transformer ,这是NLP生态系统的里程碑式的进步。这个新模型通过提出多头注意力机制来深入研究注意力,具体表现在:
充分利用自注意力优势,从而实现卓越性能;
采用模块化结构,可以并行进行矩阵运算,换句话说,Transformer运行得更快,具有更好的可扩展性。
从那以后,Transformer成为研究语言处理的基础,并产生了新的变体。变体如下图2所示:
 图2:开源的Transformer系列
图2:开源的Transformer系列
不能被遗忘的时间序列
传统统计方法赢得第一轮
然而,实验结果表明,LSTM和Transformer在准确度方面并非一定优于传统统计方法(例如 ARIMA)。另一方面,统计方法和基于RNN的方法相结合更有效。一个典型的例子是 Uber 构建的 ES-RNN 模型,该模型最终赢得了 M4竞赛。该模式是一种在扩张的 LSTM 之上使用指数平滑的混合模型。
当然,Transformer 也受到了考验。对于时间序列预测,最常用的方法是使用原始的 Transformer,并将位置编码层替换为 Time2vec 层。但是,Transformer 模型也无法超越统计方法。
此外,我还想说明以下几点:
这并不意味着统计方法总是更好。在有大量数据的情况下,LSTM 的性能可以比 ARIMA 更好;
统计方法需要更多的数据预处理。这可能包括时使时间序列平稳、消除季节性和波动性等。通过更简单的技术,LSTM 可以更容易地捕捉序列的自然特征;
统计方法的通用性较差。例如,自回归方法无法处理未来未知的额外特征。
深度学习(DL)赢得第二轮
直到2018~2019年,深度学习模型才开始在时间序列预测任务中变得更具竞争力。
下图 3 和图 4 显示了两个SOTA模型,分别为谷歌的Temporal Fusion Transformer(TFT)和亚马逊的DeepAR。
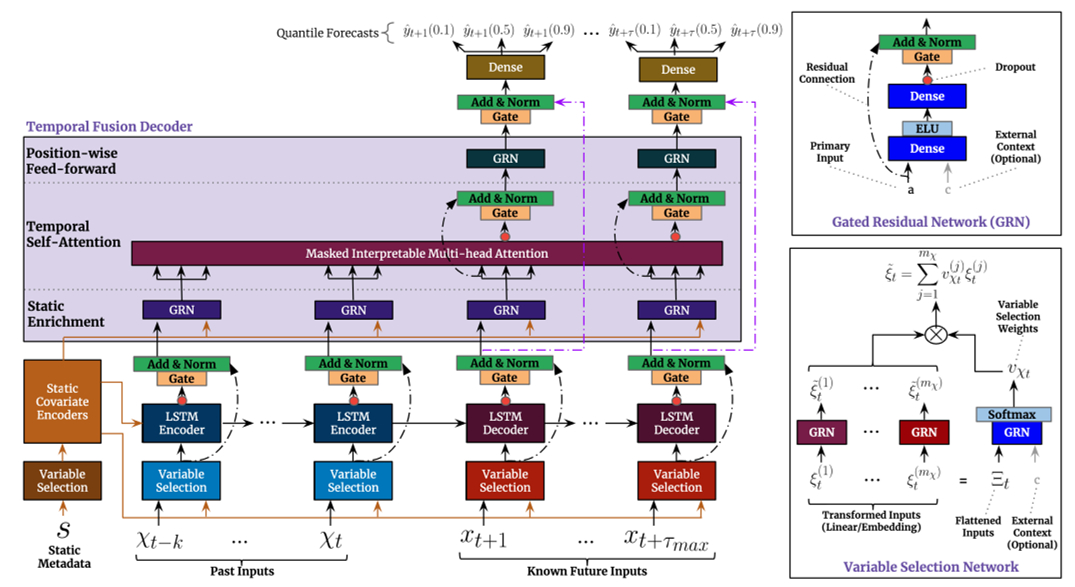 TFT。图源:https://arxiv.org/pdf/1912.09363.pdf
TFT。图源:https://arxiv.org/pdf/1912.09363.pdf
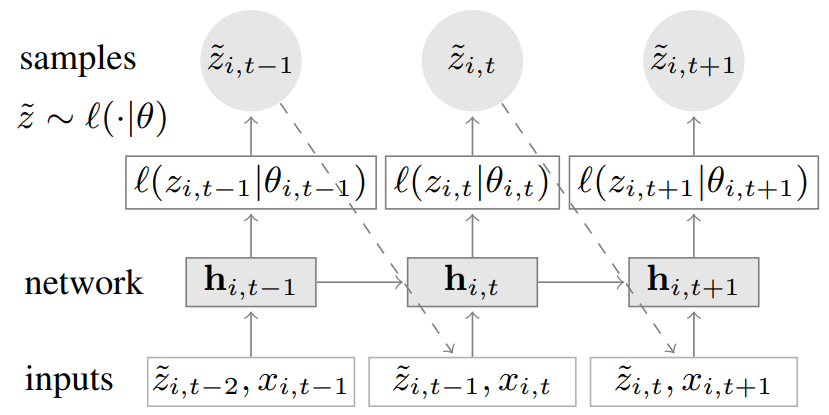 图源:DeepAR模型架构。图源:https://arxiv.org/pdf/1704.04110.pdf
图源:DeepAR模型架构。图源:https://arxiv.org/pdf/1704.04110.pdf
这两个模型有很多有趣的地方,但与本文主题产生共鸣的最重要一点是:
它们都使用了LSTM!怎么做到的呢?
TFT 是一种用于时间序列的多层纯深度学习模型,该模型具有LSTM 编码器-解码器以及提供有可解释预测的全新注意力机制。
DeepAR 是一个复杂的时间序列模型,它结合了自回归和深度学习的特征。上图 4 中的 h_i,t 向量实际上是 LSTM 单元的隐藏状态,它们被用来计算高斯分布的 μ 和 σ 参数。从这个分布中,选择n个样本,其中位数代表预测值。
结果表明,这两种深度学习模型都优于传统的统计方法。此外,这两种模型都更加通用,因为它们可以处理多个时间序列并接受更丰富的功能集,其中TFT 略胜一筹。
循环与注意力如何关联起来
为了学习不同尺度的时序关系,TFT 使用循环层进行局部处理,使用可解释的自注意力层进行长期依赖。考虑到我们目前所知道的以及上文所述,可以得出以下结论:循环网络非常擅长捕捉序列的局部时间特征,而注意力则更擅长学习长期动态。
这不是一个武断的结论。TFT论文的作者通过执行消融分析证明了这一点。他们在其他组件中测试了LSTM编码器-解码器层:在消融实验中使用原始 Transformer 的标准位置编码层来替换它,得出了以下两个结论:
序列到序列层的使用对模型性能产生增益;
在执行基准测试的5个数据集中的4个 ,LSTM 层实现了更佳的性能。
LSTM的隐藏优势:条件输出
条件输出是 LSTM 最被忽视的优势之一,许多数据科学从业者仍然没有意识到这一点。如果你一直在用原始循环网络,就会发现这种类型的网络只能处理被表示为具有各种依赖关系的序列的时序数据。但是,它们不能直接对静态元数据或非时变数据进行建模。
在 NLP 中,静态元数据是不相关的。相反,NLP 模型专注于单词词汇表,其中每个单词都由嵌入表示,这是整个模型的统一概念。每个单词所来自文档的类型并不重要,只要 NLP 模型可以学习每个单词的正确上下文感知表示即可。但要记住:一个特定的单词可以有不同的嵌入,这取决于它的含义和它在句子中的位置。
但是,在时间序列模型中,非时变数据的影响要大得多。例如,假设我们有一个涉及商店产品的销售预测场景,产品的销量可以建模为时间序列,但也会受到假期等外部因素的影响。因此,一个好的预测模型也应该考虑这些变量。这就是TFT所做的,参见下图 5。
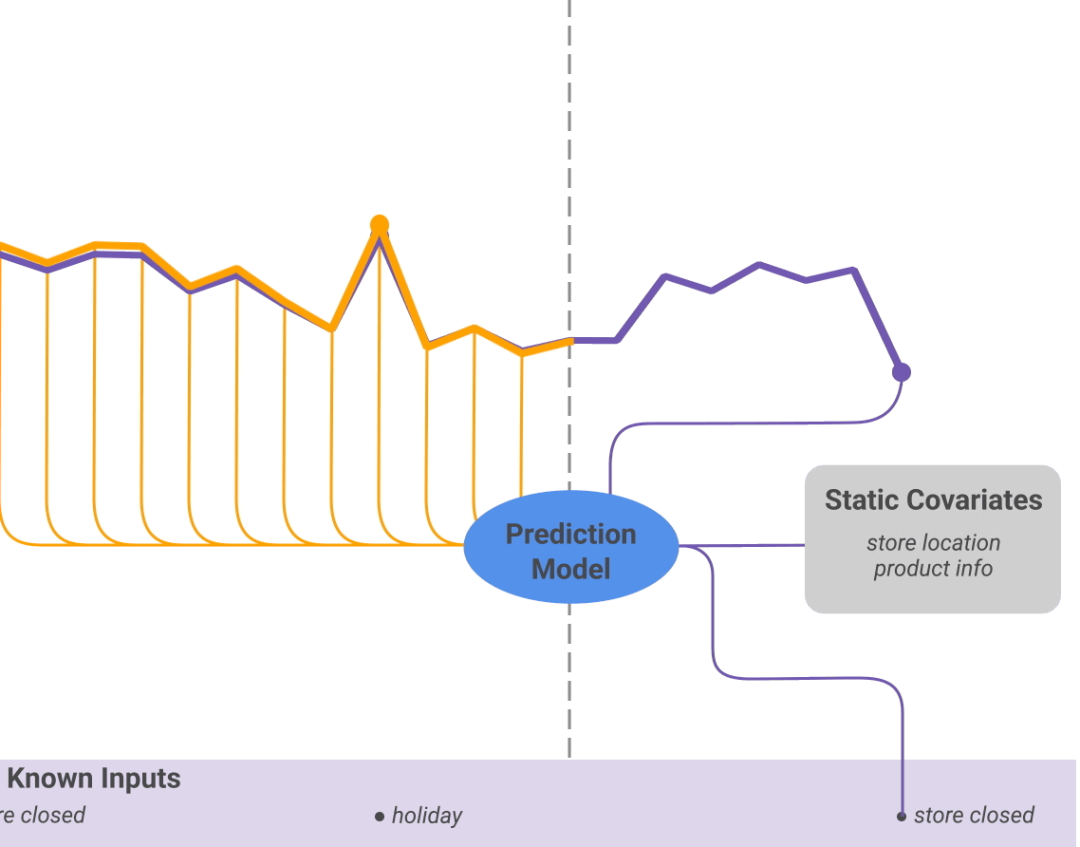 图5:外部静态变量对预测的影响。
图5:外部静态变量对预测的影响。但是,TFT是如何实现的呢?TFT 专为集成静态元数据而设计,它使用了各种技术,最重要的一个与 LSTM有关。
LSTM 使用 [11] 中首次介绍的技巧无缝地执行此任务:没有将 LSTM 的初始 h_0 隐藏状态和单元状态 c_0 设置为 0(或随机),而是使用指定向量或嵌入来初始化它们。或者正如 TFT 所做的一样,在拟合期间使这些向量可训练。通过这种方式,LSTM 单元的输出可以适当地在外部变量上发挥作用,而不会影响其时间依赖性。
LSTM vs TCN
在注意力和Transformer出现之前,有另一种有望改变现状的模型,即时间卷积网络(Temporal Convolutional Networks, TCN)。
TCN 在 2016年首次提出并在2018年规范化,它利用卷积网络对基于序列的数据进行建模。自然地,它们也是时间序列预测任务的理想方案。
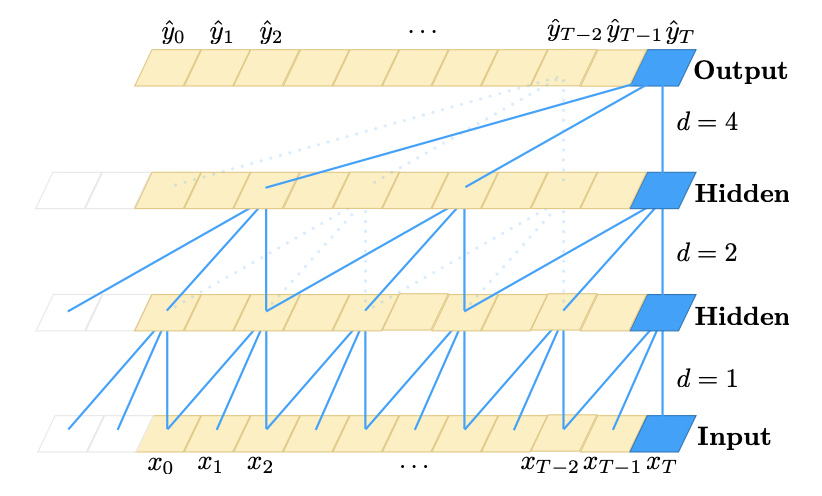 扩张卷积示意图,其中过滤器大小k = 3,扩张因子d = 1, 2, 4。感受野可以覆盖来自输入序列的所有数据点x_0...x_T。图源:https://arxiv.org/pdf/1803.01271.pdf
扩张卷积示意图,其中过滤器大小k = 3,扩张因子d = 1, 2, 4。感受野可以覆盖来自输入序列的所有数据点x_0...x_T。图源:https://arxiv.org/pdf/1803.01271.pdf
TCN 的「秘密武器」是扩张卷积,如上图6所示。标准CNN 使用固定大小的内核/过滤器,因此它们只能覆盖邻近的数据元素。TCN使用扩张卷积,它们在不同长度的输入序列上使用填充(padding),从而能够检测彼此邻近但位置完全不同的item之间的依赖关系。
此外,TCN 中还使用了其他技术,例如残差连接,它现在已经成为深度网络的标准。这里主要关注 LSTM与TCN之间的差异:
速度:一般来说,TCN 比 LSTM 快,因为它们使用卷积,可以并行完成。但在实践中,通过使用大量扩张,并考虑到残差连接,TCN 最终可能会变慢;
输入长度:TCN 和 LSTM 都能够接受可变长度输入;
内存:平均而言,TCN 比 LSTM 需要更多内存,因为每个序列都由多个扩张层处理。同样,这取决于定义每个模型变得有多复杂的超参数;
性能:最初的论文表明 TCN 优于LSTM。然而,在实践中,情况并非总是如此。[13] 中的一项更详尽的研究表明,在某些任务中,TCN 更好,而在其他任务中,LSTM 更有效。
TCN和LSTM都有各自的优缺点。最好的方法是对它们进行评估,找到最适合自己的方案。但要注意,除非你的用例非常小,否则无法通过单个TCN或LSTM模型实现 SOTA 性能。现代用例会考虑更多外部参数,这就需要更具挑战性的方法。反过来,这也就意味着必须使用多个组件或模型。
Kaggle中的深度学习和时间序列
到目前为止,我们一直在从学术角度评估单个模型。然而,如果我们要制定一个更详细的观点,就不能忽略实际应用。
Kaggle提供了一个很好的评估基准,我们以 Kaggle 比赛为例:呼吸机压力预测。该比赛任务是根据控制输入的序列预测机械肺内的压力序列。
比赛需要同时解决回归和分类任务;
数据集为创造性特征工程打开了大门;
由于每个主题/数据点都用不同的序列表示,因此使用统计模型是不可行的。
获胜团队提交了一个多层次深度架构,其中包括一个 LSTM 网络和一个 Transformer 块。此架构如图 7 所示:
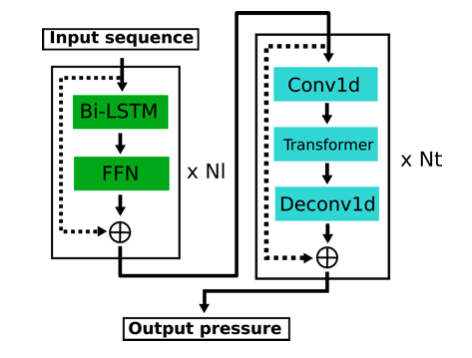
图7:第一名解决方案架构。
卷积神经网络的命运
2020年,Transformer被改编为计算机视觉版,诞生了vision Transformer (ViT),论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》中提出。这篇论文引发了进一步的研究,最终经过不断的升级,ViT模型能够在图像分类任务中优于CNN。
因此,这个阶段,我希望我们不要再说「CNN已经死亡」或者「CNN正在衰落」这样的评价。
要正确评估机器学习领域的突破所带来的影响几乎是不可能的;
Transformer的出现重塑了这一局面:LSTM,尤其是NLP中的LSTM不再是人们关注的焦点;
对于时间序列,LSTM更有用;
数据科学涉及多个领域,例如音频、文本、图形等。这反过来又需要各种方法/模型的结合来应对这些挑战。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com





