Linux存储入门:简易数据恢复方案--分区和LVM实战
数据恢复有没有简易方案?
IT工程师一般都知道如何操作和使用文件和目录。但是,对于系统如何构建出、抽象出文件和目录,一般就不熟悉了。至于更下层的概念,可能大家知道最多的就是驱动了。所以,为了规避这点,可行的简易方案之一,就是以黑箱方式使用testdisk等工具,在我们在对底层了解不多甚至一无所知的情况下,进行数据恢复(商业工具,恢复效果估计更好,当然商业工具的价格也更好)。但是,对于工程师而言,多数时候,仅仅以黑箱方式依赖某些工具进行数据恢复是不够的。
数据恢复,经常是突发事故响应中关键而又耗时的一步。多数情况下,工程师往往并非专司数据恢复,操作环境往往是生产环境,趁手工具难以部署,执行操作要遵循种种约束,加之业务中断的压力。这种情形下,工程师很可能还需要推定数据恢复的结果/耗时等信息,提供数据供决策者使用。很明显,如果你准备考验一下自己的细致、耐心、知识和技能,数据恢复将是个不错的课题。当然,有一点是明确的,只是以黑箱方式使用testdisk等工具进行数据恢复,解决以上问题是不可能的。那么,有没有其他简易方案呢?
这里,我们以一个实际的case为例,讨论一下,在只使用UNIX常见工具(dd/grep/strace等)的情况下,如何简单、快捷的恢复数据。
预先准备
工具
我们要用到以下工具
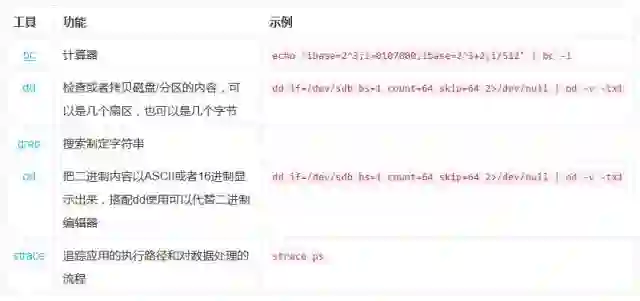
排查和诊断就是数据处理
如果对数据处理了解不多,请参考OSEMN
1. obtaining data/获取数据
2. crubbing data/清洗数据
3. exploring data/探索数据
4. modeling data/建模数据
5. interpreting data/解释数据
测试环境
使用Virtualbox,基于CentOS/Fedora/debian/Ubuntu搭建Linux实验环境。只需要学会strace工具和如下系统调用,就足以追踪系统如何处理诸如LVM物理卷元数据这样过的问题。

数据恢复的原理和流程
什么是元数据?
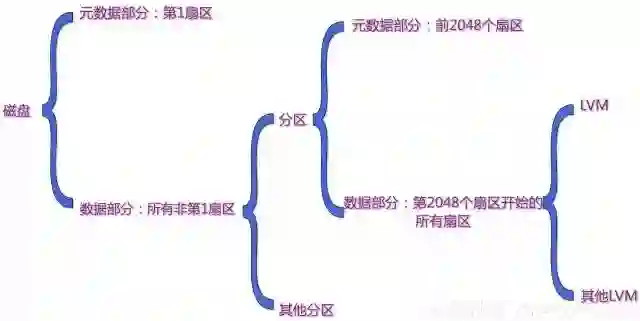
我们以大家都熟悉的磁盘作为存储设备的例子。
现代操作系统都会在磁盘上建立多个分层结构来管理和控制磁盘。比如,磁盘分区,分区上建立物理卷,物理卷上建立卷组,卷组上建立逻辑卷,逻辑卷上建立文件系统,就是这样的一个例子。如果你不熟悉LVM,请参考Logical Volume Manager。
这些分层的结构都是很类似的。以磁盘分区为例。所谓分区,以大家最为熟悉的MBR: Master Boot Record结构为例。其实是第一个扇区记录了各个分区的起始扇区,大小和类型。系统需要时,比如启动过程中,系统只要从磁盘的第一个扇区读取这些数据即能拿到各个分区的数据。
具体看看分区的数据结构。以fdisk为例,分区的数据结构定义为
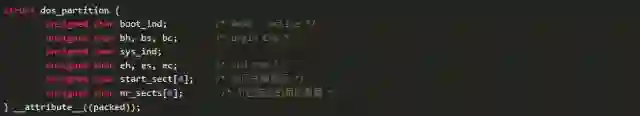
我们看看具体分区的例子,验证一下数据结构
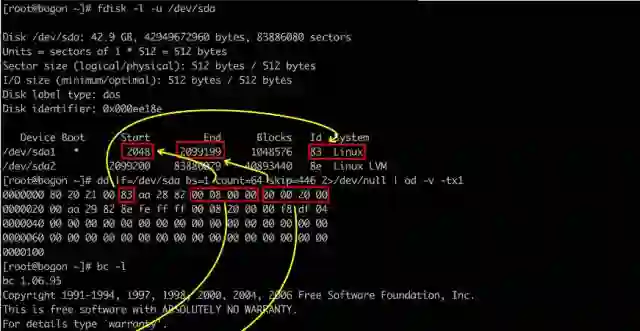
分区使得磁盘上的扇区有了差别。第一个扇区(其实其编号是0),因分区数据记录其上而扮演特殊角色。明显,对系统而言,管理和操作分区实际上就是读写第一扇区上的对应记录而已。
类似分区信息这种系统用以管理某层资源的数据就是元数据。
系统在磁盘上建立的各个分层结构,都有类似分区结构的数据结构。以LVM结构为例,我们可以把磁盘记录和LVM工具报告的数据做一对比。LVM数据的从第2个扇区开始,卷组数据在第8个扇区中,可以用dd命令提取相关扇区来验证LVM的数据结构。
下面是一份完整的LVM元数据信息,有兴趣者可以逐一清点各个对象。
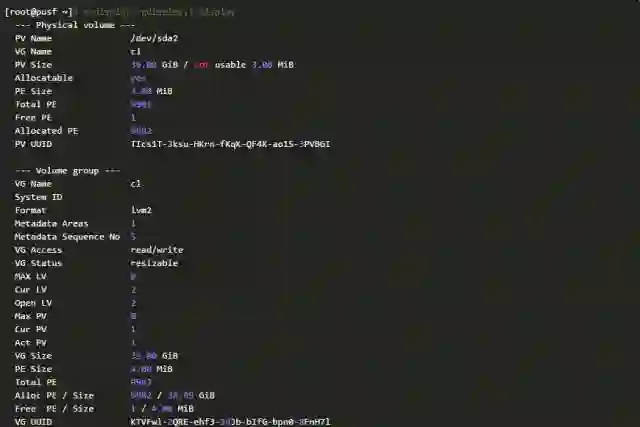
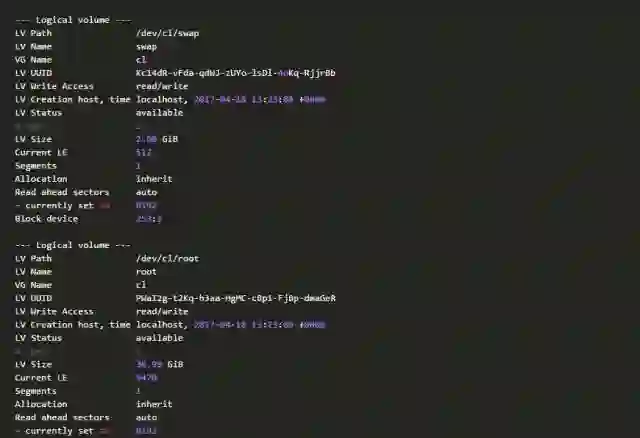
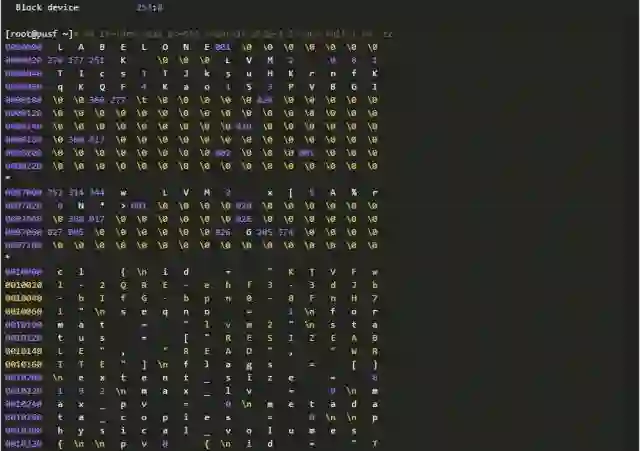
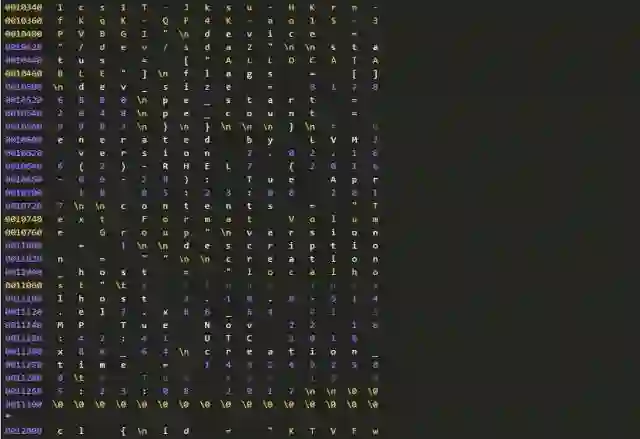




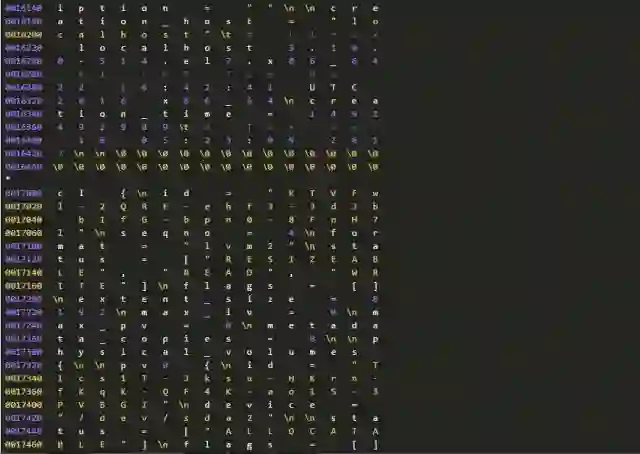
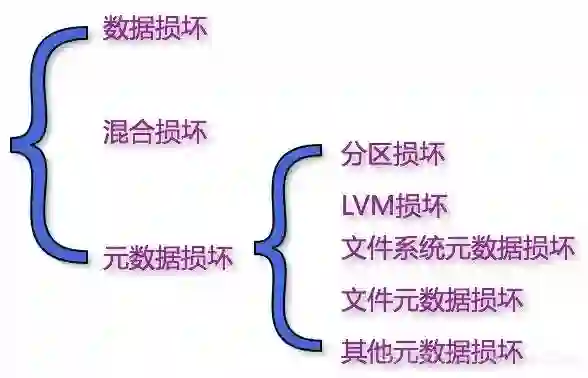
元数据和数据:数据损坏分类
系统把磁盘的扇区分成两种来支持分区:第一扇区和所有其他非第一扇区。并且在第一个扇区上记录分区信息,即元数据。而其他非第一扇区则供分区层使用,从磁盘的视角看,其他非第一扇区则是数据部分。我们逐层考察下磁盘、分区和LVM结构
系统启动时,会逐层读取各层元数据,创建各层数据结构。如果某一层元数据损坏或者丢失,那么系统就没有办法完成创建各层数据结构的任务。这种情况下,从客户角度看,很可能就是数据损坏了。比如,如果你把第一个扇区用\0覆盖一遍,那么系统就识别不到分区内容了。当然这种情况下分区层以上的内容,比如物理卷信息,系统也无法处理了。因此,对于数据恢复任务而言,如果元数据损坏,则修复元数据总是必须的,而且往往是第一步。
当然,如果数据损坏了,即使元数据完好无缺,那么数据也是损坏了。比如,你误删了一个文件,那么,分区结构再完好对于文件被删也于事无补。
基于以上分析,我们可以把数据损坏简单分三类类:元数据损坏、数据损坏或者前面两种损坏类型的混合型损坏。
元数据修复可以简易处理
以基于磁盘的分区、LVM以及文件系统为例。分层结构的数据格式都有严格的格式(比如分区的数据结构就是一个C的struct),出现位置也固定(有关分区的元数据记录在第一个扇区的446~462字节之间),而且这些数据结构往往都带有魔数(比如,分区的类型83),而且常用的分层结构,也不外乎分区、LVM以及文件系统等几种。因此,对于元数据以及系统如何处理元数据,我们都容易追踪和检查。因此,可以预期,修复元数据,有简易方案。
原理
如果有数据损坏,那么除非有日志、备份,或者数据本身有逻辑可供使用,否则数据是不能恢复了。比如,通常的文件删除操作,系统只是解除了文件名称和文件内容相关间的联系而已。文件本身的内容还是记录再磁盘上。这种情况下,只要重建文件名称和文件内容间的联系即可恢复文件。
相对而言,简单情形的是元数据损坏。如果只是元数据损坏,而且我们知道正确的元数据。因为元数据操作,不会触及数据部分,因此,我们只要重建元数据部分即可恢复数据。如果涉及到多层,则逐层恢复即可。以分区丢失为例。
比如我们有一块数据盘,整盘我们只是用fdisk分了一个区,现在分区丢失了。这种情形下,只要用fdsik,按照默认情形,重新分区就能恢复分区。
就这种情形,我们给出一个可用的分析流程。
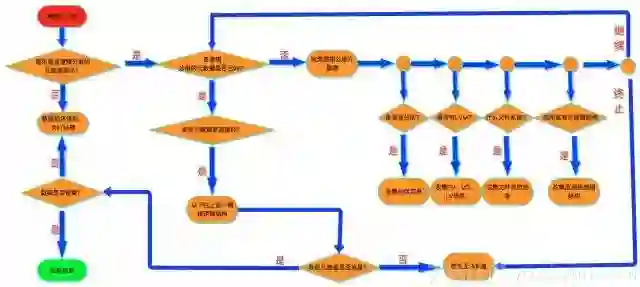
症状和初步排查
症状
客户反馈
降配重启后,系统无法启动
排查发现客户一逻辑卷无法挂载导致重启失败。在/etc/fstab中注释掉逻辑卷的挂载配置,系统启动成功。
但是客户的逻辑卷上有重要数据。此逻辑卷在数据盘上,数据盘大小是2TB。此磁盘全部2TB全部分配给一个分区,此分区上创建有LVM结构。
分区数据如下
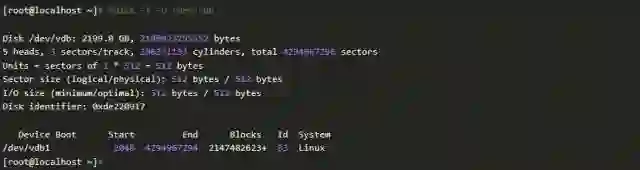
初步排查
首先确定分区上是否有数据,通过查看一些扇区,我们就会有很大的概率确认这一点。当然也可以逐扇区确认。
逐扇区确认,可以用如下命令办理。假设磁盘是/dev/vdb。

当然,也可以通过抽样检查来确认。这种方法通常是检查磁盘分区的前面一部分扇区。比如,下面的例子,通过检查前面几十个扇区,我们可以确认磁盘上确有数据。
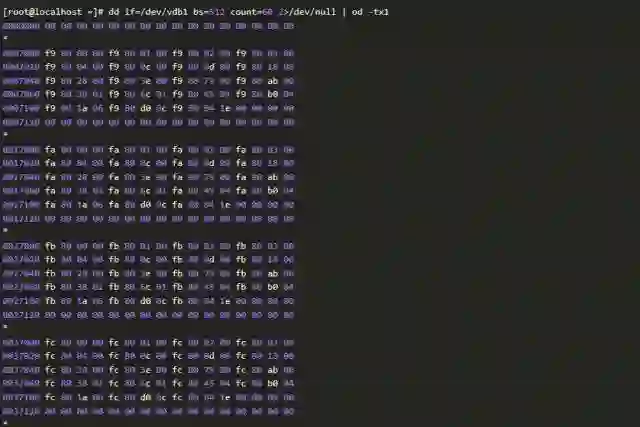
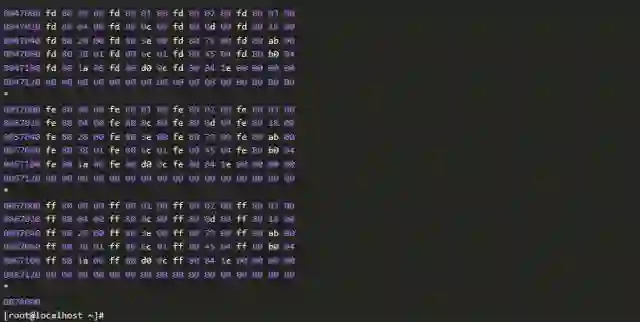
接下来使用testdisk工具恢复数据。尝试数次,testdisk工具总是在扫描到2%时停滞,处理过程不能继续。
初次恢复尝试
分区还在,但是LVM结构丢失,经检查,由LVM工具链维护的备份数据/etc/lvm/backup/vg_xxxxxx文件还在。因此,这种情形下,按照我们的恢复流程,只要在分区之上,尝试重建LVM和文件系统,应该就可以解决问题。

根据备份数据恢复LVM结构,可以参考Recovering Physical Volume Metadata。可惜的是,我们第一步就折戟沉沙了。

看样子,分区的数据有些地方出错了。根据上面命令报错的信息,对比LVM的备份数据和分区数据,很快我们就发现了问题。现有分区记录的其拥有的扇区数目,少于其上LVM卷组记录的扇区数量。

问题出在哪里?
因为种种原因,我们不能确认分区信息和LVM备份数据为何不一致。但是,我们可以进一步从磁盘上提取、分析数据。因为有关分区的元数据在(分区在),所以我们进一步检查磁盘上还有没有有关LVM的元数据?这只要使用下面的命令行

结果及其结果分析如下
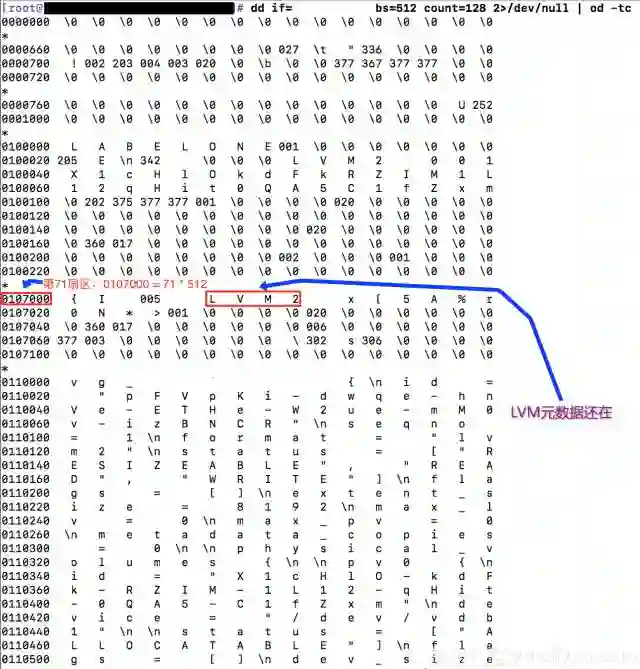
所以,磁盘上还有有关LVM的元数据,但是为什么系统没有凭借这些数据构建出LVM结构呢?我们创建一个测试环境,用strace追踪下系统处理LVM物理卷元数据的执行路径。如下命令即可

当然,更好的办法是把strace记录放置到文件中,以备仔细检查

我们组合使用strace和grep命令来确认系统默认的LVM物理卷位置。如果你没有耐心分析下面的数据,请跳过直接看后面的截图

数据清洗结果如下。如果没有耐心分析,请跳过直接看下面的分析截图
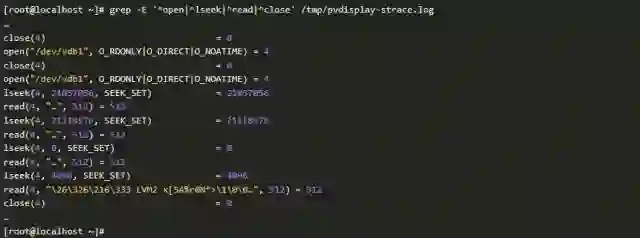
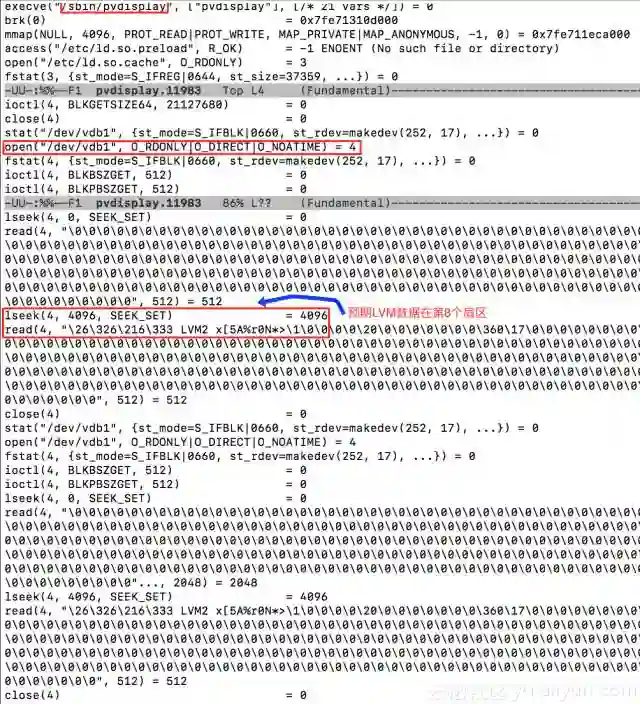
很明显,系统预期LVM元数据是在分区的第8个扇区,但是在需要做数据恢复的磁盘上,LVM的元数据却是在第71个扇区,而分区的起始扇区是2048,因此,LVM数据根本不在分区内。这就是为什么磁盘上还有LVM元数据,系统却没有识别出来LVM的原因。
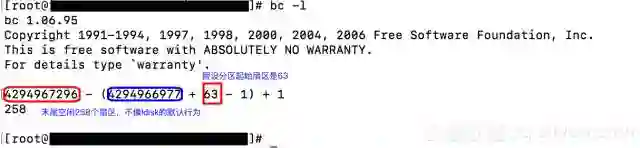
既然系统是因为有关LVM的元数据所在扇区不对而导致系统无法识别LVM结构,设想通过重新分区,我们把有关LVM元数据调整到分区的第8个扇区。稍加计算,就会发现,只要把分区的起始扇区从第2048个扇区调整到第63个扇区即可。不仅如此,通过调整分区大小,我们同样也解决了磁盘分区扇区数不足的问题
数据恢复
较新的fdisk工具,不允许起始扇区小于2048,因此,我们用parted工具来调整分区的起始扇区。
调整过程是先删掉扇区,而后再创建之。而结果正如我们所预期的,分区调整完成,客户的数据立刻恢复了。物理卷、卷组、逻辑卷、文件系统以及数据,都完好无损。
结语
从处理这个实际case可以看出,如果知道如何识别各层元数据,比如分区,LVM和文件系统;能够追踪系统处理各层元数据的逻辑,那么,组合使用UNIX常用的dd、od等工具,足以简单有效的处理元数据损坏的情形,快速恢复数据。如果掌握了常见的系统调用,并且掌握了strace工具,那么对于如何识别元数据以及系统如何处理元数据,完全可以通过简单分析strace输出拿到相应答案。
除了易学、简单、快捷、高效,元数据修复方案还有一个优点,就是可以确保不会破坏数据。这可能是这个方案的最大亮点。
往期精彩文章
0. 程序日志处理挑战与方案
-END-

云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维

点击“阅读原文”




