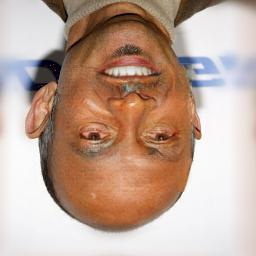
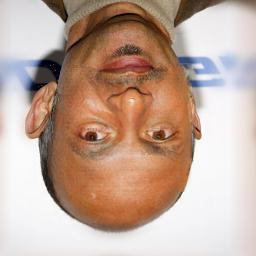
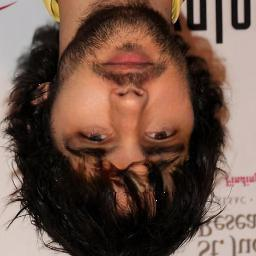
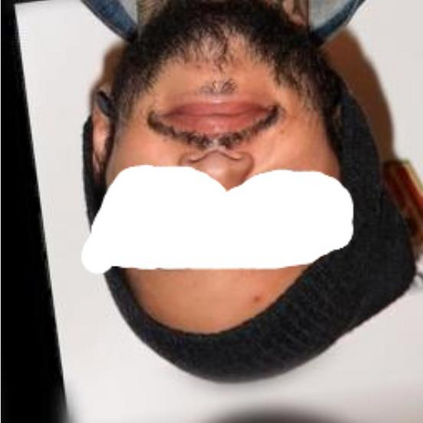
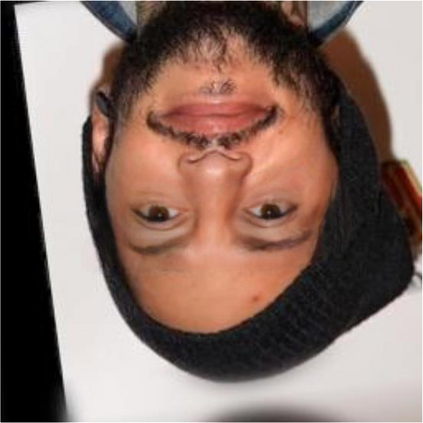
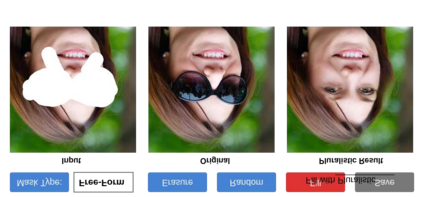
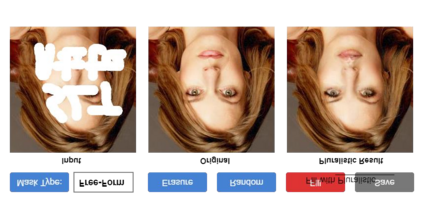
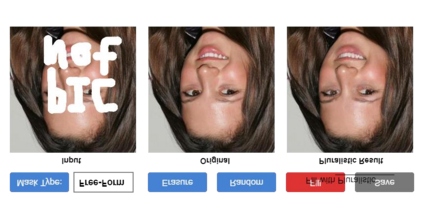
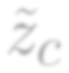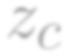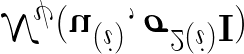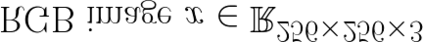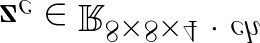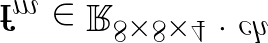Most image completion methods produce only one result for each masked input, although there may be many reasonable possibilities. In this paper, we present an approach for pluralistic image completion - the task of generating multiple and diverse plausible solutions for image completion. A major challenge faced by learning-based approaches is that usually only one ground truth training instance per label. As such, sampling from conditional VAEs still leads to minimal diversity. To overcome this, we propose a novel and probabilistically principled framework with two parallel paths. One is a reconstructive path that extends the VAE through a latent space that covers all partial images with different mask sizes, and imposes priors that adapt to the number of pixels. The other is a generative path for which the conditional prior is coupled to distributions obtained in the reconstructive path. Both are supported by GANs. We also introduce a new short+long term attention layer that exploits distant relations among decoder and encoder features, improving appearance consistency. When tested on datasets with buildings (Paris), faces (CelebAHQ), and natural images (ImageNet), our method not only generated higher-quality completion results, but also with multiple and diverse plausible outputs.
翻译:多数图像完成方法只为每个掩蔽输入产生一个结果, 虽然可能有很多合理的可能性。 在本文中, 我们展示了多元图像完成方法, 即为图像完成提供多种且多样的可信解决方案。 基于学习的方法所面临的一个重大挑战是每个标签通常只有一个地面真相培训实例。 因此, 从有条件的 VAE 取样仍然导致最小多样性。 为了克服这一点, 我们提出了一个具有两个平行路径的新颖且概率原则框架。 一个是重建路径, 通过覆盖所有部分图像且面罩大小不同的潜在空间扩展 VAE, 并强制设置适应像素数目的前缀。 另一个是基因化路径, 之前的附加条件与重建路径的分布相连接。 两者都得到 GANs 的支持。 我们还引入了一个新的短长的注意层, 利用解析器和编码特性之间的遥远关系, 提高外观一致性。 在与建筑物( 巴黎 ) 、 面部( CelebAHQ ) 和自然图像( ImageNet) 测试时, 我们的方法不仅产生高质量产出, 而且是多种和高质量产出。