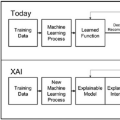
赛尔笔记 | 可解释的自然语言处理方法简介
作者:哈工大SCIR 杨重阳
1.介绍
传统的自然语言处理方法具有可解释性,这些自然语言处理方法包括基于规则的方法、决策树模型、隐马尔可夫模型、逻辑回归等,也被称为白盒技术。近年来,以语言嵌入作为特征的深度学习模型(黑盒技术)不断涌现,虽然这些方法在许多情况下显著提高了模型的性能,但在另一方面这些方法使模型变得难以解释。用户难以了解数据经过怎样的过程得到所期望的结果,进而产生许多问题,比如削弱了用户与系统之间的交互(如聊天机器人、推荐系统等)。机器学习社区对可解释性重要程度的认识日益增强,并创造了一个新兴的领域,称为可解释人工智能(XAI)。而关于可解释性有多种定义,大部分相关文章的论证也因此有所差异。这里我们关注的是可解释人工智能给用户提供关于模型如何得出结果的可解释,也称为结果解释问题(outcome explanation problem)[1]。在可解释人工智能中,解释可以帮助用户建立对基于NLP的人工智能系统的信任。本文依据前人的综述[2]讨论了可解释的分类方式,介绍了能够给出可解释的技术及其具体操作,并简要地描述了每一种技术及其代表性论文。
2.解释的分类
解释主要有两种分类方式[1][3]。
2.1局部解释与全局解释(Local vs Global)
局部解释是模型对特定输入的预测结果提供针对该预测结果的解释,全局解释是通过揭示模型预测的过程来解释如何预测,与特定的输入无关。
2.2自解释与事后解释(Self-Explaining vs Post-Hoc)
解释的分类除了按局部解释与全局解释划分,根据解释是作为预测过程的一部分,还是需要利用预测结果进行后处理得到,还存在另外一种分类方式,即自解释与事后解释。自解释方法,也可以称为直接解释(directly Interpretable)[4],利用在预测过程中产生的信息作为解释,解释与模型的预测结果同时产生。决策树和基于规则的模型是全局自解释模型,而注意力机制等显著性特征方法是局部自解释模型。事后解释的方法是在给出预测结果后需要执行额外的操作,LIME[5]使用简单的模型对复杂的模型进行解释,这里简单的模型是复杂的模型给出预测结果后的额外操作,该方法是局部事后解释的一个例子。
表1 解释的分类

3.可解释的技术
主要调研五种采用不同的机制给用户提供解释的可解释性技术。
3.1特征重要性(Feature Importance)
其主要思想是通过研究不同特征对最终预测结果的影响程度来得出解释。这些方法可以建立在不同类型的特征上,例如利用特征工程(feature engineering)[6]手动提取特征、word/token和n-gram等词法特征[7][8],或神经网络学习到的潜在特征[9]。注意力机制[10]和一阶导数显著性(first-derivative saliency)[11]是两个广泛使用的能够实现基于特征重要性的可解释技术。基于文本的特征本质上比一般特征更容易被人类解释,这也是为什么基于注意力机制的方法在NLP领域广泛使用。
3.2替代模型(Surrogate Model)
模型预测可以通过学习另一个具有可解释能力的模型作为代理来进行解释。一个非常典型的例子是LIME[5],它使用被称为输入扰动(input perturbation)的操作来学习一个效果相近的替代模型。基于替代模型的方法是模型无关的(model-agnostic),可用于实现局部[12]或全局[13]解释。然而,学习到的替代模型和原始模型可能有完全不同的机制来进行预测,这导致了人们对基于替代模型的方法是否忠于原模型持怀疑的态度。
3.3样例驱动(Example-driven)
这种方法通过识别和呈现其他与输入实例语义相似的已标注实例来解释输入实例的预测。它们在思想上类似于基于最近邻的方法[14],并已应用于不同的NLP任务,如文本分类[15]和问答[16]。
3.4溯源(Provenance-based)
通过展示部分或全部的预测推导过程,当最终的预测是一系列推理步骤的结果时,这是一种直观而有效的可解释性技术。在问答领域有很多工作采用了这种可解释方法[16][17][18]。
3.5陈述归纳(Declarative Induction)
在设计过程中直接使用人类可读、可理解的表示,如规则[19]、树结构[6]和程序(program)[20]直接作为解释。
4.实现解释的操作
4.1一阶导数显著性(First-derivative Saliency)
导数的大小(绝对值)表明了最终结果对一个特定维度的变化的敏感性,即该词的一个特定维度对最终决定的贡献程度。显著性的分数是由下面的公式所给出:
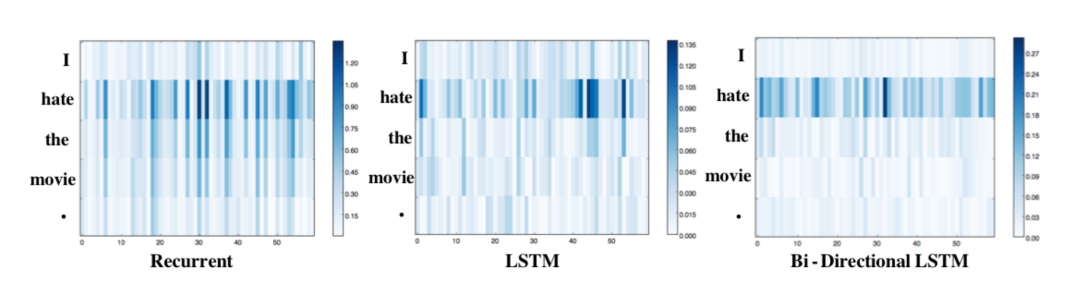
这三种模型中"hate"都具最高的显著性分数,并削弱了其他token的影响。LSTM比标准的循环模型更清晰地关注"hate",双向LSTM的效果最为明显,除了"hate"之外的单词,其他单词几乎没有影响。这可能是由于LSTMs和Bi-LSTMs中的门结构机制控制了信息流,使得这些架构能够更好地过滤掉不太相关的信息。此外一阶导数显著性常用于神经网络模型,因为可以通过单独调用深度学习引擎提供的自动求导来计算得到。最近的工作还提出了对一阶导数显著性的改进[21]。如其名称和定义所述,一阶导数显著性可以实现特征重要性的可解释,特别是在token-level的特征。
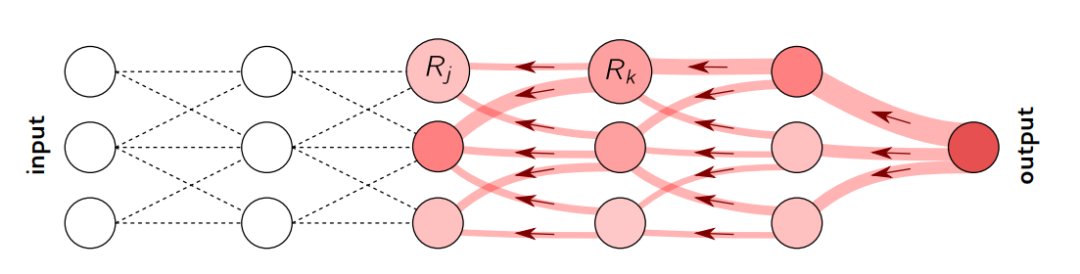
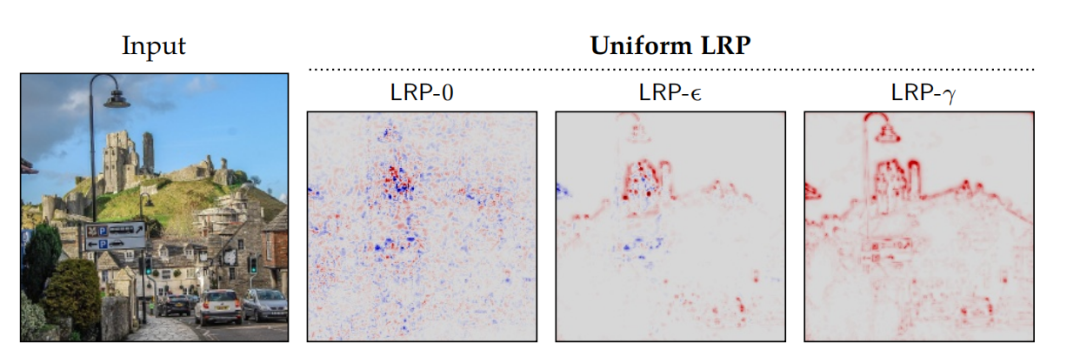
4.2相关性分数逐层传播(Layer-wise Relevance Propagation)
4.3输入扰动(Input Perturbations)
以LIME[5]模型举例,输入扰动可以通过生成输入x的随机扰动并训练一个可解释的模型(通常是一个线性模型)来解释输入x的输出。LIME 的主要思想是,通过训练一个模拟原模型但更简单的模型来解释原模型是如何做出预测的。因此,可以利用更简单的模型(也称为替代模型)来解释原始模型的预测。此方法不涉及模型内部,而是通过对输入进行大量且轻微的扰动(例如删除不同的单词),观察黑盒模型的输出所发生的变化,然后根据这些输入输出训练简单且可解释的模型。由于替代模型是一个简单的线性分类器,通过给每个单词分配一个权重来进行预测,因此我们可以看到分配给每个单词的权重来了解每个单词如何影响最终预测。最终得到的效果如下图所示:
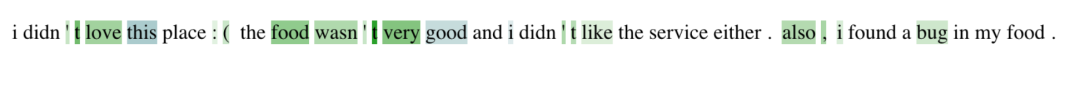
正如举例的LIME一样,这类操作常用于替代模型[5]12]。
4.4注意力机制(Attention)
Attention机制[10]是自然语言处理领域最常采用的可解释方法之一,其能在一系列任务上对模型性能产生显著的提升,尤其是基于循环神经网络结构的seq-to-seq模型。Attention机制模拟了人类理解语言时会集中注意到一些关键词的行为,实现的方式是权重分配。同时,前人将Attention层引入神经网络来实现特征重要性的可解释方法[8][9]。但是人们对其能做到哪种程度是不了解的。"Attention!注意力机制可解释吗?"这篇笔记里详细讨论了attention的可解释性(点击下方"阅读原文"可查看文章内容)。
4.5可解释的结构设计(Explainability-aware Architecture Design)
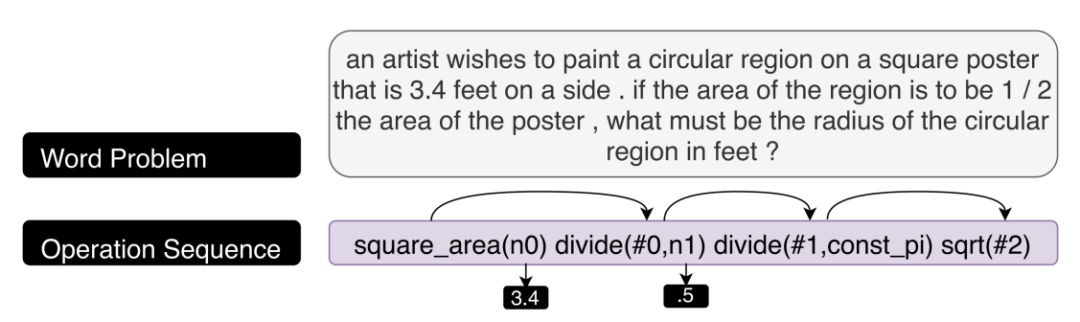
该方法通过模仿人类解决问题的过程设计神经网络架构,由于该架构包含模拟人类认知的组件,使得学习到的模型(部分)可解释。实现这样的模型架构可用于解决数学问题MathQA[18][20]或句子简化问题[24]。这种设计也可以应用于可解释的替代模型。以MathQA为例,在数学考试中,答题者经常被要求逐步给出答案是如何推导得到的,如果缺少推导中的任何关键步骤,那么答题者很大可能不能得到满分。MathQA模型利用可解释的结构设计试图重现这一推导过程。MathQA是一个大型英语多项选择数学问题的数据集,训练数据通过众包的方式进行标记。对于一个问题,参与标记者会被要求循环执行下面的步骤:首先选出一个操作(加、减、乘、除、平方等),然后从问题题干中或之前操作的计算结果中标记这个方法所需要的参数,直到获得的操作集合能够共同作用得出答案。在实际训练中希望获得的是一个encoder-decoder的结构,将输入的问题题干看作是编码后的数据,而目的是将其解码为一个以各种操作为元素的序列。通过这一序列,可以清楚的认识到整个求解过程。实例效果如下:
5.结论
本文讨论了解释的主要分类(局部解释与全局解释、自解释与事后解释),实现可解释的常用技术以及这些可解释技术的具体操作。除此以外,还有其他的可解释性操作,例如利用强化学习来进行简单否定规则的学习等[19]。可解释性人工智能仍然存在许多问题亟待解决,诸如对该领域相关概念更清晰的定义、可解释性更明确的理解,以及如何与目标建立联系等。未来期待更多的工作来完善该领域,促进用户与人工智能之间的交互。
参考资料
Guidotti R, Monreale A, Ruggieri S, et al. A Survey of Methods for Explaining Black Box Models[J]. ACM Comput. Surv., New York, NY, USA: Association for Computing Machinery, 2018, 51(5).
[2]Danilevsky M, Qian K, Aharonov R, et al. A Survey of the State of Explainable AI for Natural Language Processing[J]. 2020(Section 5).
[3]Tjoa E, Guan C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020: 1–21.
[4]Arya V, Bellamy R K E, Chen P-Y,et al. One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques[J]. 2019.
[5]Ribeiro M T, Singh S, Guestrin C. 《 Why should i trust you?》 Explaining the predictions of any classifier[A]. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining[C]. 2016: 1135–1144.
[6]Voskarides N, Meij E, Tsagkias M, et al. Learning to explain entity relationships in knowledge graphs[J]. ACL-IJCNLP 2015 - 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Proceedings of the Conference, 2015, 1: 564–574.
[7]Godin F, Demuynck K, Dambre J, et al. Explaining Character-Aware Neural Networks for Word-Level Prediction: Do They Discover Linguistic Rules?[J]. 2018.
[8]Mullenbach J, Wiegreffe S, Duke J, et al. Explainable Prediction of Medical Codes from Clinical Text[J]. 2018.
[9]Xie Q, Ma X, Dai Z, et al. An Interpretable Knowledge Transfer Model for Knowledge Base Completion[J]. 2017.
[10]Bahdanau D, Cho K H, Bengio Y. Neural machine translation by jointly learning to align and translate[A]. 3rd International Conference on Learning Representations, ICLR 2015[C]. 2015.
[11]Li J, Chen X, Hovy E H, et al. Visualizing and Understanding Neural Models in NLP[A]. HLT-NAACL[C]. 2016.
[12]Alvarez-Melis D, Jaakkola T. A causal framework for explaining the predictions of black-box sequence-to-sequence models[A]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing[C]. 2017: 412–421.
[13]Liu N, Huang X, Li J, et al. On interpretation of network embedding via taxonomy induction[A]. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining[C]. 2018: 1812–1820.
[14]Dudani S A. The distance-weighted k-nearest-neighbor rule[J]. IEEE Transactions on Systems, Man, and Cybernetics, IEEE, 1976(4): 325–327.
[15]Croce D, Rossini D, Basili R. Auditing deep learning processes through kernel-based explanatory models[A]. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)[C]. 2019: 4028–4037.
[16]Abujabal A, Roy R S, Yahya M, et al. Quint: Interpretable question answering over knowledge bases[A]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations[C]. 2017: 61–66.
[17]Zhou M, Huang M, Zhu X. An interpretable reasoning network for multi-relation question answering[J]. arXiv preprint arXiv:1801.04726, 2018.
[18]Amini A, Gabriel S, Lin S, et al. MathQA: Towards interpretable math word problem solving with operation-based formalisms[J]. arXiv, 2019: 2357–2367.
[19]Pröllochs N, Feuerriegel S, Neumann D. Learning interpretable negation rules via weak supervision at document level: A reinforcement learning approach[A]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies[C]. Association for Computational Linguistics, 2019, 1: 407–413.
[20]Ling W, Yogatama D, Dyer C, et al. Program induction by rationale generation: Learning to solve and explain algebraic word problems[J]. arXiv preprint arXiv:1705.04146, 2017.
[21]Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks[A]. International Conference on Machine Learning[C]. PMLR, 2017: 3319–3328.
[22]Poerner N, Roth B, Schütze H. Evaluating neural network explanation methods using hybrid documents and morphological agreement[J]. arXiv e-prints, 2018: arXiv-1801.
[23]Croce D, Rossini D, Basili R. Explaining non-linear classifier decisions within kernel-based deep architectures[A]. Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP[C]. 2018: 16–24.
[24]Dong Y, Li Z, Rezagholizadeh M, et al. EditNTS: An Neural Programmer-Interpreter Model for Sentence Simplification through Explicit Editing[A]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics[C]. 2019: 3393–3402.