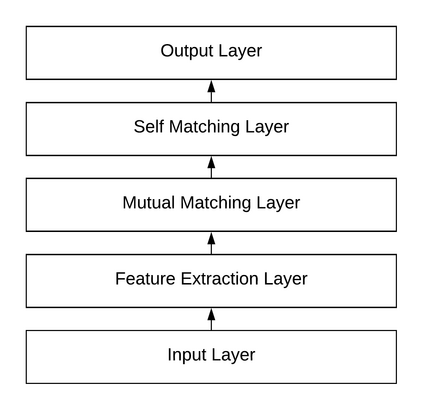
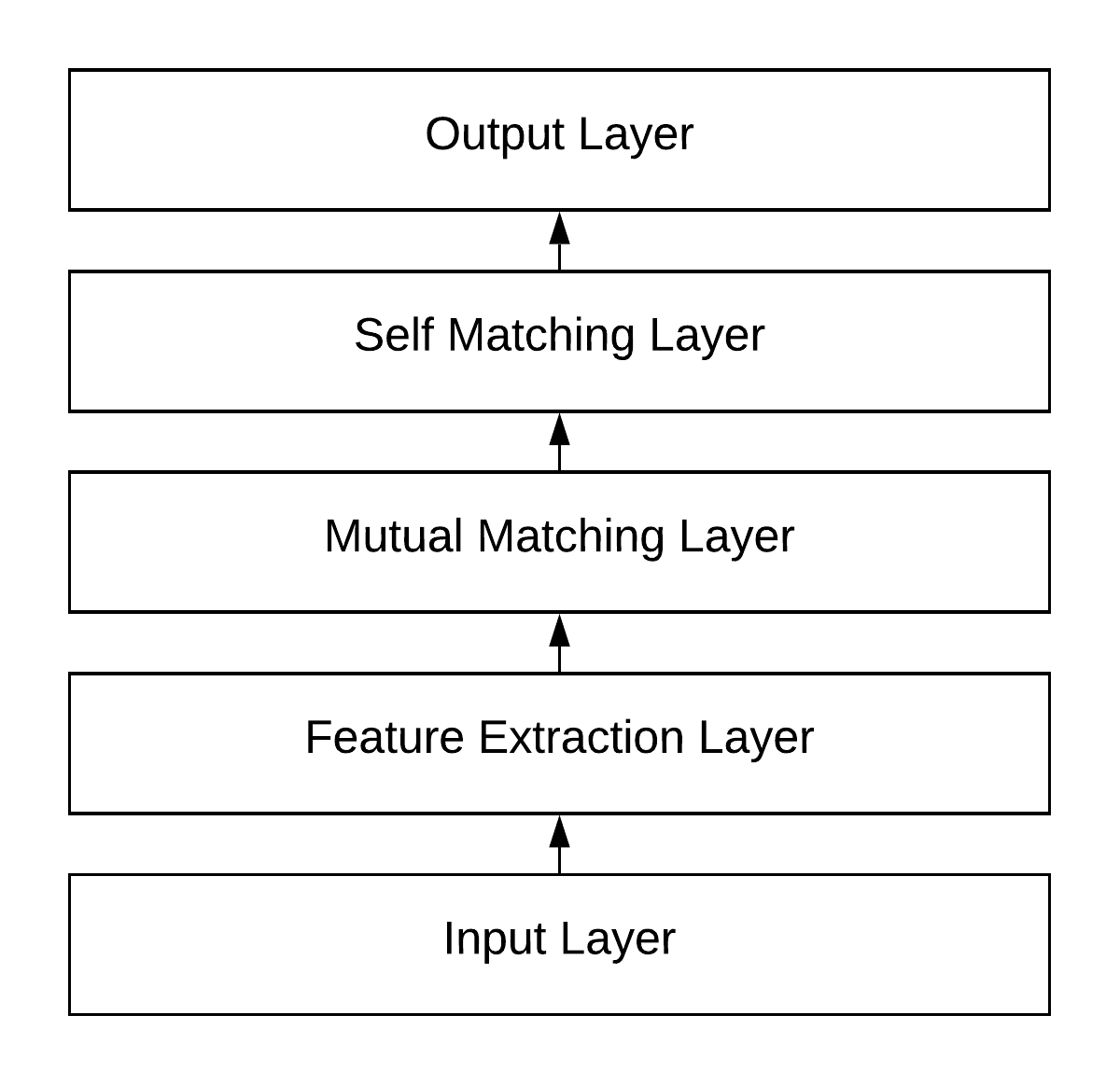
To provide a survey on the existing tasks and models in Machine Reading Comprehension (MRC), this report reviews: 1) the dataset collection and performance evaluation of some representative simple-reasoning and complex-reasoning MRC tasks; 2) the architecture designs, attention mechanisms, and performance-boosting approaches for developing neural-network-based MRC models; 3) some recently proposed transfer learning approaches to incorporating text-style knowledge contained in external corpora into the neural networks of MRC models; 4) some recently proposed knowledge base encoding approaches to incorporating graph-style knowledge contained in external knowledge bases into the neural networks of MRC models. Besides, according to what has been achieved and what are still deficient, this report also proposes some open problems for the future research.
翻译:为了对机器阅读综合体(MRC)的现有任务和模式进行调查,本报告审查了:(1) 数据收集和业绩评价,以了解某些具有代表性的简单理由和复杂理由的MRC任务;(2) 设计建筑设计、关注机制和增强性能的方法,以开发以神经网络为基础的MRC模型;(3) 最近提出的一些转让学习方法,以便将外部公司体中包含的文字风格知识纳入MRC模型神经网络;(4) 最近提出的一些知识基础编码方法,将外部知识库中包含的图表式知识纳入MRC模型神经网络;此外,根据已经取得的成就和仍然存在的不足,本报告还提出一些有待今后研究的未决问题。