论文浅尝 - AAAI2020 | 通过句子级语义匹配和答案位置推断改善问题生成
论文笔记整理:王春培,天津大学硕士。

链接:https://arxiv.org/pdf/1912.00879.pdf
动机
本文主要聚焦问答系统(Q&A)的反问题---问题生成(Question Generation,Q&G)。问题生成的目的是在给定上下文和相应答案的情况下生成语义相关的问题,问题生成任务可分为两类:一类是基于规则的方法,即在不深入理解上下文语义的情况下手动设计词汇规则或模板,将上下文转换成问题。另一类是基于神经网络的、直接从语句片段中生成问题词汇的方法,包括序列-序列模型(seq-to-seq)、编码器解码器(encoder-decoder)等。本文讨论的是后一种基于神经网络的问题生成方法。
目前,基于神经网络的问题生成模型主要面临以下两个问题:(1)错误的关键词和疑问词:模型可能会使用错误的关键词和疑问词来提问;(2)糟糕的复制机制:模型复制与答案语义无关的上下文单词。本文旨在解决以上两个问题。
亮点
本文的亮点主要包括:
(1)以多任务学习的方式学习句子级语义
(2)引入答案位置感知。
概念及模型
本文提出,现有的基于神经网络的问题生成模型之所以出现上述两个问题是因为:
(1)解码器在生成过程中可能只关注局部词语义而忽略全局问题语义;
(2)复制机制没有很好地利用答案位置感知特征,导致从输入中复制与答案无关的上下文单词。为了解决这两个问题,作者提出以多任务学习的方式学习句子级语义,以及引入答案位置感知。
模型体系结构
下图为具有句子级语义匹配、答案位置推断和门控融合的神经问题生成模型图:
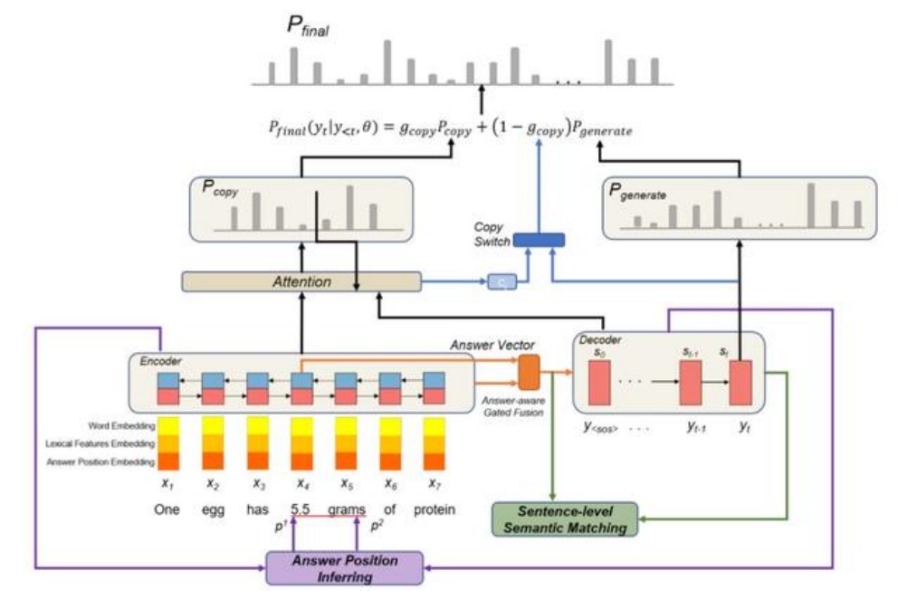
给定包含答案 A 的语句 X=[x1,x2,...,xm],基于连续扩展的语句,生成与 X 和 A 语义匹配的问题 Y。与文献 [1] 的方法一致,利用扩展的语义和词汇特征、部分语音标签、答案位置特征等作为 seq-to-seq 模型嵌入层的输入,利用双向 LSTM 作为编码器,通过链接前向隐藏状态和后向隐藏状态生成句子表示 H=[h1,h2,...,hm]:
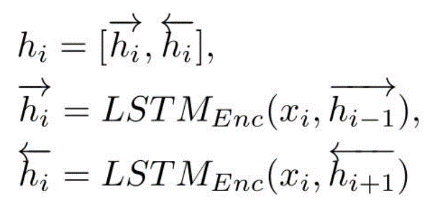
答案感知门控融合:使用两个由 Sigmoid 函数计算的信息流门来控制句子向量和答案向量的信息流,将答案起始位置的隐藏状态作为答案向量 h_a,使用双向 LSTM 编码整个答案语义。
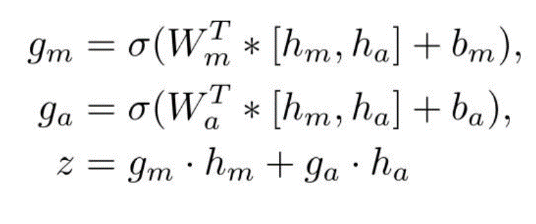
解码器(Decoder):以编码器的隐藏状态 H=[h1,h2,…,hm] 作为上下文和改进的答案感知句子向量 z 作为初始隐藏状态 s1,一层单向 LSTM 用先前解码的单词作为输入wt更新其当前隐藏状态st。
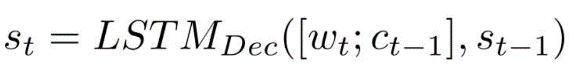
利用注意力机制将当前解码器状态 s_t 赋给编码器上下文 H=[h1,h2,…,hm]。使用归一化处理后的注意向量α_t 的加权求和结果计算上下文向量 c_t。基于词典 V,计算问题单词 y_t:

其中,f 由两层前馈网络实现。
注意力机制:使用注意力机制生成大小为 V 的单词,或从输入语句 X 中复制单词。在生成问题词 y_t 时,考虑到当前解码器的隐藏状态 s_t 和上下文向量 c_t,计算一个复制开关来确定生成的词是从字典生成的还是从源语句复制的。
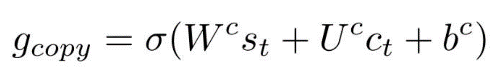
生成模式概率和复制模式概率相结合,得到最终的单词分布:
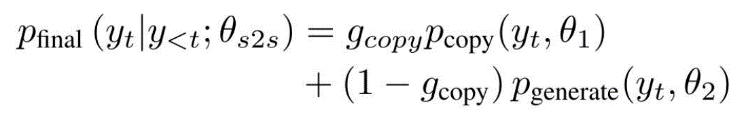
使用负对数似然来计算序列-序列的损失:
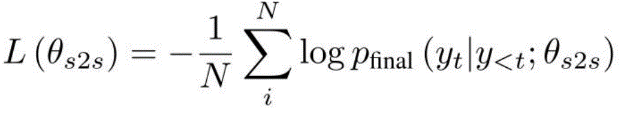
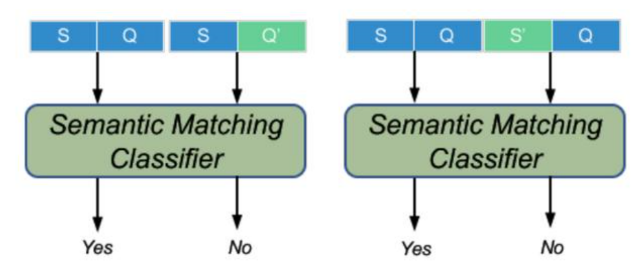
句子级语义匹配:通过门控融合得到了改进的答案感知句子向量 z。对于解码器(单向 LSTM),采用最后一个隐藏状态 s_n 作为问题向量。训练两个分类器,分别将非语义匹配对 [z,S』_n](S,Q』)和 [z』,S_n](S,Q)与语义匹配对 [z,S_n](S,Q)区分开来,其中 z』和 s』是同一段落中随机抽取的不匹配句子和问题的向量。
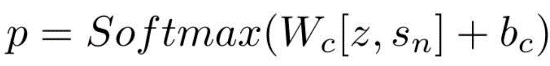
将两个分类器的二元交叉熵之和作为句子级语义匹配损失:
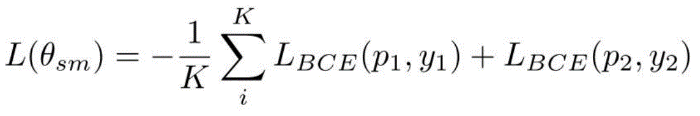
具体流程如下所示:
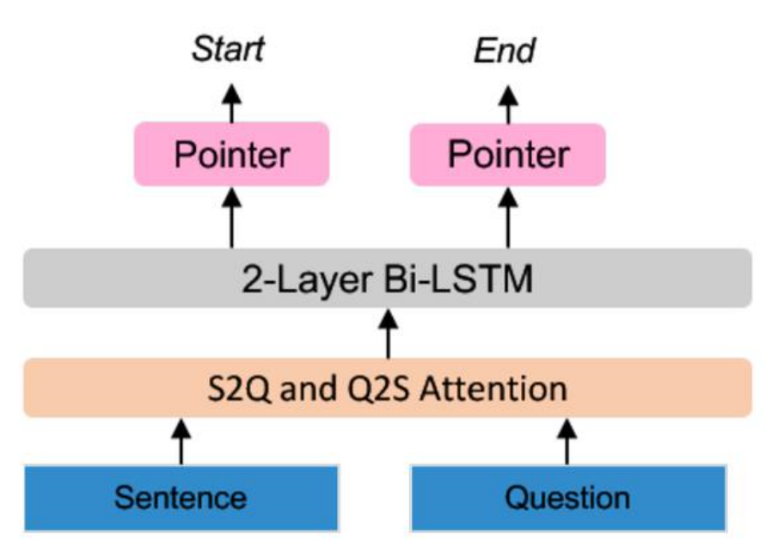
答案位置推断:引入双向注意力流网络推断答案位置,如下图:
采用句子对问题注意和问题对句子注意来强调每个句子词和每个问题词之间的相互语义关联,并利用相似的注意机制得到了问题感知的句子表征 H 和句子感知的问题表征 S:
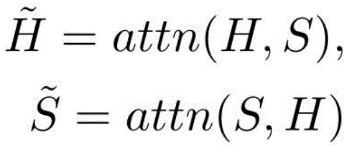
然后,使用两个两层双向 LSTMs 来捕获以问题为条件的句子词之间的相互作用。答案起始索引和结束索引由输出层使用 Softmax 函数预测:
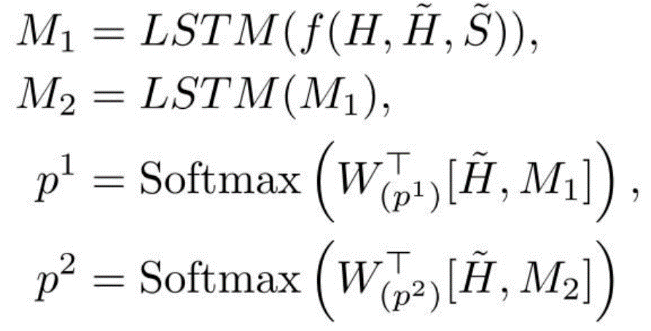
其中,f 函数是一个可训练的多层感知(MLP)网络。使用真值答案起始标记 y1 和结束标记的负对数似然来计算损失:
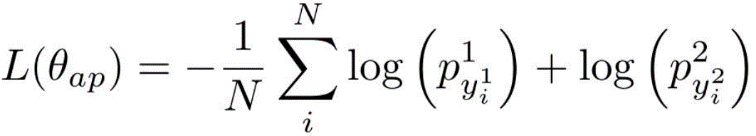
为了在多任务学习方法中联合训练生成模型和所提出的模块,训练过程中的总损失函数记为:
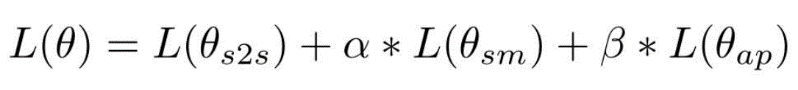
实验
作者在 SQuAD 和 MARCO 两个数据集上进行了实验,使用 NQG++[1]、Point-generator[2] 以及 SOTA 模型、门控自注意力机制模型等作为基线对比算法。表 3 给出了 SQuAD 和 MS-MARCO 数据集上不同模型的主要指标,在文章所述的实验条件下,本文提出的模型在全部主要指标上都优于基线对比算法。

总结
与现有的问答系统、问题生成模型的处理方式不同,本文并不是通过引入更多的有效特征或者改进复制机制本身等来改进模型效果,而是直接在经典序列-序列模型(seq-to-seq)中增加了两个模块:句子级语义匹配模块和答案位置推断模块。此外,利用答案感知门控融合机制来增强解码器的初始状态,从而进一步改进模型的处理效果。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



