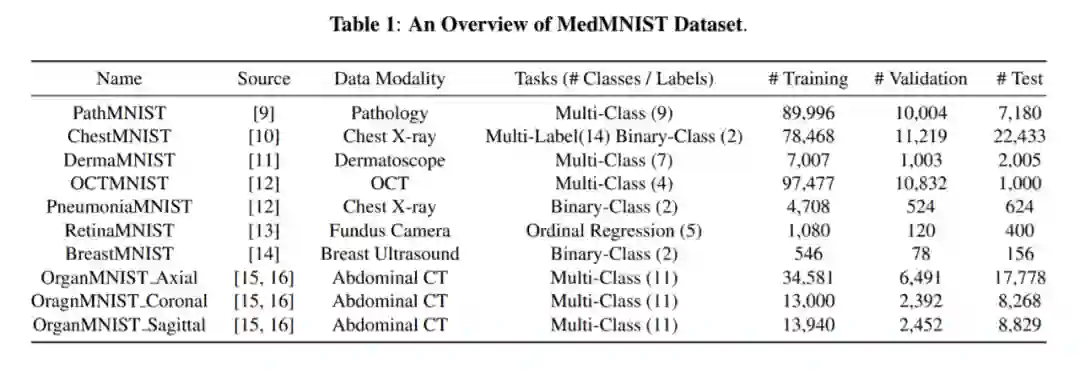
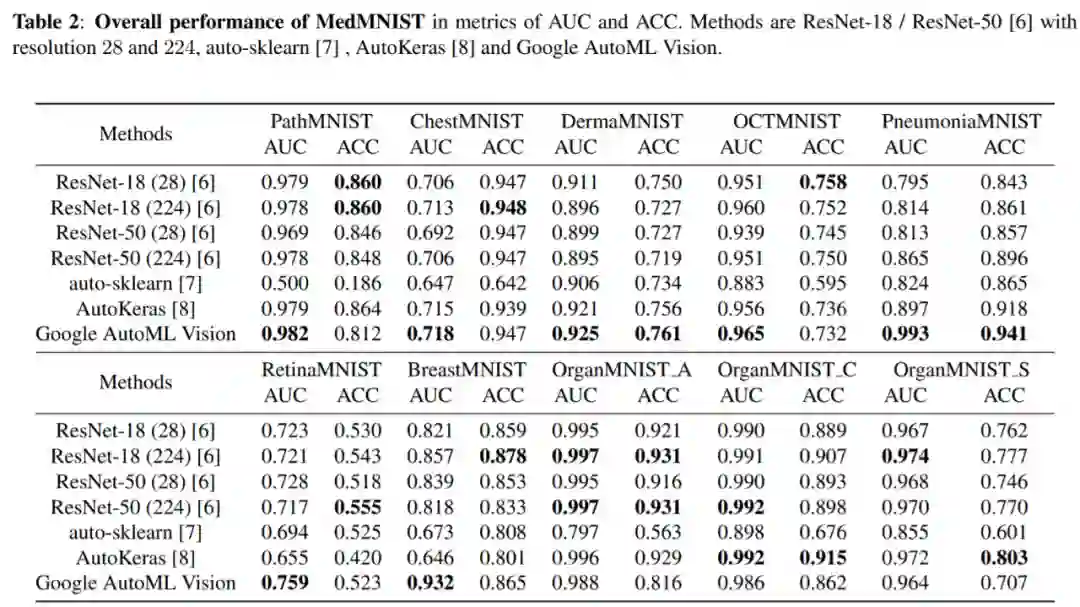
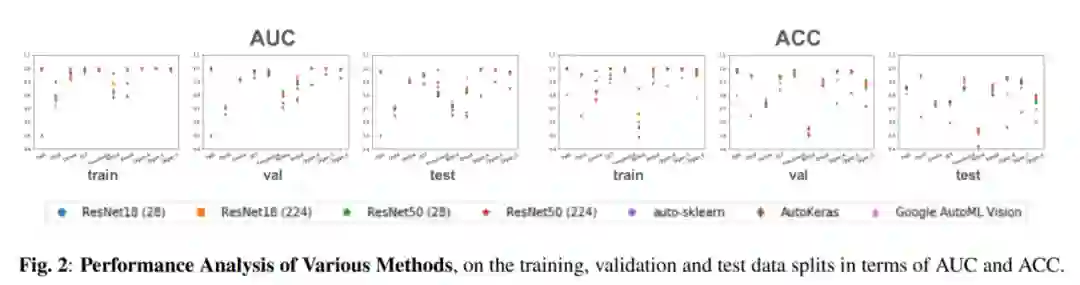
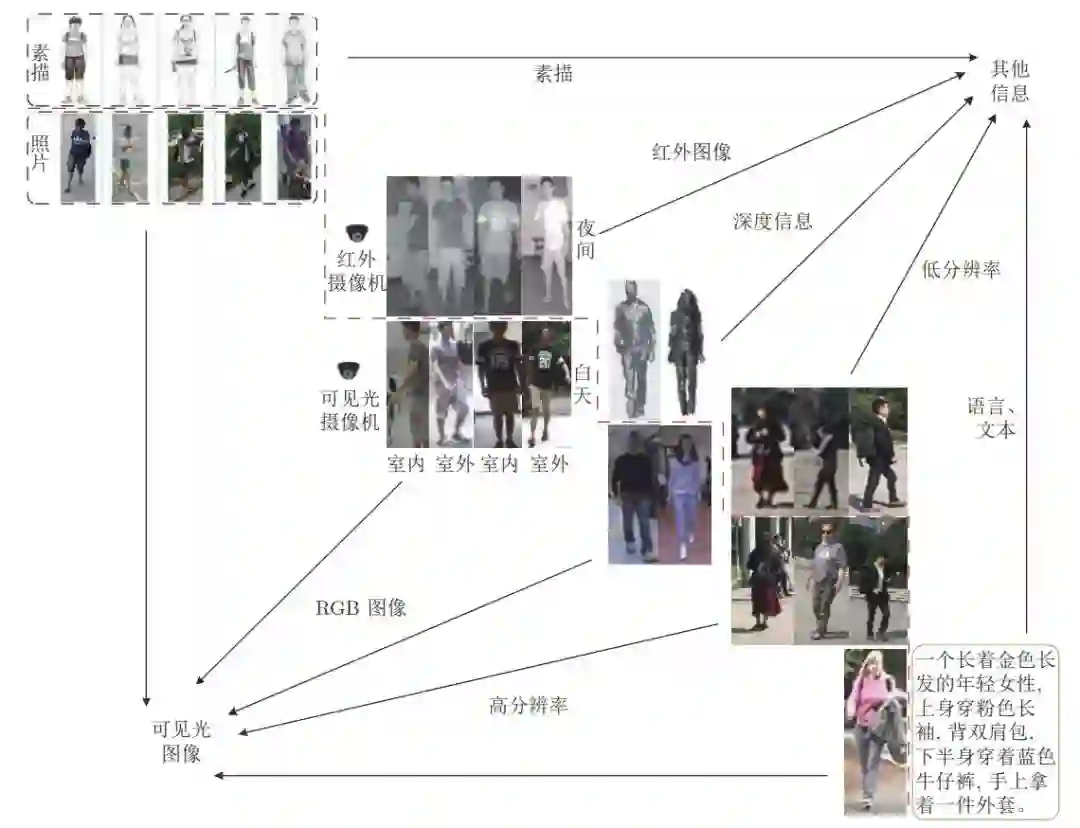
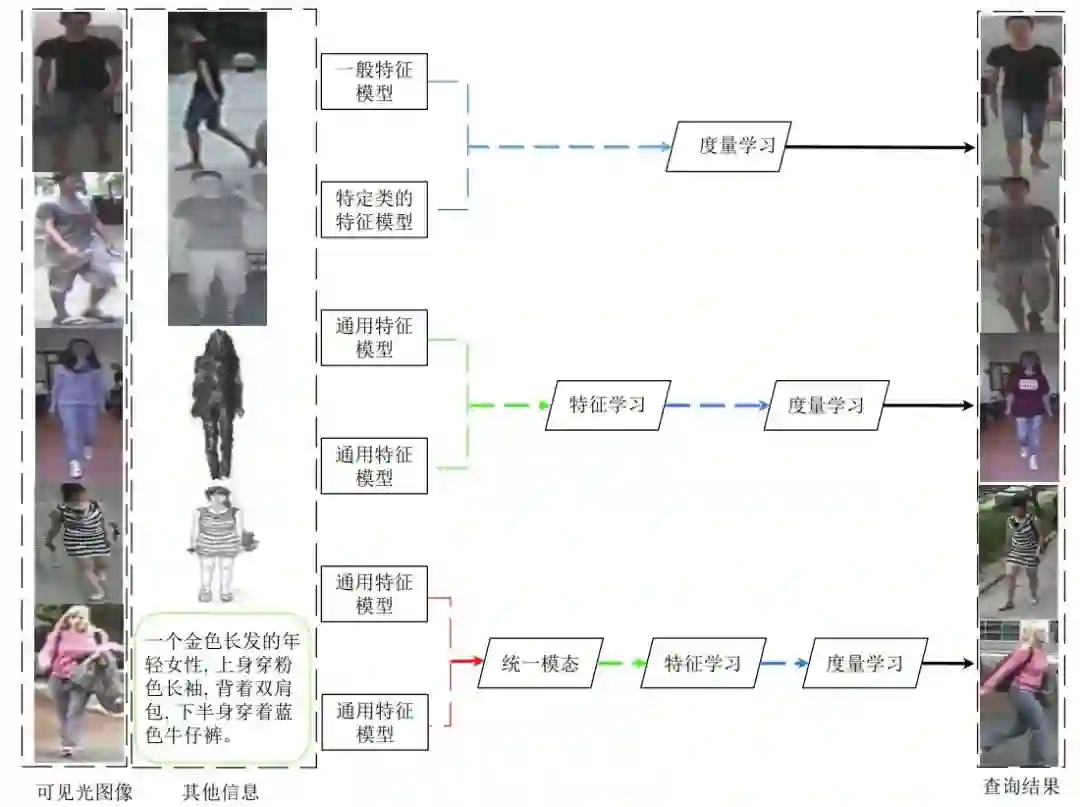
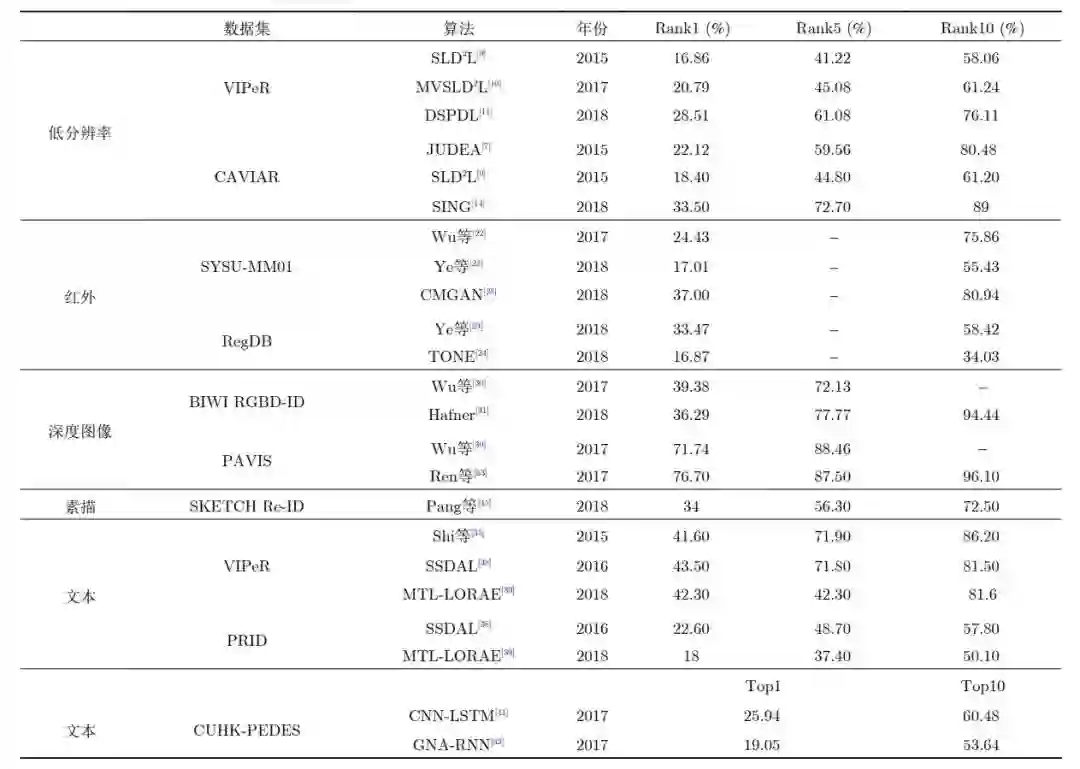
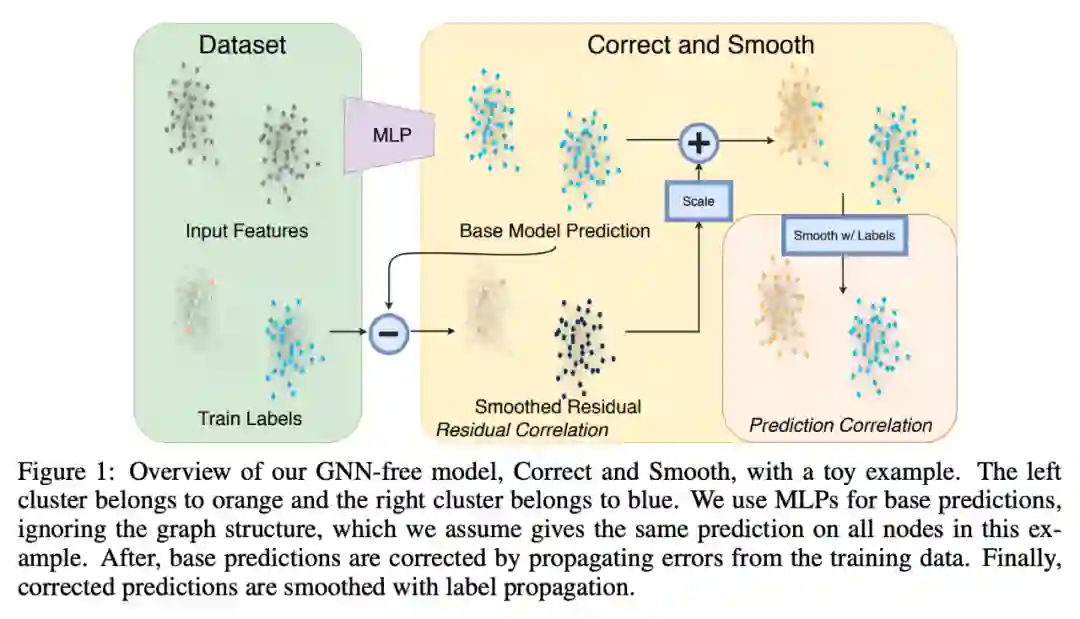
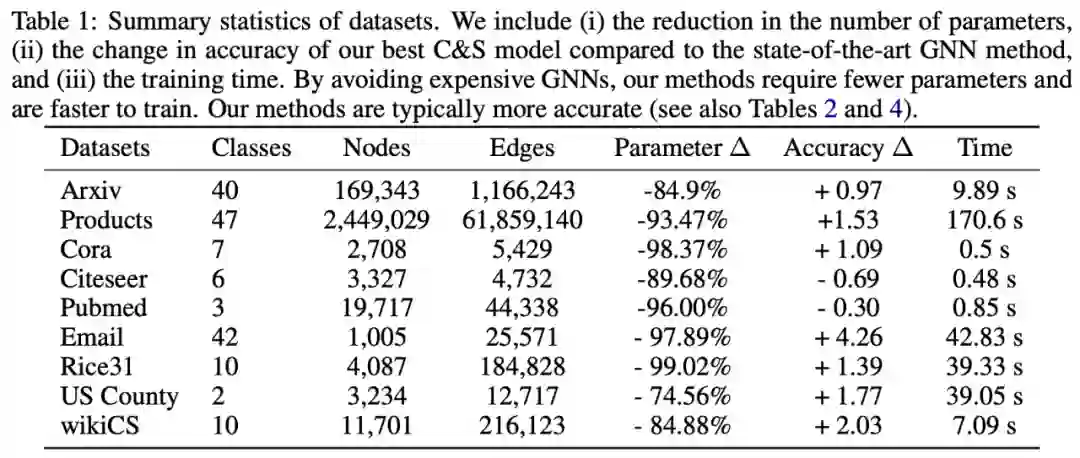
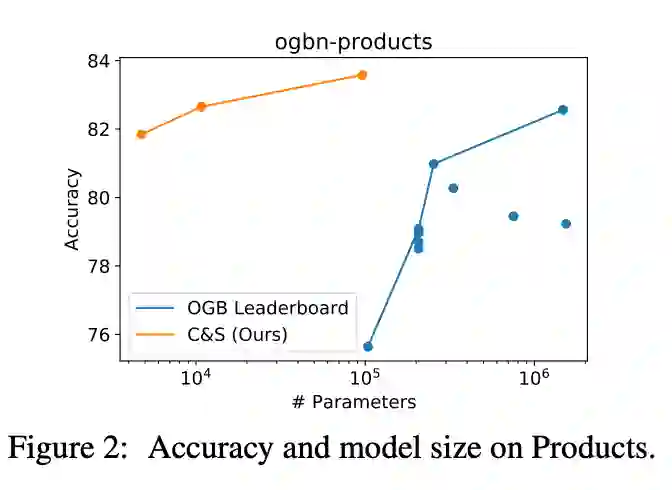
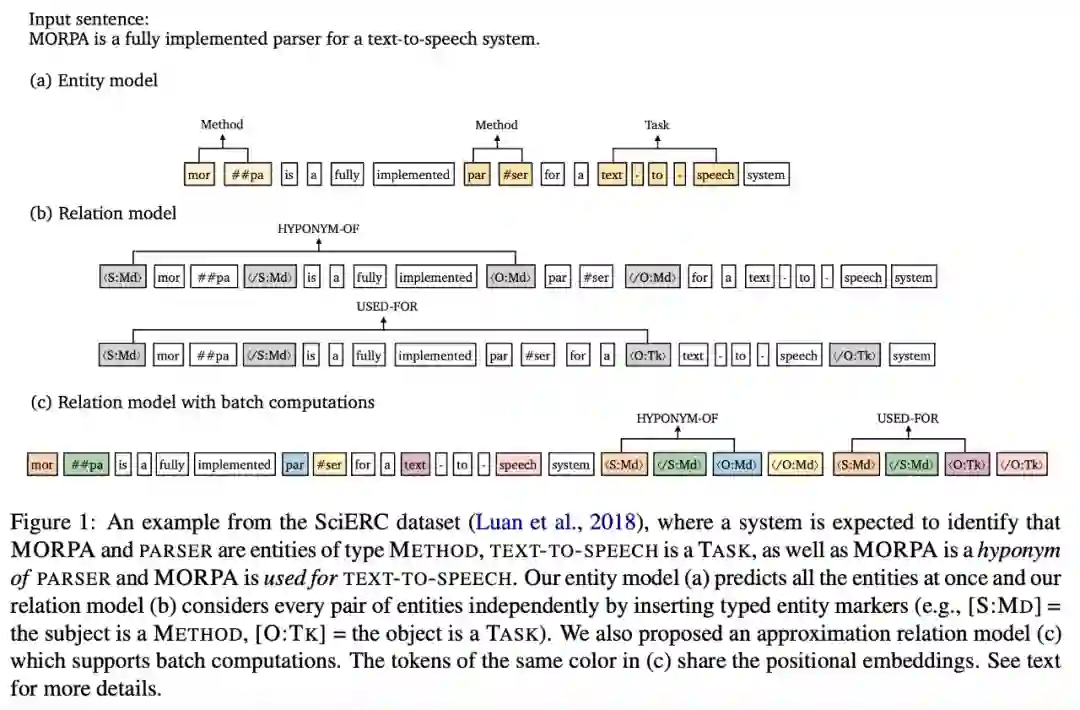
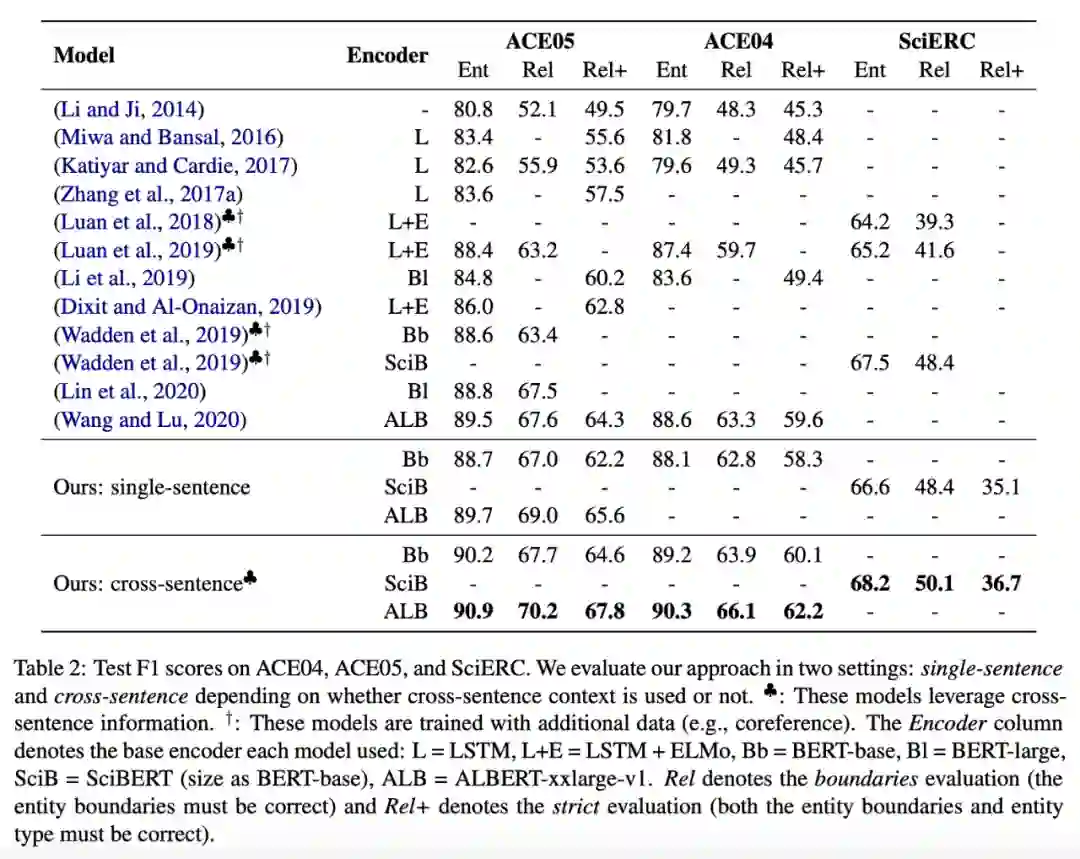
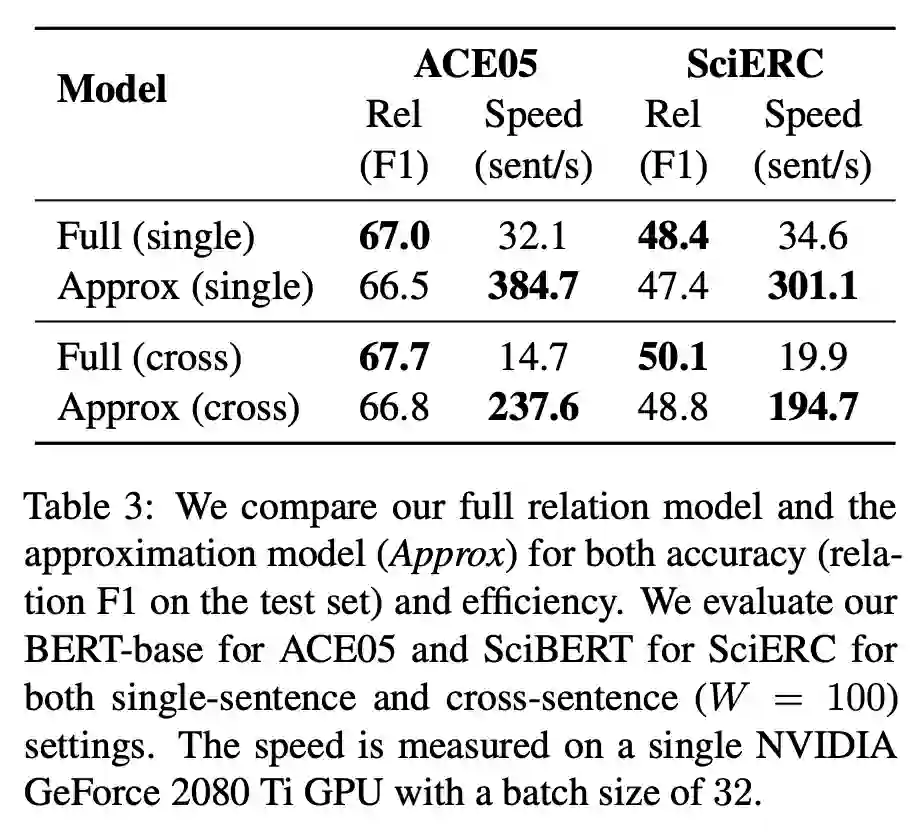
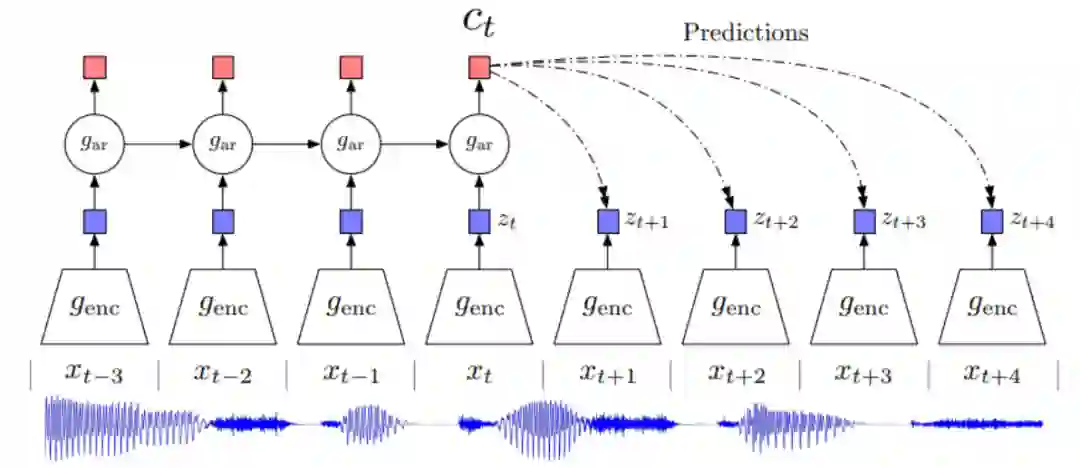
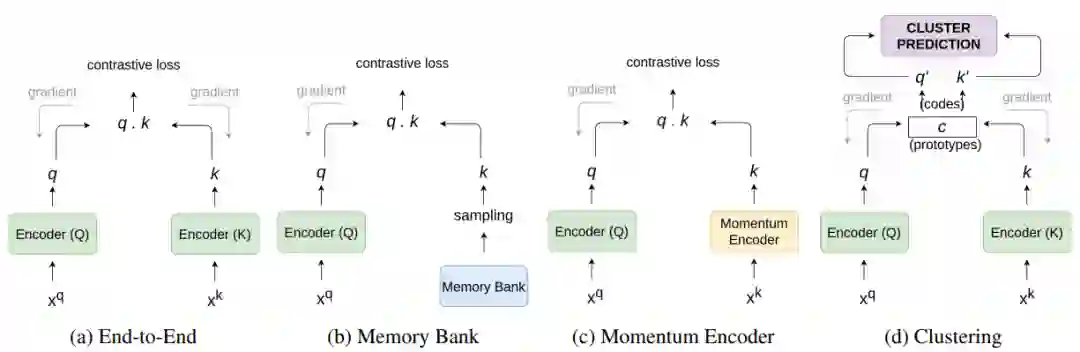
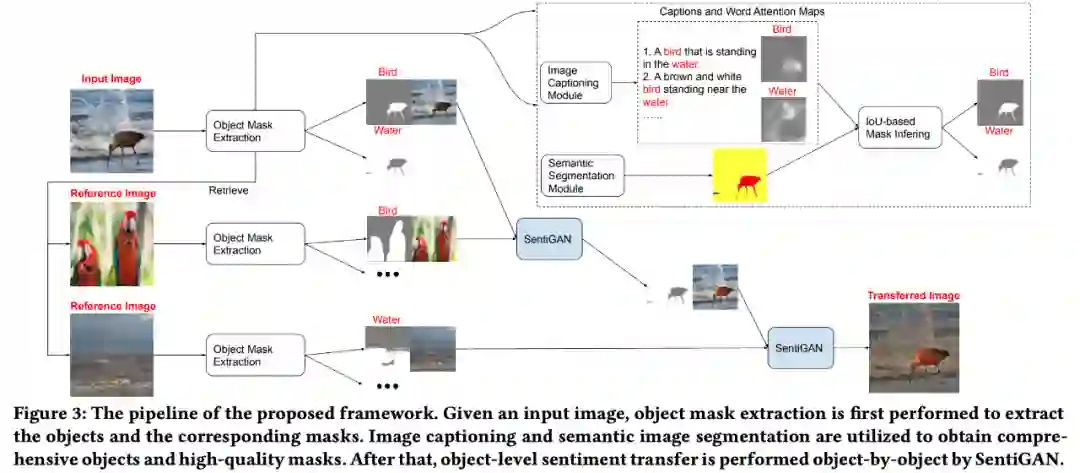
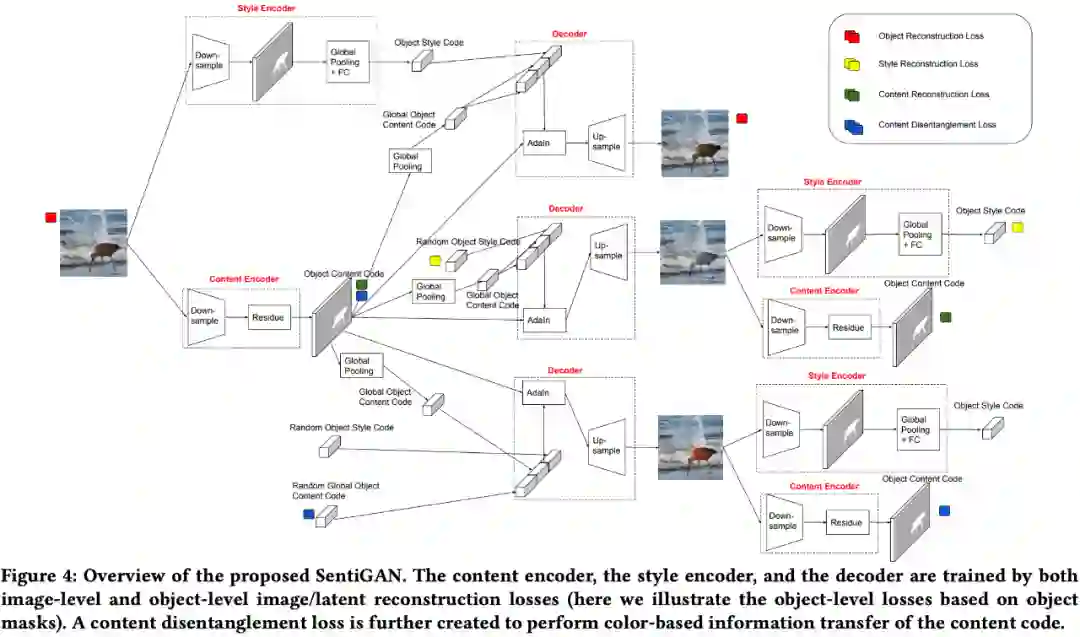
验证物体级情感迁移的效果。 推荐:图像风格迁移?语音情感迁移?不,是图像情感迁移。 ArXiv Weekly Radiostation 机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下: 本周 10 篇 NLP 精选论文是: 1. Semi-supervised Relation Extraction via Incremental Meta Self-Training. (from Philip S. Yu)2. SLM: Learning a Discourse Language Representation with Sentence Unshuffling. (from Christopher D. Manning)3. Phoneme Based Neural Transducer for Large Vocabulary Speech Recognition. (from Hermann Ney)4. Topic-Preserving Synthetic News Generation: An Adversarial Deep Reinforcement Learning Approach. (from Huan Liu)5. SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation. (from Philipp Koehn)6. Cross-Domain Sentiment Classification With Contrastive Learning and Mutual Information Maximization. (from Kurt Keutzer)7. Improving Event Duration Prediction via Time-aware Pre-training. (from Claire Cardie)8. Automatic Detection of Machine Generated Text: A Critical Survey. (from Laks V.S. Lakshmanan)9. Artificial Intelligence (AI) in Action: Addressing the COVID-19 Pandemic with Natural Language Processing (NLP). (from Zhiyong Lu)10. Warped Language Models for Noise Robust Language Understanding. (from Dilek Hakkani Tür) 本周 10 篇 CV 精选论文是: 1. Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples. (from Elliot K. Fishman, Alan L. Yuille)2. Learning unbiased registration and joint segmentation: evaluation on longitudinal diffusion MRI. (from Wiro J. Niessen, Meike W. Vernooij)3. Learning a Generative Motion Model from Image Sequences based on a Latent Motion Matrix. (from Hervé Delingette, Nicholas Ayache)4. Out-of-Distribution Detection for Automotive Perception. (from Roland Siegwart)5. Can the state of relevant neurons in a deep neural networks serve as indicators for detecting adversarial attacks?. (from Tinne Tuytelaars)6. End-to-end Animal Image Matting. (from Stephen J. Maybank, Dacheng Tao)7. Muti-view Mouse Social Behaviour Recognition with Deep Graphical Model. (from Dacheng Tao, Xuelong Li)8. Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers. (from Russell H. Taylor)9. VEGA: Towards an End-to-End Configurable AutoML Pipeline. (from Tong Zhang)10. A spatial hue similarity measure for assessment of colourisation. (from Paul F. Whelan) 本周 10 篇 ML 精选论文是: 1. Comprehensible Counterfactual Interpretation on Kolmogorov-Smirnov Test. (from Jian Pei)2. Handling Missing Data with Graph Representation Learning. (from Jure Leskovec)3. AgEBO-Tabular: Joint Neural Architecture and Hyperparameter Search with Autotuned Data-Parallel Training for Tabular Data. (from Isabelle Guyon)4. Human versus Machine Attention in Deep Reinforcement Learning Tasks. (from Mary Hayhoe, Dana Ballard, Peter Stone)5. Data Augmentation via Structured Adversarial Perturbations. (from Samy Bengio)6. Autoencoding Features for Aviation Machine Learning Problems. (from Keith Campbell)7. Towards a Unified Quadrature Framework for Large-Scale Kernel Machines. (from Johan A.K. Suykens)8. Augmenting Organizational Decision-Making with Deep Learning Algorithms: Principles, Promises, and Challenges. (from Georg von Krogh)9. ControlVAE: Tuning, Analytical Properties, and Performance Analysis. (from Tarek Abdelzaher)10. Bayesian Variational Optimization for Combinatorial Spaces. (from Alán Aspuru-Guzik)