【学界】密西根大学利用图像生成过程进行「数据增强」,以提高现实场景中「目标检测」的鲁棒性

原文:arXiv
作者:Alexandra Carlson、Katherine A. Skinner、Matthew Johnson-Roberson、Ram Vasudevan
来源:雷克世界
导语:长期以来,深度学习使一系列计算机视觉任务的性能得到提升,而在本文中,密西根大学安娜堡分校(University of Michigan, Ann Arbor)的科学家们提出利用图像生成过程进行数据增强,对相机效果进行建模以提升在真实数据和合成数据上进行的深度视觉任务的性能表现,接下来,本文将介绍辐射是如何转换为8位像素值从而助力基于物理的数据增强的。
最近,我们的研究主要集中于生成合成图像和增强真实图像,以增加用于学习城市场景中视觉任务的训练数据的大小和可变性。这包括增加遮挡的发生或改变环境和天气的影响。然而,几乎没有人能够解决传感器领域中的变分建模问题。不幸的是,对于在人工注释的数据集上进行训练的视觉任务而言,改变传感器效应会降低其性能和结果的泛化能力。本文提出了一种高效、自动化的基于物理的增强管道,以改变真实的和合成图像上的传感器的效应——特别是色差、模糊、曝光、噪音和偏色等。具体来说,本文阐述了,使用所提出的管道增加训练数据集,能够提高在各种基准工具数据集上目标检测的鲁棒性和可泛化性。

深度学习使一系列计算机视觉任务的性能得到提升。随着一些基准数据集为训练深度神经网络(DNN)提供数以百万的手工标记图像,增加所标记的训练数据集的大小和变化为这些性能的提升带了很多贡献。理想情况下,我们可以编译一个大型的代表所有领域的综合训练集,并被标记以用于所有的视觉任务。不幸的是,收集和标记大量的训练数据是非常昂贵和耗时的。此外,我们不可能收集到一个捕获了现实世界中所存在的所有变化的单一真实数据集。
图1:在KITTI上对基线未增强数据(左)和我们提出的方法(右)进行目标检测的样本示例。蓝色方框表示正确的检测结果,红色方框表示基线法遗漏的、但通过我们所提出的基于传感器的图像增强方法能够检测到的结果。
最近的研究表明,在使用合成数据训练DNN以及对真实数据进行测试方面已经取得了成功。渲染引擎可以用来生成大量的合成数据,而这些数据看起来非常逼真。像素级标签可以自动生成,大大降低了为不同任务创建基本事实标签所需的成本和工作量。增强真实数据是增加数据集大小的另一种方式,无需额外的手工标签。合成渲染和增强管道都寻求在一个图像集中提高场景特征的可变性。特别是,最近的研究着重点在于建模环境的影响,比如场景照明、当日时间、场景背景、天气和遮挡,以增加训练集中这些因素的表征,从而在测试期间增加针对这些案例的鲁棒性。另一种方法是增加有用目标的出现,以在不同场景和空间配置中训练这些目标的过程中提供更多的样本。
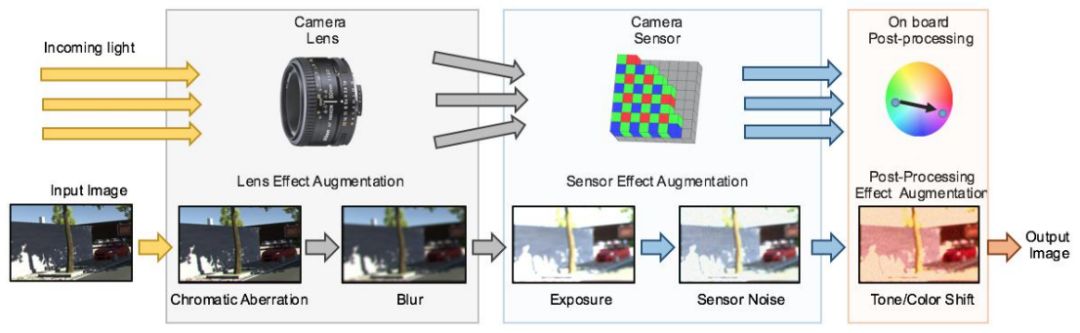
图2:在我们的研究中所使用的图像形成和处理流程图。一个给定的图像会经历增强,这些增强就近似于相机在图像中所产生的相同像素级效果。
然而,尽管空间布局和环境因素各不相同,但在实现结果的鲁棒性和泛化能力方面仍然存在一定的挑战。为了进一步了解合成数据集与真实数据集之间的差别,甚至不同真实数据集之间的区别,我们需要思考DNN在学习视觉任务中的失效模式。目前,已被证实的一点是,导致各基准数据集性能和泛化能力下降的一个因素是传感器偏差。相机模型与环境中的照明之间的相互作用对图像中的像素级伪影(pixel-level artifacts)、失真和动态范围会产生很大影响。根据图1左侧的显示内容可知,包括模糊和过度曝光在内的传感器效应,降低了城市驾驶场景中目标检测网络的性能。尽管如此,在改善由自然环境中已学习视觉任务传感器导致的失效模式方面,仍然是一片空白。

图3:用于CITYSCAPES(左)和VKITTI(右)的单一传感器效应增强和我们的完整图像增强管道增强样本。
在本文中,我们研究了不同传感器模型的DNN性能对城市场景中自主驾驶计算机视觉任务的影响。我们提出,通过一种新的图像增强管道来对由传感器效应引起的信息缺失进行建模。我们的增强管道基于图像生成和处理过程中所产生的效应,这些效应会在学习框架过程中触发失效模式——色差、模糊、曝光、噪声和色偏校正。我们的目标是,通过在包含一组具有代表性实际传感器效应的数据上进行训练,从而在我们的学习框架中实现针对这些效应的鲁棒性。我们增强了真实数据和合成数据,以表明我们提出的方法提高了车辆数据集中目标检测的性能(图1)。软件和数据集将在完成盲审后公布。

图4:错车的定性分析,KITTI样本在左侧,Cityscapes样本在右侧

图5:Virtual KITTI样本在左侧,GTA样本在右侧
我们提出了一种新的基于传感器的图像增强通道,用于增强输入到DNN中的训练数据,以完成城市驾驶场景中的目标检测任务。我们的增强管道模拟了图像生成和后期处理流程中所出现的一系列物理真实的传感器效应。之所以选择这些效应,是因为它们会导致信息丢失或场景失真,从而降低了已学习视觉任务上的网络性能。通过在我们的已增强数据集上进行训练,我们无需进一步标记,即可有效地扩大数据集规模和传感器领域中的变化,进而提高目标检测网络的鲁棒性和泛化能力。我们在一系列基准车辆的数据集上实现了性能的显著提升,其中包括使用真实数据与合成数据进行训练。总而言之,我们的研究结果揭示了,对在合成数据上进行训练,在真实数据上进行测试的特定问题的传感器效应进行建模的重要性。
原文链接:https://arxiv.org/pdf/1803.07721.pdf
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【无监督学习最新研究】简单的「图像旋转」预测,为图像特征学习提供强大监督信号
☞【学界】CVPR 2018 | 哈工大提出STRCF:克服遮挡和大幅形变的实时视觉追踪算法
☞【深度】如何「看图说话」?Facebook提出全新的基于图像实体的「图像字幕」框架
☞【教程】 在Keras上实现GAN:构建消除图片模糊的应用


