论文浅尝 | 神经协同推理
论文笔记整理:叶橄强,浙江大学计算机学院,知识图谱和知识推理方向。

Paper link:
https://arxiv.org/abs/2005.08129
Github link:
https://github.com/Scagin/NeuralLogicReasoning
背景:推荐任务
推荐作为一种认知智能任务(Cognition Intelligent Task)而非感知智能任务(Perception Intelligent Task),不仅需要数据的模式识别和匹配能力,还需要数据的逻辑推理能力。因此,本文的核心思想是在可微神经网络和符号推理之间建立桥梁,前者对应于模式识别和匹配能力,后者对应于逻辑推理能力,然后使这两者在共享体系结构中进行优化和推理。
例如,在某个真实场景中,用户曾经购买了一台笔记本电脑。对于用户而言,他更有可能在未来购买更多有关笔记本电脑的配件,例如笔记本电脑包等,而不是希望继续购买类似的笔记本电脑。在这个例子中,「用户希望购买笔记本电脑配件」的行为需要通过逻辑推理才能够得到,这是符合真实场景的用户需求的推荐;如果只是运用简单的模式识别和匹配,很可能得到「用户希望购买类似的笔记本电脑」这样错误的预测。如下图所示。

图1用户购买笔记本电脑的示例图
协同过滤(Collaborative Filtering, CF)是推荐系统的一种重要方法,该算法能够根据用户以前的记录预测用户未来的偏好,其中的相似度匹配函数是人工设计定义的。早期的协同过滤算法,例如基于用户的和基于项目的协同过滤算法,将原始用户项目评分矩阵中的行和列向量作为用户和项目的表示向量(即嵌入向量),利用人工设计的加权平均函数作为匹配函数f(·),计算出每个用户u与商品候选项v之间的关联度。具体如图2(a)所示,其中u表示用户,v表示商品。
更多研究进一步探索了协同过滤算法。其中一种方法是学习更好的嵌入,将时间和位置等上下文信息加入其中来学习信息嵌入,或者加入文本、图像或者知识图谱等各种异构信息源来丰富嵌入向量;另一种方法是使用更好的匹配函数。例如,用向量平移代替内积进行相似性匹配,或基于度量学习在线性空间中学习距离函数,甚至基于神经网络学习非线性空间中的通用匹配函数。参考图2(b),其中a、b、c表示加入的更加丰富的信息。
但是,本论文认为,推荐作为一种认知任务而非感知任务,不仅需要模式学习和匹配的能力,还需要认知推理的能力,因为用户未来的行为可能不仅仅是由其与用户先前行为的相似性驱动的,而是由用户的认知推理程序决定下一步该做什么。因此本论文提出了新的思路,将每个用户的行为记录视为一个逻辑蕴涵规则,然后将逻辑表达式等价地转换为基于逻辑神经模块的神经体系结构,最后将可微神经网络和符号推理这两者在一个共享的体系结构中进行优化和推理。参考图2(c),引入了逻辑推理运算。
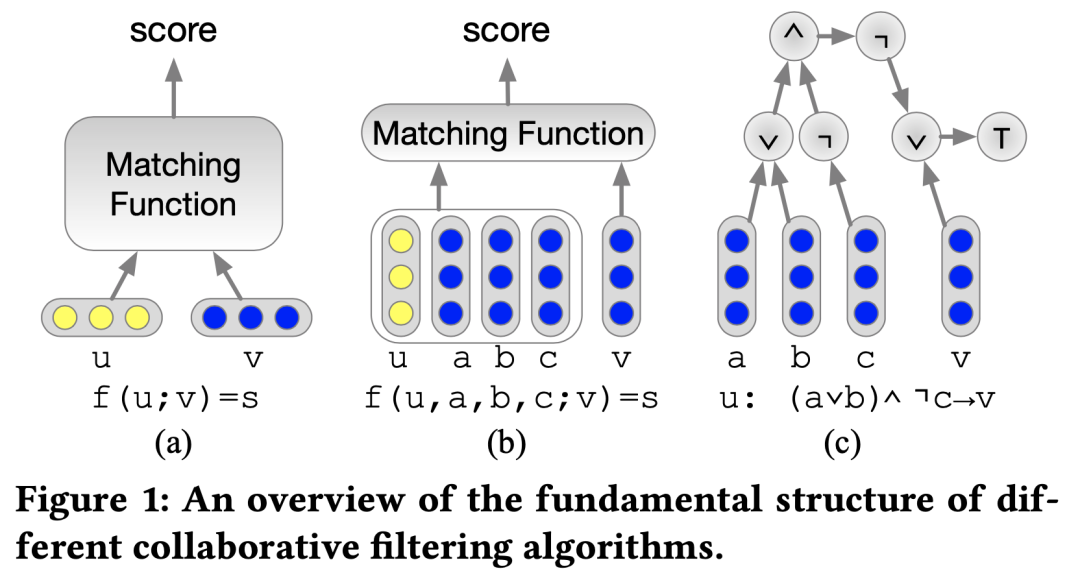
图2不同的协同过滤算法框架结构比较图
概述
首先,本文模型利用模块化逻辑神经网络(Modularized Logical Neural Networks, MLNN)在共享架构中集成了嵌入学习和逻辑推理的能力。其次,逻辑正则化器(Logical Regularizer)学习每一个基本的逻辑运算,包括:AND与(∧)、OR或(∨)、NOT非(∨)。一个感知任务R。然后,推荐问题可以形式化为在给定用户先前行为的情况下,估计未来行为v为真的概率,每个用户的行为记录被视为一个逻辑蕴涵规则,如(a∨b)∧c→v。最后,基于命题逻辑推理规则,将逻辑表达式(用户先前的行为)归结为评估正确或错误(T/F)问题。
本文的主要贡献如下:
1.提出了一种新的神经逻辑推荐框架,将符号逻辑推理和连续嵌入学习联系起来。
2.引入了逻辑正则化器作为约束来规范神经网络的行为。
3.根据给定的逻辑表达式动态构造网络结构,使逻辑先验加入到神经网络结构中。
4.实验部分,在几个真实的推荐数据集上进行实验,以分析和评估框架的行为,并得到不错的结果。
方法
本文方法分为四个步骤:首先,利用反馈推理(Reasoning with Feedback),将推荐任务形式化为一个逻辑推理问题;其次,利用逻辑模块(Logical Module),根据给定的逻辑表达式,将逻辑运算动态组合成神经网络;接着,利用逻辑正则化器(Logical Regularizer), 对神经模块的行为进行正则化约束,使之按照预期的逻辑规则进行运算;最后,运用特定的学习算法,来训练整个逻辑神经网络模型。
1.反馈推理
反馈推理(Reasoning with Feedback)分为隐式反馈推理和显式反馈推理。
(1)对于隐式反馈推理(Reasoning with Implicit Feedback),只知道用户是否与某个项目交互,而不知道用户是否喜欢该交互项目。假设一个用户的交互历史是项目a、b和c(,那么推荐项目v与否的问题就归结为判断以下蕴涵语句是真是假的问题:
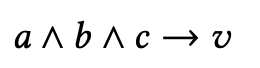
在表达式中,逻辑变量a表示“用户喜欢项目a”的事件,而¬a表示“用户不喜欢项目a”的事件。因此,通过将每个变量都代表一个命题,我们就能够对这些变量进行命题推理,使用简单的合取逻辑表达式来判断用户先前的行为是否意味着用户喜欢一个新的项目v。。
基于蕴含表达式的定义(x → y ⇔ ¬x ∨ y),上述逻辑表达式可以仅使用基本逻辑运算和(∧)、或(∨)、非(¬)来表达:
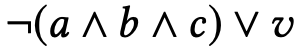
然后基于德摩根定律的定义(¬(x ∧ y) ⇔ ¬x ∨ ¬y 和¬(x ∨ y) ⇔ ¬x ∧ ¬y),该表达式可以进一步改写为:
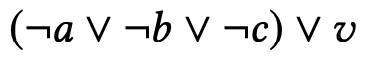
以上介绍了将推荐问题转化为一个基于隐式反馈的推理问题,但是用户的个性化信息没有被编码到推理过程中。在下面,我们进一步将项目扩展到事件以进行个性化推荐。
对于用户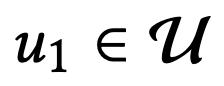
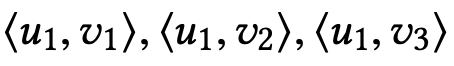
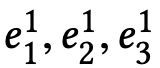
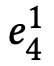
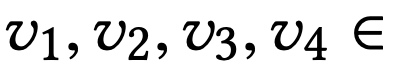
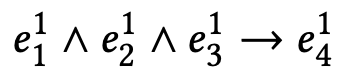
同理,该表达式可以进一步改写为
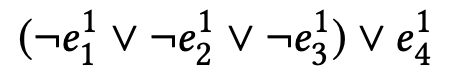
(2)显式反馈推理(Reasoning with Explicit Feedback)
有时用户不仅会与项目交互,还会告诉我们该用户是否喜欢该项目,即显式反馈。该论文将这些显式反馈引入到逻辑推理过程中,能够提升模型的表达能力。
将隐式反馈中的事件eij定义进一步扩展,表示用户对交互项目的态度。具体地说,我们使用eij来表示用户ui与项目vj的交互具有正反馈,并使用¬eij来表示用户ui与项目vj的交互具有负反馈。表达式与之前相同,因此不再赘述。
2.逻辑模块
逻辑模块(Logical Module)使用多层感知器(Multi-Layer Perceptron, MLP)网络,将用户和项目的交互作用编码为事件向量。下面的等式显示了使用两层神经网络将一对用户和项目向量编码为一个事件向量:
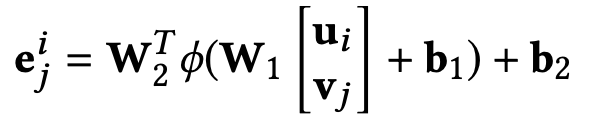
其中,ui、vj为随机初始化的用户向量和商品向量,W1、W2为权重矩阵,b1、b2为偏差项,eij为编码事件的向量,φ(·)为校正后的线性单元(ReLU)激活函数。
利用上式定义的事件向量,可以构建神经体系结构。我们将每个逻辑运算∧,∨, ¬,表示为一个神经模块AND(·, ·),OR(·, ·),NOT(·),而其中的每个神经模块都是一个多层感知器网络。例如,AND(·, ·)模块以两个事件向量e1和e2作为输入,输出一个新的事件嵌入,表示e1和e2同时发生的事件。基于这些定义,前面部分中描述的表达式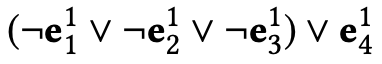
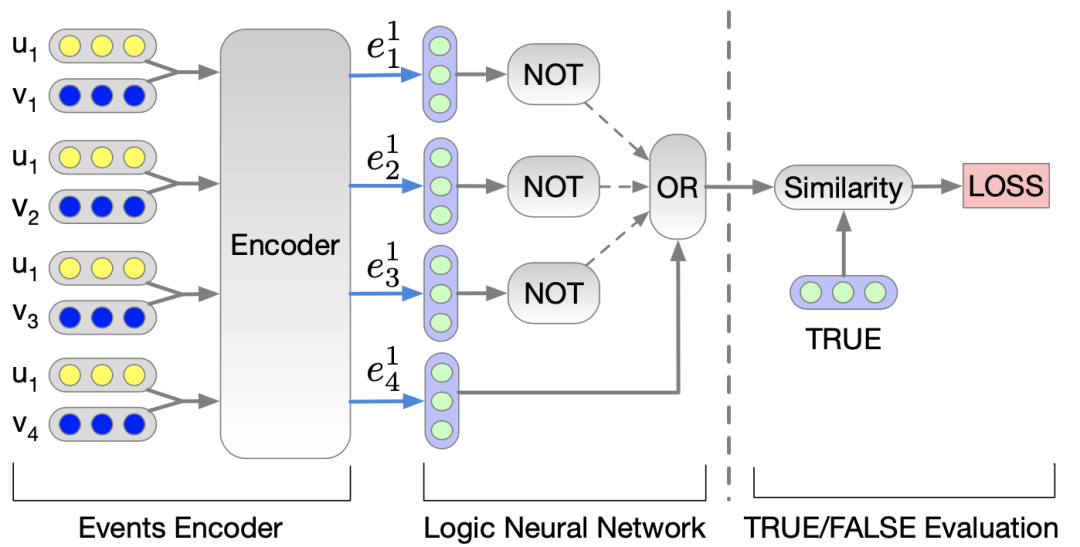
图3神经逻辑推理NLR框架的实施。带有黄色和蓝色圆圈的灰色框分别表示用户向量和商品向量;带绿色圆圈的蓝色框表示逻辑空间中的事件向量;编码器是对用户-商品交互进行编码的多层神经网络;NOT和OR是神经逻辑模块;虚线箭头表示编码事件的顺序在每轮随机洗牌。
为了确定表达式是否表示真或假,我们检查最终事件向量是否接近逻辑空间中的常量真向量T(True)。真向量T是一个随机初始化的锚向量,为逻辑空间中所有高维潜在向量建立了基础,并且在初始化之后永远不会被更新。如果一个向量代表真,那么这个向量应该接近这个真向量,否则它应该远离这个真向量。该论文中使用了余弦相似度函数进行度量:
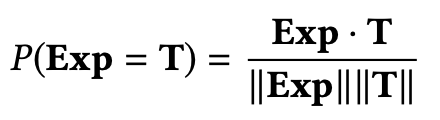
由于变量的数量(即交互作用)因用户和而异,逻辑表达式的长度和结构也会有所不同。因此,对于不同的用户神经网络的结构是不同的,根据输入表达式进行动态组装。
3.逻辑正则化器
为了保证每个逻辑模块在向量空间中,按照预期的逻辑表达式执行逻辑操作,该论文的方法在神经模块中加入逻辑正则化器(Logical Regularizer)来约束它们的行为。
让x表示一个事件嵌入,它可以是原始用户项交互事件,也可以是逻辑神经网络计算过程中的任何中间事件,也可以是逻辑表达式的最终事件嵌入。设X是所有事件嵌入的集合,Sim(·, ·)是一个相似度函数。如前所述,T是表示True的常量向量,在模型学习过程中随机初始化且从不更新;F是表示False的向量,通过NOT(T)运算得到。
以双重否定法则为例来说明逻辑正则化器的基本思想。对于NOT(·)模块在向量空间进行求反运算,我们要求它满足双重否定法则:
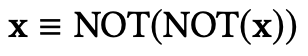
该法则表示,任何经过两次否定运算的事件向量都应该返回自身向量。为了约束求反模块的行为,我们设计了一个正则化器来最大化NOT(NOT(x))和x的输出之间的余弦相似性,这相当于最小化:
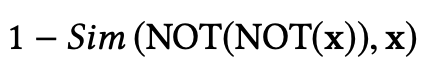
为了确保神经模块不仅可以对初始输入事件向量执行相同的操作,而且可以对所有中间隐藏事件和最终事件执行相同的操作,我们将正则化器应用于逻辑空间中的所有事件嵌入X,这给了我们双反律的最终正则化器:
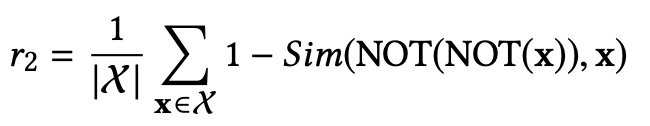
其中 |X| 是整个事件空间的大小。通过类似的方式,可以对所有逻辑表达式法则构建正则化器,如表所示:
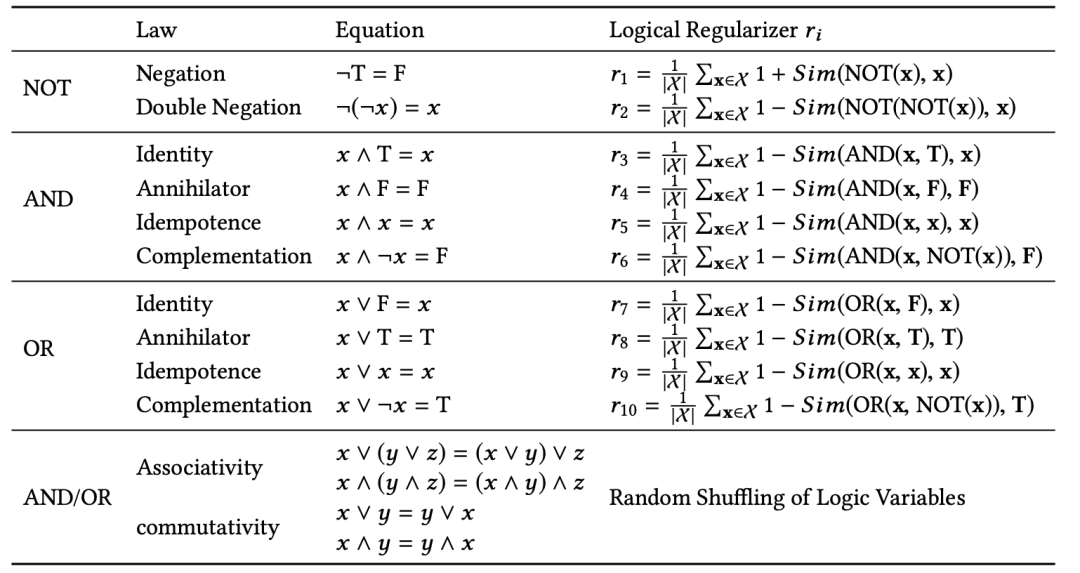
表1 每个逻辑模块应该满足的逻辑法则和相应的表达式
值得注意的是,对于否定定律的正则化器,在这里是进行1 + sim() 操作而不是1 - sim() 操作,因为我们希望最大化NOT(x)和x之间的距离。
于是,根据正则化器的定义,得到这个部分的损失函数
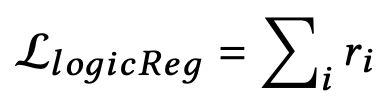
当然,因为结合律和交换律不容易表示为正则化器,所以为了约束这两个逻辑法则,该论文的解决办法是在每次迭代过程中随机地改变输入事件的顺序,使学习到的AND和OR模块满足这两个法则。
4.学习算法(Learning Algorithm)
该论文使用成对学习算法进行模型训练。具体来说,我们在训练过程中对每个给定的表达式进行负采样。假设我们知道用户ui在项目vi之前与项目vi−1、vi−2、vi−3交互。然后我们可以抽样另一个用户没有互动的项目vj。在此基础上,我们用以下两个表达式构建结构化神经网络:
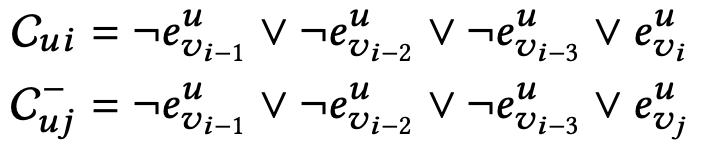
其中C代表正负样例的表达式。
紧接着,我们可以得到一对真实性评价结果:
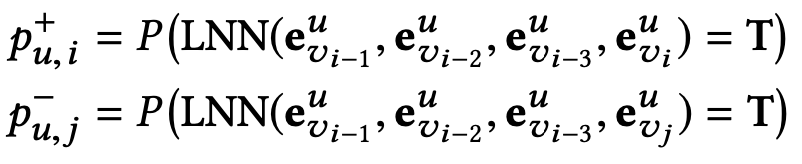
其中LNN是上文所述的逻辑神经网络结构。
然后我们计算
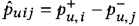
来表示这两个表达式之间的差异,并应用一个优化算法来最大化这个差异。。我们使用V−来表示负样本集,并且V−⊂V。
损失函数可以表示为:
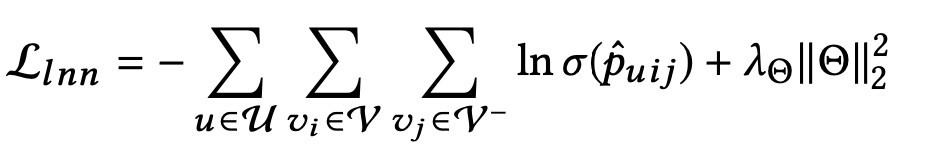
式中,Θ表示模型的参数向量,λΘ是模型参数的Frobenius范数的权重,σ(·)是logistic sigmoid函数。
将逻辑正则化器与我们的成对学习损失结合起来,得到最终的损失函数:
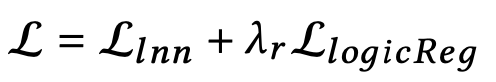
其中λr是逻辑正则化器的权重。论文中对所有的逻辑正则化器应用相同的权重,因为它们对于正则化模型的逻辑行为同样重要。
实验
1.数据集
该论文主要使用了以下两个数据集:
(1)ML100k:一个流行的数据集包括100000部电影的收视率;
(2)Amazon 5-core:亚马逊电子商务数据集,包括用户、商品和评级信息,涵盖24个不同的类别。本论文中只使用电影和电视,以及电子产品这两个类别的数据集。
2.评价指标
主要利用以下两个指标来评价模型的top-K推荐性能:
(1)前K个标准化折现累积收益(Normalized Discounted Cumulative Gain at rank K,NDCG@K)。该指标主要衡量前K个预测序列中,越靠前的预测值是否与真实结果越接近。
(2)前K个命中率(Hit Ratio at rank K, HR@K)。该指标主要衡量前K个预测序列中,预测正确的预测值的比例。
3.基准方法
为了检验论文中所提出的神经逻辑推荐模型的有效性,与两种传统的浅层方法(Biased-MF和SVD++)、两种深层模型(DMF和NeuMF)以及两种基于会话的模型(GRU4Rec和STAMP)进行了比较。
4.实验一:评估神经逻辑推理NLR框架的性能
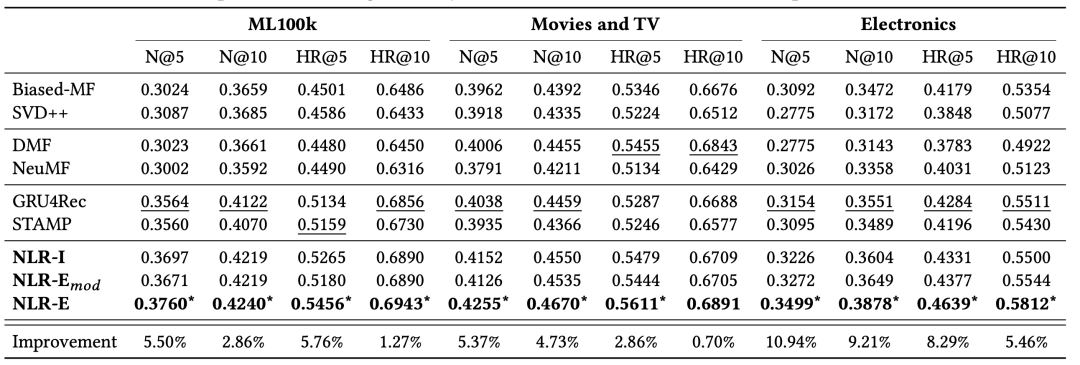
表2 三个数据集的NDCG (N)和命中率Hit Ratio (HR)指标结果
为了评估神经逻辑推理NLR框架的性能,该论文展示了表2中所有数据集的结果,包括NDCG和命中率HR。表格中,NLR-I表示以隐式反馈作为输入的模型,而NLR-E表示以显式反馈为输入的模型;表格最后一行表示,该论文的模型在之前最好效果的基准方法之上,评价指标进一步提升的百分比。结果表明,该论文提出的模型始终优于所有的比较方法。通过比较发现,基于浅矩阵分解的算法(Biased-MF和SVD++)在大多数度量上都具有相似的性能,而深度神经模型如DMF和NeuMF在某些任务上也能达到合理的性能。
由于该论文的模型使用了用户历史交互信息,因此将其与基于会话的推荐方法进行比较是更有意义。对于GRU4Rec和STAMP方法,他们都使用隐式反馈来训练模型并利用序列信息。为了公平起见,将本论文中的隐式模型NLR-I与两个基线方法进行了比较。报告的数据表明,我们的模型能够与基于会话的模型进行竞争,并且在本文的逻辑神经网络在使用较少信息的情况下,仍然可以明显优于其他两个基于会话的模型
5.实验二:论证逻辑正则化器的有效性
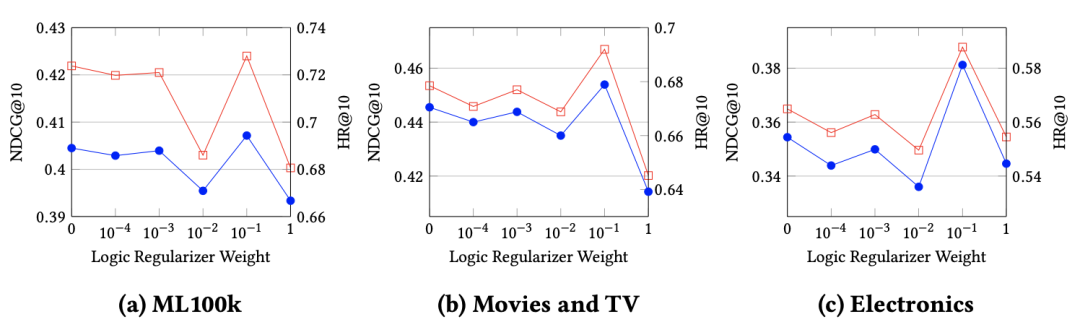
图4两项指标NDCG@10(红色折线)和Hit@10(蓝色折线)根据逻辑正则化器权重参数λr的变化图
从图4(a)-(c)中可以看出,将逻辑正则化器的权重λr赋值为0.1将达到最佳性能。实验表明,将逻辑约束应用到神经网络中的确可以提高推荐性能,但是这些逻辑约束的权重需要仔细调整。无论约束太弱或太强,都会对推荐模型的性能产生负面影响。
在表2中,NLR-Emod显示了我们的显式反馈模型在不使用逻辑正则化器(即λr=0)的情况下的性能。通过比较NLR-Emod和NLR-E,可以看出使用逻辑正则化器可以提高推荐性能。
6.实验三:论证结构中的逻辑先验的有效性
本论文提出的逻辑神经网络结构具有两个重要特征:模块化和逻辑正则化。模块化是指根据逻辑表达式动态地组装神经结构。每个网络模块负责一个特定的操作,整个网络结构在逻辑表达式上各不相同。因此在训练和测试过程中,不同的用户和项目交互历史会导致不同的网络结构,这与传统的网络结构静态的深度学习模型有很大的不同。
正如前文中提到的,同样的逻辑语句可以写成逻辑上相同但实际上字符不同的表达式,不同的表达式将导致我们模型中不同的网络结构。前面的建模和实验是使用了两个逻辑运算(¬, ∨)表达式来构建网络结构,在这里探索使用其他逻辑上相同但实际上不同的表达式来构建网络结构,会对实验结果产生什么影响。
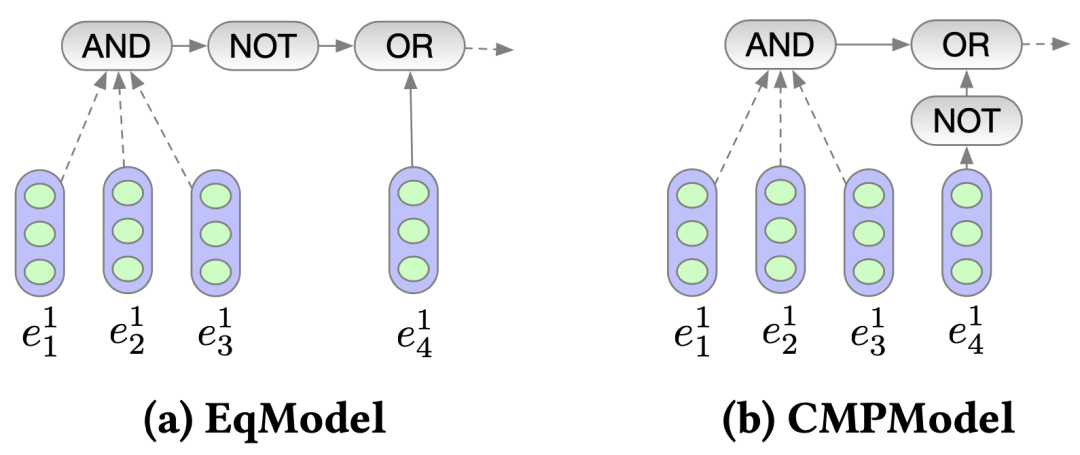
图5 遵循逻辑优先级(a)和违反逻辑优先级(b)的网络结构之间的比较
论文定义了两种不同的网络结构来进行对比说明。一种是逻辑等价模型(Equivalent Model, EqModel),即仍然使用逻辑表达式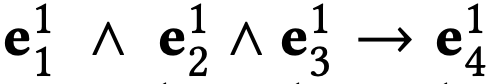
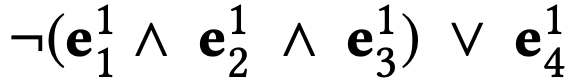
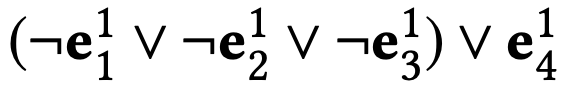
另一个模型是逻辑上不等价的模型,称为比较模型(Comparative Model, CMPModel)。我们应用逻辑表达式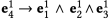
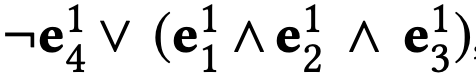
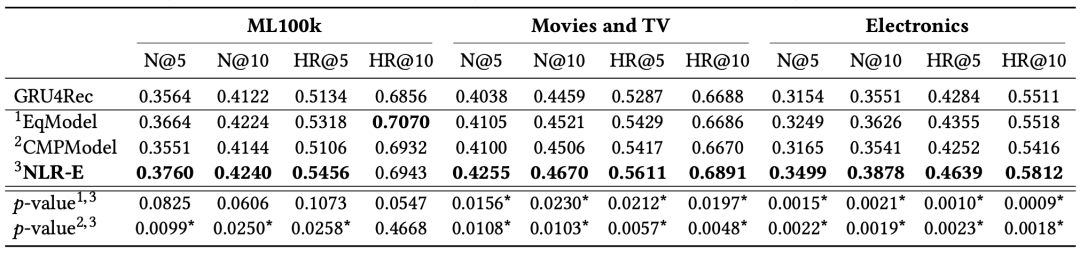
表3 不同逻辑结构下的评分排名
从表3的结果中我们有两个关键的观察结果。首先,我们看到NLR-E和EqModel始终优于GRU4Rec方法,而CMPModel通常并没有明显地优于GRU4Rec方法。此外,CMPModel比原来的NLR-E模型差得多,说明正确合理的逻辑结构对模型的性能至关重要。
另一个观察结果是比较NLR-E和EqModel。通过观察两个模型之间的p值,我们发现这两个模型在ML100k数据集上具有可比性(即NLR-e并不明显优于EqModel),而NLR-E在两个Amazon数据集上确实明显优于EqModel。造成这种结果的根本原因可能来自两个因素,分别是模型的复杂性和数据的充分性。就数据集本身的特征而言,MovieLens数据集比Amazon数据集密集2个数量级。由于NLR-E和EqModel在逻辑上是等价的,所以当训练数据足够时,它们可以获得不相上下的性能。然而,NLR-E只需要训练两种逻辑操作的神经模块 (¬, ∨),而EqModel需要训练三个逻辑操作的神经模块(¬, ∧, ∨),因此EqModel比NLR-E具有更高的模型复杂度,因此在训练数据稀疏的情况下,NLR-E可以获得更好的性能。
这部分实验证明,对于一个特定的任务使用一个合理的逻辑先验表达式是很重要的。当存在多个逻辑等价结构时,使用更简单的网络结构(即更少的模块)而不是复杂的网络结构,往往能够有更好的实验效果。
7.实验四:探索布尔逻辑建模
在本论文提出的模型并没有对事件向量进行约束,因此它们可以被学习为逻辑空间中的灵活向量表示。在本实验中,尝试将任何事件向量都只能是为T向量或F向量的约束条件,来探讨是否可以基于布尔逻辑对推荐任务进行建模。
首先拼接用户向量u和项目向量v,并将其输入到编码器网络中。在进一步将编码事件向量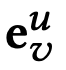
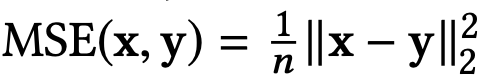
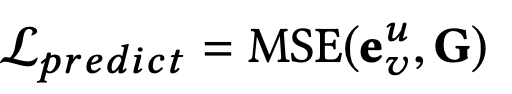
其中G代表基本真实向量,即T向量或F向量,取决于用户对该项的喜欢或不喜欢该项目。然后,我们将该损失加到模型损失函数中,以获得以下新的损失函数:
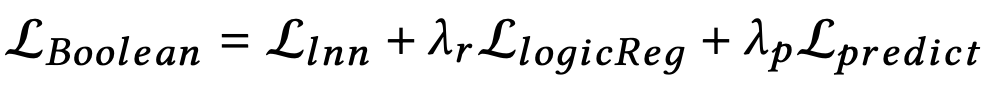
式中,λp是预测损失的权重。通过加入这个损失,模型试图将事件向量两极化为T向量或者F向量。
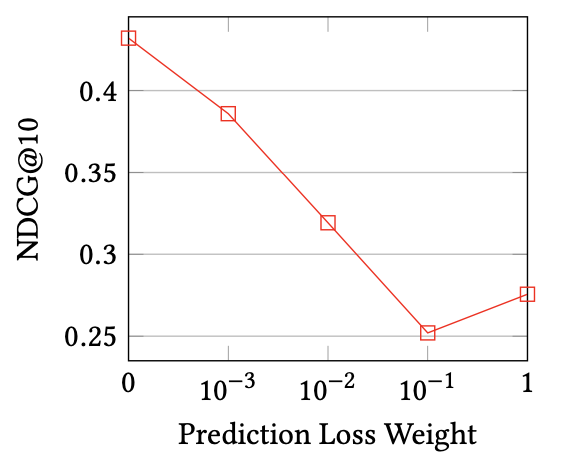
图6在ML100k数据集上,改变不同损失权重λp的增加对指标NDCG@10的影响
从实验结果可以看出,随着预测损失权重的增加排序性能显著下降。较大的λp会限制潜在嵌入的表达能力,进而限制逻辑神经网络对推荐任务进行正确建模的能力。实验表明,在逻辑空间中将嵌入学习的能力融入到逻辑推理中,对于精确决策是非常重要的
总结
本文提出了一种新的神经逻辑推荐(NLR)框架,能够将逻辑结构和神经网络相结合,将推荐任务转化为一个逻辑推理任务。实验表明,相较于以往的基准方法,该论文提出的方法在推荐任务上有显著的改进。
文章中进行了进一步的实验,根据不同的实验设置下,探索该模型为什么能获得良好的性能。实验结果表明,适当的逻辑正则化有助于提高推荐性能。在推荐系统引入可解释性可以使得决策过程更加透明。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



