PySpark和大数据处理初探

由于数据量太大而不能在一台机器上进行处理这样的情况已经越来越常见了。幸运的是,已经有Apache Spark、Hadoop等技术被开发出来,去解决这个确切的问题。这些系统的强大功能可以直接在Python中使用PySpark来发掘!
有效地处理GB及以上级别的数据集是任何Python开发者都应该会的,无论你是一个数据科学家、web开发人员还是介于两者之间的任何人员。
在本教程中,你将学习:
什么Python概念可以被应用于大数据
如何使用 Apache Spark 和PySpark
如何编写基本的PySpark程序
如何在本地对小型数据集运行PySpark 程序
将你的PySpark技巧应用到分布式系统的指南
免费福利: 点击这里访问《Python技巧》中的一章:这本书向你展示了Python的最佳实践和一些简单的例子,你可以立即应用这些例子来编写更漂亮的Python式代码。(https://realpython.com/pyspark-intro/ )
Python中的大数据概念
尽管Python只是一种流行的脚本语言,但是它提供了几种编程范式,比如面向数组编程、面向对象编程、异步编程等等。对于有抱负的大数据专业人士来说,函数式编程是一个特别有趣的范式。
在处理大数据时,函数式编程是一种常见的范例。以函数的方式进行编写会生成高度并行的代码。这意味着将你的代码在多个CPU上或者甚至完全不同的机器上运行要容易的多。你可以同时在多个系统上运行你的代码,这样就可以绕过单个工作站的物理内存和CPU限制。
这就是PySpark生态系统的强大功能,它允许你获取函数代码并将其自动分布到整个计算机集群中。
幸运的是,Python程序员可以在Python的标准库和内置程序中使用函数式编程的许多核心思想。你可以学习大数据处理所需的许多概念,而不必离开Python的舒适环境。
函数式编程的核心思想是数据应该由函数进行操作,而不需要维护任何外部状态。这意味着你的代码避免了全局变量,并且总是会返回新数据,而不是原地操作数据。
函数编程中的另一个常见概念是匿名函数。Python使用lambda关键字定义匿名函数,不要与AWS lambda函数相混淆。
现在你已经了解了一些术语和概念,你可以探索这些思想在Python生态系统中是如何体现的。
Lambda 函数
Python中的lambda函数是内联定义的,并且仅限于一个表达式。在使用内置的sorted()函数时,你可能已经见过lambda函数了:
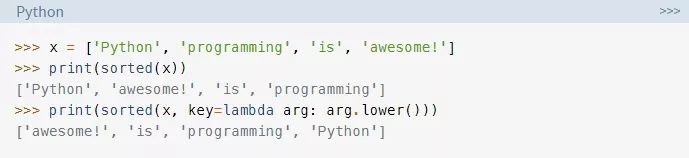
sorted函数的key参数会被调用来获取iteranle(迭代)中的每个项。这使得排序不区分大小写,方法是在排序之前将所有字符串变为小写。
这是lambda函数的一个常见用例,它是一些小的匿名函数,不维护任何外部状态。
Python中还存在其它常见的函数式编程函数,如filter()、map()和reduce()。所有这些函数都可以使用lambda函数或使用def以类似的方式定义的标准函数。
filter(), map()和 reduce()
内置的filter()、map()和reduce()函数在函数式编程中都很常见。你很快就会看到,这些概念可以构成一个PySpark程序功能的重要部分。
在一个核心Python上下文中理解这些函数非常重要。然后,你就可以将这些知识转换为PySpark程序和Spark API。
filter()根据条件过滤一个iterable,通常会被表示为一个lambda函数:

filter()接受一个iterable,对每个项调用lambda函数,并返回lambda返回True的项。
注意: 调用list()是必需的,因为filter()也是一个迭代. filter()只在你循环遍历它们时才给出值。list()会将所有项强制载入内存,而不是必须使用一个循环。
你可以想象使用filter()去替换一个常见的for循环模式,如下所示:
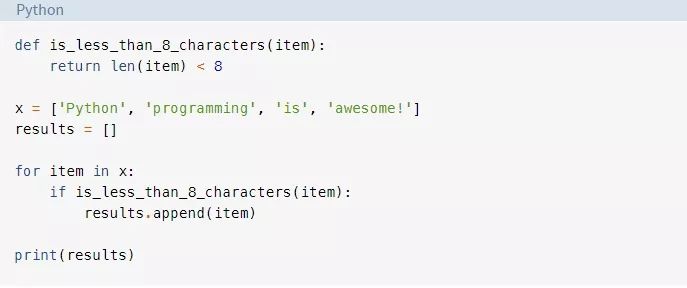
这段代码会收集所有少于8个字符的字符串。代码比filter()示例更冗长,但是它执行的是相同的函数,得到是相同的结果。
filter()的另一个不太明显的好处是,它会返回一个iterable。这意味着filter()并不需要你的计算机有足够的内存来同时保存iterable中的所有项。随着大数据集快速增长成几GB大小,这一点变得越来越重要。
map()类似于filter(),它也会对一个iterable中的每个项应用一个函数,只不过它总是生成原始项的一个1对1映射。map()返回的新iterable总是具有与原始iterable相同的元素数量,而filter()则不是这样:

map()会在所有的项上自动调用lambda函数,有效地替换了一个for循环,如下所示:
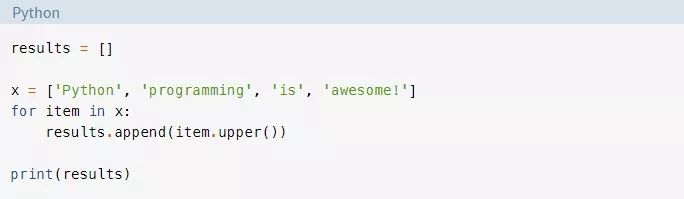
for循环的结果与map()示例相同,后者中收集了所有项的大写形式。但是,与filter()示例一样,map()会返回一个iterable,这再次使得它可以处理无法完全装入内存的大数据集。
最后,Python标准库中的函数三人组的最后一个函数是reduce()。与filter()和map()一样,reduce()会将一个函数应用于一个可迭代对象中的元素。
同样,所应用的函数可以是使用def关键字创建的标准Python函数,也可以是一个lambda函数。
但是,reduce()不会返回一个新的iterable。相反,reduce()会使用所调用的函数将该iterable缩减为单个值:

这段代码会将iterable中的所有项(从左到右)组合成一个单独的项。这里没有调用list(),因为reduce()已经返回了一个单独项目。
注意: Python 3.x将内置的reduce()函数移动到了functools包中。
lambda、map()、filter()和reduce()是存在于许多语言中的概念,可以在常规Python程序中使用。很快,你将看到这些概念会扩展到PySpark API来处理大量数据。
集合
Set是标准Python中存在的另一种常见功能,并在大数据处理中广泛使用。集合与列表非常相似,只是它们没有任何顺序,并且不能包含重复的值。你可以将集合看作类似于Python字典中的键。
PySpark Hello World示例
与在任何优秀的编程教程中一样,你都希望从一个Hello World示例开始。以下是等效的PySpark示例:
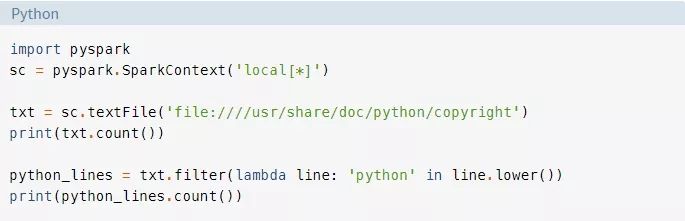
不要担心所有的细节。其主要思想是要记住,PySpark程序与常规的Python程序并没有太大的不同。
注意: 如果你还没有安装PySpark或没有指定的copyright文件,这个程序可能会在你的系统上引发一个异常,稍后你将看到如何处理它。
你很快就会了解到这个项目的所有细节,但是要好好看看。该程序会计算一个名为copyright的文件的总行数和包含单词python的行数。
请记住,一个PySpark程序与一个常规Python程序并没有太大的不同,但是执行模型可能与常规Python程序非常不同,特别是当你在集群上运行时。
如果你是在一个集群上,可能会有很多事情在幕后发生,这些事情会将处理过程分布到多个节点。但是,现在来说,你可以将该程序看作是一个使用了PySpark库的Python程序。
既然你已经了解了Python中存在的一些常见函数性概念,以及一个简单的PySpark程序,现在是深入了解Spark和PySpark的时候了。
Spark是什么?
Apache Spark由几个组件组成,因此我们很难描述它。从其核心来说,Spark一个是处理大量数据的通用引擎。
Spark是用Scala编写的,运行在JVM上。Spark内置了处理流数据、机器学习、图形处理甚至通过SQL与数据交互的组件。
在本指南中,你将只了解处理大数据的核心Spark组件。然而,所有其它组件,如机器学习、SQL等,也都可以通过PySpark在Python项目中使用。
PySpark是什么?
Spark是用Scala实现的,Scala是一种运行在JVM上的语言,那么,我们如何通过Python来访问所有这些功能?
PySpark就是答案。
PySpark的当前版本是2.4.3,可以用于Python 2.7、3.3及以上版本。
你可以将PySpark看作是在Scala API之上的一个基于Python的包装器。这意味着你有两套文档可以参考:
PySpark API文档
Spark Scala API文档
PySpark API文档中有一些示例,但通常你希望参考Scala文档并将你的PySpark程序的代码转换为Python语法。幸运的是,Scala是一种非常易读的基于函数的编程语言。
PySpark通过Py4J库与Spark 基于Scala的API进行通信。Py4J不是特定于PySpark或Spark的。Py4J允许任何Python程序与基于JVM的代码进行对话。
PySpark基于函数式范式有两个原因:
Spark的母语言Scala是基于函数式的。
函数式代码更容易并行化。
你还可以将PySpark看作是一个允许在单个机器或一组机器上处理大量数据的库。
在一个Python上下文中,PySpark可以处理并行进程,而不需要threading 或者 multiprocessing模块。所有线程、进程甚至不同CPU之间的复杂通信和同步都由Spark处理。
PySpark API和数据结构
要与PySpark进行交互,你需要创建被称为弹性分布式数据集(RDDs)的专用数据结构。
如果你的程序运行在集群上,RDDs将通过一个调度程序在多个节点上自动转换和分发数据,从而隐藏所有的复杂性。
为了更好地理解PySpark的API和数据结构,请回忆一下我们前面提到的Hello World程序:
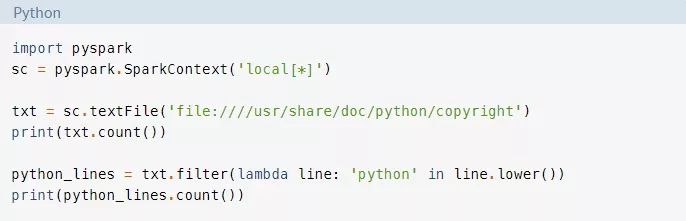
任何PySpark程序的入口点都是一个SparkContext对象。此对象允许你连接到一个Spark集群并创建RDDs。local[*]字符串是一个特殊的字符串,表示你正在使用一个本地集群,这是告诉你你是在单机模式下运行的另一种方式。这个*会告诉Spark在你的机器上创建与逻辑核心一样多的工人线程。
当你正在使用一个集群时,创建SparkContext可能会更加复杂。要连接到一个Spark集群,你可能需要处理身份验证和一些特定于集群的其它信息。你可以设置类似于下面的这些细节:
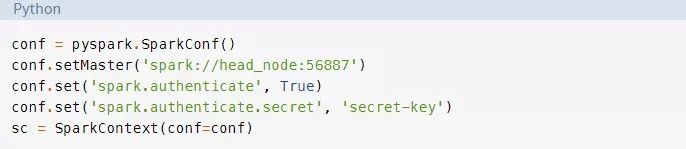
有了SparkContext之后,你就可以开始创建RDDs了。
你可以以多种方式来创建RDDs,但是一种普遍的方式是使用PySpark的 parallelize()函数。parallelize()可以将一些Python数据结构(如列表和元组)转换为RDDs,这为你提供了容错和分布式的功能。
为了更好地理解RDDs,我们考虑另一个例子。下面的代码会创建一个包含10,000个元素的迭代器,然后使用parallelize()将数据分布到2个分区中:

parallelize()将该迭代器转换为一组分布式数字,并为你提供Spark基础设施的所有功能。
注意,这段代码使用了RDD的filter()方法,而不是你前面看到的Python的内置filter()方法。结果是一样的,但幕后发生的事情却截然不同。通过使用RDD的filter()方法,该操作以分布式方式跨多个CPU或计算机进行。
同样,假设这是Spark正在为你执行multiprocessing工作,所有这些工作都封装在RDD数据结构中。
take()是一种查看你的RDD内容的方法,但只能看到一个小子集。take()会将该数据子集从这个分布式系统拖向一台机器。
take()对于调试非常重要,因为在一台机器上检查你的整个数据集可能是不可能的。RDDs被优化为用于大数据,因此在实际情况中,一台机器可能没有足够的RAM来保存你的整个数据集。
注意: 在shell中运行这样的示例时,Spark会临时将信息打印到stdout,稍后你将看到如何处理它。你的stdout可能会临时显示类似于 [Stage 0:>(0 + 1) / 1]的内容。
stdout文本展示了Spark如何分割RDDs并将你的数据处理为跨不同CPU和机器的多个阶段。
创建RDDs的另一种方法是使用textFile()读入一个文件,你在前面的示例中已经看到了该方法。RDDs是使用PySpark的基本数据结构之一,因此API中的许多函数都会返回RDDs。
RDDs与其它数据结构之间的一个关键区别是,它的处理过程会被延迟到结果被请求时才进行。这类似于一个Python生成器。Python生态系统中的开发人员通常使用术语延迟计算来解释这种行为。
你可以在同一个RDD上叠加多个转换,而不需要进行任何处理。这个功能是可能的,因为Spark维护了这些转换的一个有向无环图。只有在最终结果被请求时,底层图才会被激活。在前面的示例中,只有在你通过调用take()请求结果时才进行计算。
有多种方法可以从一个RDD中请求结果。通过在一个RDD上使用collect(),你可以显式地请求将结果进行计算并收集到单个集群节点中。你还可以通过各种方式隐式地请求结果,其中之一就是使用前面看到的count()。
注意: 使用这些方法时要小心,因为它们会将整个数据集拖放到内存中,如果数据集太大而无法放入一台机器的RAM中时,那么这些方法将无法使用。
同样,请参考PySpark API文档以获得关于所有可能的功能的更多细节。
安装PySpark
通常,你会在一个Hadoop集群上运行PySpark程序,但是选择在其它集群上进行部署也是支持的。你可以阅读《Spark的集群模式概述》来获取更多信息。
注意: 设置这些集群中的一个可能很困难,并且超出了本指南的范围。理想情况下,你的团队需要一些向导DevOps工程师来帮助实现这一点。如果没有,Hadoop发布的一个指南会帮助你。
在本指南中,你将看到在本地机器上运行PySpark程序的几种方法。这对于测试和学习是非常有用的,但是你很快就会希望将你的新程序运行在一个集群上来真正地处理大数据。
有时候,由于所有必需的依赖项,单独设置PySpark也很有挑战性。
PySpark运行在JVM之上,并需要许多底层Java基础设施才能运行。也就是说,我们生活在Docker时代,这使得使用PySpark进行实验变得更加容易。
更有甚者,Jupyter背后的优秀开发人员已经为你完成了所有繁重的工作。他们发布了一个Dockerfile,其中包括所有的PySpark依赖项以及Jupyter。因此,你可以直接在Jupyternotebook上进行实验!
注意:Jupyter notebook有很多功能。请查看《Jupyter notebook介绍》来获取更多有关如何有效使用notebook的详细信息。
首先,你需要安装Docker。如果你还没有设置好Docker,请查看《Docker 实战 – 更轻松、更愉快、更高效》。
注意: Docker镜像可能非常大,所以请确保你可以使用大约5GB的磁盘空间来使用PySpark和Jupyter。
接下来,你可以运行以下命令来下载并自动运行一个带有预置PySpark单节点设置的Docker容器。这个命令运行可能需要几分钟的时间,因为它直接从DockerHub下载镜像,以及Spark、PySpark和Jupyter的所有需求:

一旦该命令停止打印输出,你就有了一个正在运行的容器,其中包含了在一个单节点环境中测试PySpark程序所需的所有东西。
要停止容器,请在你键入docker run命令的同一窗口中按下Ctrl+C。
现在我们终于可以运行一些程序了!
运行PySpark 程序
有很多方法可以执行PySpark程序,这取决于你喜欢命令行还是更直观的界面。对于一个命令行界面,你可以使用spark-submit命令、标准Python shell或专门的PySpark shell。
首先,你将看到带有一个Jupyter notebook的更直观的界面。
Jupyter Notebook
你可以在一个Jupyter notebook中运行你的程序,方法是运行以下命令来启动你之前下载的Docker容器(如果它还没有运行):
现在你有一个容器来运行PySpark了。注意,docker run命令输出的末尾提到了一个本地URL。
注意: docker命令在每台机器上的输出会略有不同,因为令牌、容器ID和容器名称都是随机生成的。
你需要使用该URL连接到Docker容器来在一个web浏览器中运行Jupyter。将URL从你的输出中直接复制并粘贴到你的web浏览器中。下面是一个你可能会看到的URL的例子:

下面命令中的URL在你的机器上可能会略有不同,但是一旦你在你的浏览器中连接到该URL,你就可以访问一个Jupyter notebook环境了,该环境应该类似如下:
从Jupyter notebook页面,你可以使用最右边的New按钮来创建一个新的python3 shell。然后你可以测试一些代码,就像之前的Hello World例子一样:
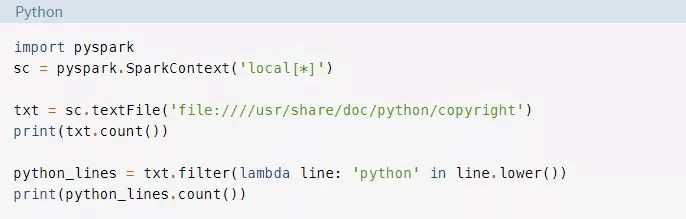
以下是在Jupyter notebook中运行该代码的样子:
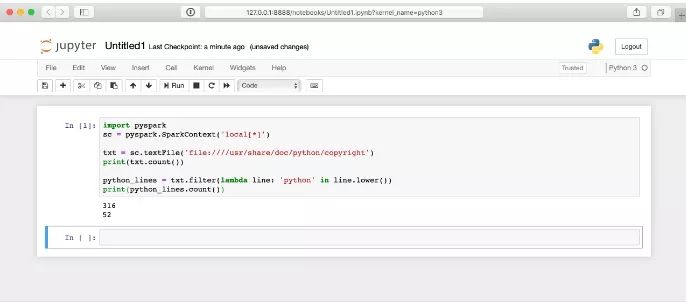
这里的幕后发生了很多事情,所以可能需要几秒钟的时间才能显示结果。在你单击单元格后,答案并不会立即出现。
命令行界面
命令行界面提供了多种提交PySpark程序的方法,包括PySpark shell和spark-submit命令。要使用这些CLI方法,你首先需要连接到安装了PySpark的系统的CLI。
要连接到Docker设置的CLI,你需要像以前那样启动容器,然后附加到该容器。同样,要启动容器,你可以运行以下命令:

运行Docker容器后,你需要通过shell连接到它,而不是使用一个Jupyter notebook。为此,请运行以下命令来查找容器名称:


这个命令将显示所有正在运行的容器。找到运行jupyter/pyspark-notebook镜像的容器的CONTAINER ID,并使用它连接到容器内的bash shell:

现在你应该连接到容器内部的一个bash提示符了。你可以确认一切正常,因为你shell的提示符将变为类似于jovyan@4d5ab7a93902的东西,但是使用的是你的容器的唯一ID。
注意: 用你机器上使用的CONTAINER ID来替换4d5ab7a93902。
集群
你可以通过命令行使用与Spark一起安装的spark -submit命令将PySpark代码提交给一个集群。该命令接受一个PySpark或Scala程序,并在集群上执行它。这很可能就是你执行真正的大数据处理工作的方式。
注意: 这些命令的路径取决于Spark安装在何处,并且可能只有在使用引用的Docker容器时才能工作。
要使用正在运行的Docker容器运行Hello World示例(或任何PySpark程序),首先,你得像前边描述的那样访问shell。一旦进入容器的shell环境,你就可以使用nano文本编辑器创建文件。
要在你的当前文件夹中创建文件,只需带上要创建的文件的名称来启动nano:

输入Hello World示例的内容,然后按下Ctrl+X保存文件,并遵循保存提示:
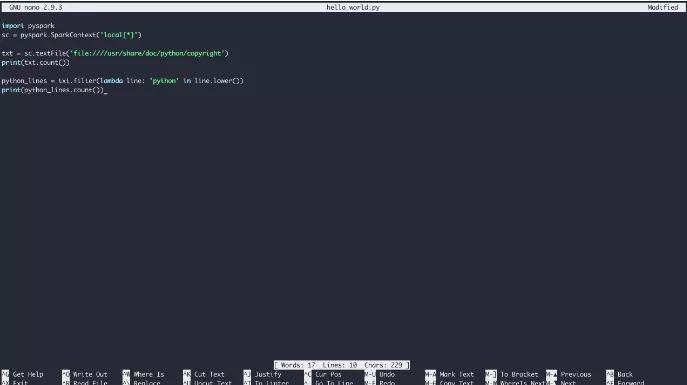
最后,你可以使用pyspark-submit命令通过Spark来运行代码:

默认情况下,该命令会产生大量输出,因此可能很难看到你的程序的输出。通过更改SparkContext变量上的级别,你可以在你的PySpark程序中控制日志的详细程度。要做到这一点,把这一行代码放在你的脚本顶部附近:

这将忽略spark-submit的一些输出,因此,你将更清楚地看到你的程序的输出。但是,在一个实际场景中,你会希望将任何输出放入一个文件、数据库或其它存储机制中,以便稍后更容易地进行调试。
幸运的是,PySpark程序仍然可以访问所有的Python标准库,所以将你的结果保存到一个文件中并不是问题:
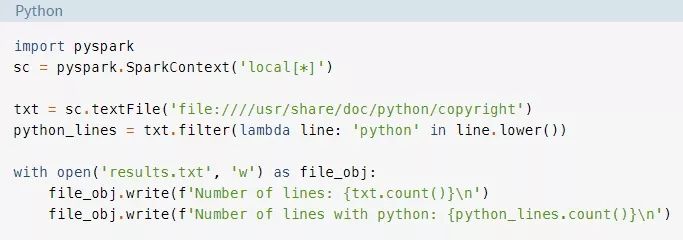
现在你的结果在一个名为results.txt的单独文件中,方便以后参考。
注意: 上面的代码使用了f-strings,它是在Python 3.6中被引入的。
PySpark Shell
运行你的程序的另一种特定于PySpark的方法是使用PySpark本身提供的shell。同样,使用Docker设置,你可以像上面描述的那样连接到容器的CLI。然后,你可以使用以下命令来运行专门的Python shell:
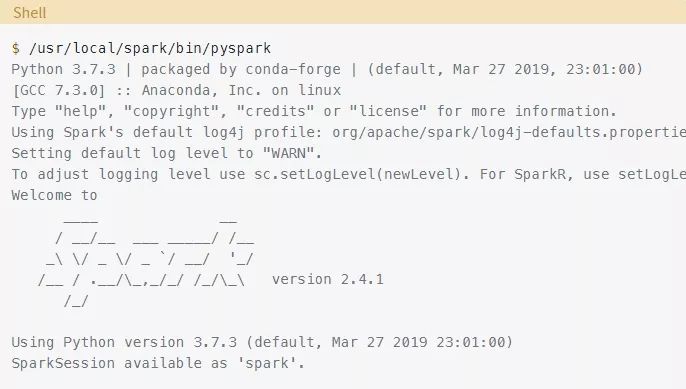
现在你已经处于你的Docker容器中的Pyspark shell环境中了,你可以测试与Jupyter notebook示例类似的代码:

现在你可以使用Pyspark shell了,就像使用普通Python shell一样。
注意: 你不必在Pyspark shell示例中创建一个SparkContext变量。PySpark shell会自动创建一个变量sc,并以单节点模式将你连接到Spark引擎。
当你使用spark-submit或一个Jupyter notebook提交真正的PySpark程序时,你必须创建自己的SparkContext。
你还可以使用标准的Python shell来执行你的程序,只要该Python环境中安装了PySpark。你一直在使用的这个Docker容器没有为标准Python环境启用PySpark。因此,你必须使用前面的方法之一才能在该Docker容器中使用PySpark。
将PySpark和其它工具结合
正如你已经看到的,PySpark附带了额外的库来完成像机器学习和类SQL大型数据集操作这样的事情。不过,你也可以使用其它常见的科学库,如NumPy和Pandas。
你必须在每个集群节点上的相同环境中安装这些库,然后你的程序就可以像往常一样使用它们了。之后,你就可以自由地使用你已经知道的所有熟悉的惯用Pandas技巧了。
记住: Pandas DataFrame需要被迅速计算,因此所有数据都将需要在一台机器上放入内存。
真正的大数据处理的下一步
在学习了PySpark基础知识后不久,你肯定想要开始分析在你使用单机模式时可能无法工作的大量数据。安装和维护一个Spark集群远远超出了本指南的范围,而且很可能它本身就是一项全职工作。
因此,可能是时候去拜访你办公室的IT部门或研究一个托管的Spark集群解决方案。一个潜在的托管解决方案是Databricks。
Databricks允许你使用Microsoft Azure或AWS托管数据,并提供14天的免费试用。
在你拥有了一个工作的Spark集群之后,你会想要将所有数据放入该集群进行分析。Spark有很多导入数据的方法:
Amazon S3
Apache Hive数据仓库
任何带有JDBC或ODBC接口的数据库
你甚至可以直接从一个网络文件系统中读取数据,这就是前面示例的工作方式。
访问你的所有数据的方法并不缺乏,不管你使用的是像Databricks这样的一个托管解决方案,还是你自己的机器集群。
结论
PySpark是大数据处理的一个很好的切入点。
在本教程中,如果你熟悉一些函数式编程概念,如map()、filter()和基本Python,那么你就不必花费大量的时间来预先学习。实际上,你可以在你的PySpark程序中直接使用你已经知道的所有Python知识,包括熟悉的工具,如NumPy和Pandas。
你现在可以:
理解适用于大数据的内置Python概念
编写基本的PySpark程序
使用你的本地机器在小数据集上运行PySpark程序
探索更多可用的大数据解决方案,如一个Spark集群或另一个自定义的托管的解决方案
英文原文:https://realpython.com/pyspark-intro/
译者:浣熊君( ・᷄৺・᷅ )