深度思考:RealVSR-业界首个移动端真实场景视频超分数据集(ICCV2021 )

极市导读
关于学术界的视频超分方案如何应用到真实场景这一问题,本文提出采用多个相机采用成堆LR- HR视频序列构建了一个Real-world Video Super-Resolution(RealVSR),实验结果表明RealVSR数据集上训练的VSR模型在真实场景数据具有更好的视觉质量。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

Abstract
视频超分旨在对低分辨率视频提升分辨率的同时对细节进行增强(可能还会附带噪声抑制、压缩伪影移除亦或取出运动模糊)。现有的视频超分方案大多在合成数据上进行训练,这种简单的退化机制在面对真实场景的复杂退化时就会出现严重的性能下降。因此,如何将学术界的视频超分方案应用到真实场景,或者缩小两者之间的性能差异就更为值得进行探索与研究 。
为缓解上述问题,本文采用多个相机(iPhone 11 Pro Max)采用成对LR-HR视频序列构建了一个Real-world Video Super-Resolution(RealVSR) 。由于LR-HR视频对是通过两个相机采集得到,两者之间不可避免会存在某种程度的不对齐、亮度/色彩差异。为更鲁棒的进行VSR模型训练、重建更多细节,我们将LR-HR视频转换为YCbCr颜色空间,将亮度通道分解为拉普拉斯金字塔,针对不同的成分实施不同的损失函数 。
实验结果表明:相比合成数据训练的模型,在RealVSR数据集上训练的VSR模型在真实场景数据具有更好的视觉质量,边缘更锐利 。此外,这些模型表现出了非常好了跨相机泛化性能。下图给出了合成数据训练模型与RealVSR训练模型的效果对比,很明显:在RealVSR上训练的视频超分模型在真实数据上重建细节更为清晰。

The Real-world VSR Dataset
我们的目的在于构建一个包含成对LR-HR序列的真实视频超分数据集,它可以作为一个有意义的基准对真实视频超分算法进行训练与评估。该数据通过iPhone 11 Pro Max手机的双摄与DoubleTake软件的采集功能构建,采集流程可参见下图。
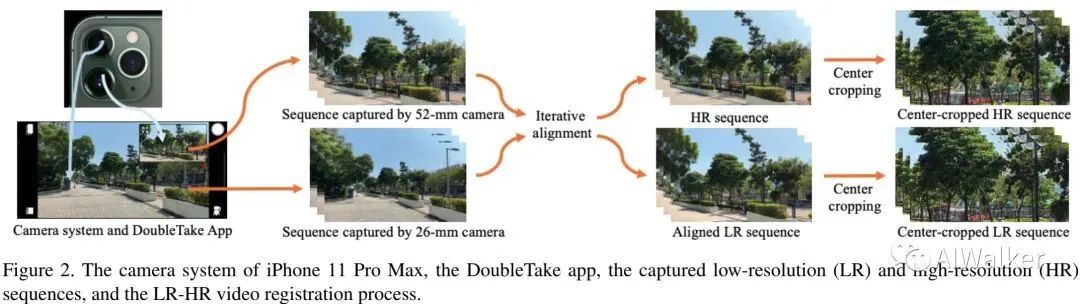
正如上图所示,DoubleTake软件使得我们可以通过两个不同焦距的相机采集不同尺度的高清视频序列。iPhone11 Pro Max具有三个后置镜头:13mm焦距的超广角镜头、26mm焦距的广角镜头以及52mm的长焦镜头,这三个镜头均可以采集12M的图像。更大焦距的镜头可以采集更精细的细节,尺度因子正比于焦距。考虑到超广角镜头的严重畸变与裁剪后画质损失,我们采用26mm与52mm焦距的镜头进行数据集构建:52mm镜头采集的数据作为HR序列,而26mm镜头采集的数据用于生成LR序列,这就构成了X2视频超分数据集。
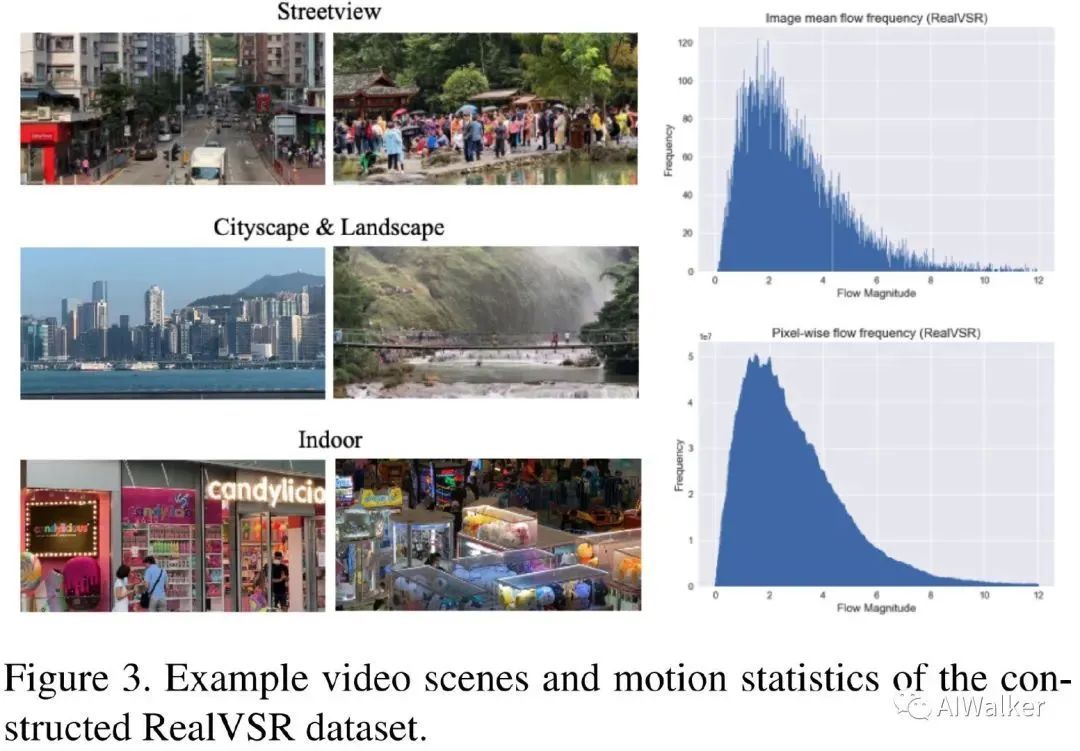
基于iPhone 11 Pro Max与DoubleTake软件,我们采集了超700对序列,每对序列包含两个近乎同步的帧率为30fps、分辨率为1080p的视频。为确保数据的多样性,所采集的数据集覆盖了不同场景,包含室内与室外、白天与夜景、静态场景与包含运动物体的场景等等。最后,经过精心筛选后保留了500对视频序列。下图给出了一些示例与数据集的一些统计信息。
最后,每个成对序列中的LR与HR帧需要进行对齐以便于VSR模型训练。我们采用了RealSR中的方法对LR-HR视频逐帧对齐。考虑到相邻帧之间可能存在某些匹配偏差,我们对文中的对齐算法进行了扩展:采用五个近邻帧作为输入计算中间帧的匹配矩阵。需要注意的是:经过对齐后,LR与HR序列具有相同尺寸。为进步标准化,我们将所有序列拆分为长度50帧的序列。也就是说:RealVSR数据包含500对LR-HR序列,每对序列包含50帧,每帧分辨率为 。
VSR Model Learning
Motivation and Overall Learning Framework
延续TAN、EDVR等工作,我们同样将VSR表示为多帧超分:给定 帧连续LR视频帧 , 我们旨在对中间帧进行预测 。
一般来讲,视频获取过程中会存在多种退化,比如模糊、噪声、ISP中的非线性映射以及视频编码导致的压缩伪影等。相比合成数据,RealVSR天然的考虑了上述真实场景那种的复杂退化。然而,这种复杂退化也为有效训练VSR模型带来了极大挑战。比如,LR-HR视频是由两个相机在不同角度、传感器以及ISP等条件下采集得到,存在不同的畸变。尽管对齐算法可以缓解上述问题,但仍存在微小的不对齐以及亮度/颜色差异,可参见下图。

我们的目标是对LR帧的细节(边缘、纹理等)进行复原,而非全局亮度与色彩。因此,我们提出一组基于分解的损失对VSR模型进行优化。整个学习框架见下图。
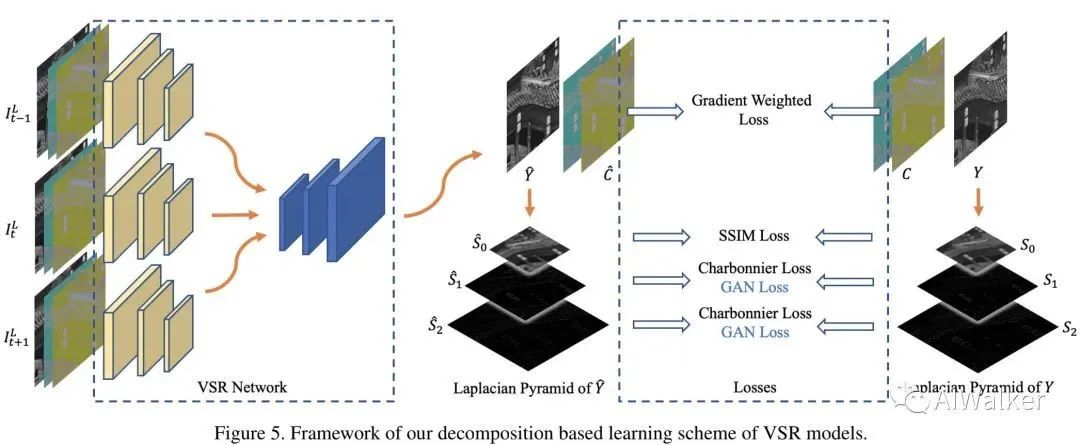
我们将HR视频转换到YCbCr颜色空间以分离亮度与颜色并对不同成分施加不同的损失。
-
对于Y通道,我们设计了一个拉普拉斯金字塔损失以辅助网络更好的重建细节而弱化亮度差异; -
在Cb与Cr颜色通道,我们采用了梯度加权内容损失以聚焦色彩边缘。
为进一步增强重建HR视频质量,我们提出一种基于多尺度边缘的GAN损失引导纹理生成。
Decomposition based Losses
Laplacian pyramid based loss on luminance channel Y通道包含大部分纹理信息,它对于图像细节重建非常重要。VSR研究中常见损失为 , Charbonnier损失,而它们对于全局亮度差异非常敏感,可能不会聚焦于学习结构与细节。
为解决该问题,我们将Y通道分解为拉普拉斯金字塔:低频部分捕获全局亮度与图像的整体结构;高频部分包含图像的多尺度细节。通过对低频与高频成分施加不同的损失,我们可以取得更好的细节重建,同时允许一定程度的全局亮度差异。
假设预测HR亮度与真实HR亮度通道分别为 , 我们将其分解为三层拉普莱斯金字塔 。其中, 表示低频, 其他两个表示高频。全局亮度差异主要体现在低频 成分,我们对其采用SSIM损失以促进结构信息重建:
由于高频成分独立于全局亮度差异,对此我们采用Charbonnier损失以促进细节的精确重建:
注: 。
Gradient weighted loss on chrominance channels 相比亮度通道,色度通道CbCr更为平滑。因此,我们聚焦于色彩边缘的重建。受启发于CDC,我们采用了梯度加权损失:
注: 表示水平与垂直方向的绝对梯度差异,
Multi-scale edge-based GAN loss GAN常用于SISR中提升所预测HR的感知质量,已有方案往往将GAN损失直接作用全彩图像上,而这对于纹理生成可能还不够有效。我们基于PatchGAN与Relativistic Average判别器构建了多尺度边缘GAN损失以促进更细粒度纹理生成。生成的对抗损失定义如下:
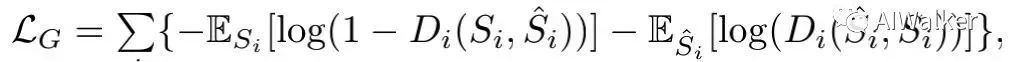
判别器的损失定义如下:
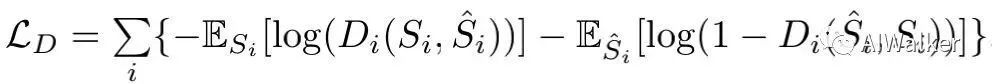
Final Loss 基于上述损失,我们构建了两个版本的损失:
-
版本1: 聚焦于重建精确细节,组合如下:
-
版本2: 旨在进一步提升视觉感知质量,组合如下:
Experiments

上表对比了不同超分方案在不同数据训练并在本文RealVSR测试集的性能,从中可以看到:
-
相比双三次插值,在合成数据集上训练的VSR仅取得了SSIM指标的微小提升,而在PSNR指标甚至还会出现变差。这说明: 合成数据上训练的VSR难以泛化到具有复杂降质退化的真实场景 。 -
相反,在真实数据集上训练的VSR取得了更好的PSNR/SSIM指标,无参考指标NIQE与BRISQUE同样有提升。

上图给出了两组真实场景超分效果的视觉效果对比,可以看到:
-
在合成数据上训练的模型倾向于生成模糊边缘,甚至还存在伪影问题; -
在RealVSR数据上训练的模型可以生成更锐利边缘,具有更少的伪影问题。
该结果进一步说明:真实退化对于训练鲁棒视频超分模型非常重要 。

上图对比了跨相机数据的超分效果,从中可以看到:相比合成数据训练的模型,RealVSR上训练的模型具有更清晰的边缘、更少的伪影,训练的模型具有更丰富的细节与纹理,进一步提升了视觉感知质量。
独家思考
“自建数据集+损失函数 ”好像成为了最近两年low-level领域一个新的挖掘点。最近深耕图像/视频复原的研究员/工程师都意识到:单纯的网络架构调节很难出有影响力的工作,而且实用价值不高。因此,自建数据集就成为了一个不错的挖掘点,这样很容易就能够做到“能他人所不能”。
但是,自建数据集并没有想象的那样容易 !不是说我花几天采集几百组数据就OK的,而是需要去思考设计数据集构建过程中的各个环节,从理论说明到工程构建都需要有一定功底,此外还需要承受“失败”的可能(失败的概率其实挺大的,投入产出不成正比)。
从笔者个人角度来看,这篇文章的数据集构建本质上的创新并不多,但有一点,而且是非常关键的一点:手机端的视频超分数据集 。之前的自建数据集大多是基于单反构建,单反能够通过调节焦距的方式来采集成对的数据,难度相对要小一些;但是,手机视频想同步成比例对齐非常难。这篇论文取了个巧,利用iPhone 11 Pro Max自带的多相机成像系统+Doubletake软件采集同步成比例的数据,再通过对齐技术进一步进行图像对齐。当然,轻微的不对齐肯定还是存在的,但应该在可接受范围了。不得不说:Doubletake软件的多相机成像功能真的很赞 !12大洋体验了一把,值!接下来可以去采集数据咯。
两个传感器采集的视频不可避免会存在亮度、色彩的不一致,这个很容易理解:焦距、感光以及ISP算法等方面的差异肯定会造成一些成像差异。这样的数据拿来直接训练效果会很奇怪(别问我怎么知道),那么如何缓解该问题呢?这个时候就该损失函数闪亮登场了!
论文给出了一个很不错的想法:亮度空间增强细节(英雄所见略同,大大的自夸,机智如我!)。在Y通道上去做确实可以缓解色彩不一致问题,但变换到RGB颜色空间后部分场景仍会有色差。这篇文章又向前走了一步:对CbCr色度通道进一步优化。其实,笔者最称道的还是:Y通道的损失函数=低频成分的SSIM损失+高频成分的Charbonnier组合 。
最后“吐槽”一点:现在自建数据集的文章都是拿合成数据训练的模型与自建数据训练的模型在自建数据上进行测试,这个真的公平吗(虽然目的是为了Real-world)???当训练数据分布与测试数据分布存在较大差异时,模型性能肯定会有明显的下降。所以....
其实如何既在合成数据(某种程度上不也是真实场景数据吗?)上效果好,又在真实场景上效果好才有价值。此外,移动端视频画质增强(尤其1080p、4k输入)何时才能真正达到商用值得期待?期待学术界的同行们能带来更多的探索与引领。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



