论文浅尝 | SMBOP: Semi-autoregressive Bottom-up Semantic Parsing
笔记整理:陈永锐,东南大学博士
来源:NAACL 2021
概述
近年来语义解析的事实上的标准解码方法是使用自顶向下的深度优先遍历对目标程序的抽象语法树进行自回归解码。该工作提出了一种替代方法:半自回归自底向上解析器(SMBOP),它在解码步骤 t 构建高度为 t 的 top-K 子树。与自上而下的自回归解析相比,我们的解析器享有多项优势。
从效率的角度来看,自下而上的解析允许并行解码特定高度的所有子树,导致对数运行时复杂度而不是线性。
从建模的角度来看,自下而上的解析器在每一步学习有意义的语义子程序的表示,而不是语义空的部分树。
在Spider数据集上,与使用自回归解码的语义解析器相比,SMBOP 使解码时间加快了 2.2 倍,训练时间加快了 5 倍,获得了69.5%的完全匹配准确率, 71.1 %的执行准确率。
动机

尽管语义解析中的自下而上解码很少受到关注,它实际上存在几个优点。从效率的角度来看,自底向上解析自然可以半自回归完成:在每个解码步骤 t,解析器并行生成深度为 t 的 top-K 程序子树(类似于波束搜索)。这导致运行时复杂性在树的大小上是对数的,而不是线性的,可以提升效率。从建模的角度来看,神经自下而上的解析为有意义的(和可执行的)子程序提供了学习表示,这些子程序是在搜索过程中计算的子树。
上图说明了SMBOP解析器的单个解码步骤。 给定一个具有 K = 4 个高度为 t 的树(蓝色向量)的beam Zt,SMBOP使用cross-attention机制将树与来自输入问题(橙色)的信息关联起来。然后,对边界进行评分,即可以使用当前beam 的语法构造的所有高度为 t + 1 的树的集合,并保留 top-K 树(紫色)。最后,生成每个新 K 树的表示并将其放置在新的beam Zt+1 中。在 T 个解码步骤之后,解析器返回 ZT 中对应于完整程序的最高得分树。
SMBOP解析器
SMBOP算法如下所示:

在每一步 t,注意力都被用来将树与来自输入问题表示(第 5 行)的信息关联起来。这种表示用于对边界上的每棵树进行评分:深度为 t + 1 的子树集合,可以从梁上深度为 t 的子树(第 6-7 行)构建。在为步骤 t+1 选择前 K 棵树后,我们为它们计算一个新的表示(第 8 行)。最后,从最终解码步骤 T 中返回得分最高的树。SMBOP模型中的步骤独立地对树表示进行操作,因此每个步骤都被有效地并行化。
SMBOP 类似于波束搜索,因为在每个步骤中它都拥有固定高度的前 K 棵树。它也与(修剪的)图表解析有关,因为步骤 t + 1 处的树是根据在步骤 t 找到的树计算出来的。这与序列到序列模型不同,在序列到序列模型中,光束上的项目是相互竞争的假设,没有任何交互。
下图给出了SMBOP所使用的关系代数语法

模型架构

SMBOP 在每个解码步骤保持一个beam。与标准beam search不同,SMBOP波束上的树不仅相互竞争,而且相互组合(类似于图表解析)。SMBOP使用cross attention将beam上的树表示上下文化。接下来,计算边界上所有高度为t+1的树的分数。可以通过对梁树应用一元(包括 KEEP)运算或二元运算来生成树。我们为边界树定义了一个评分函数,其中通过在树 zi 上应用一元规则 u 生成的新树的评分定义如下:
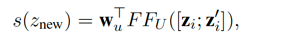
训练过程
为了指定损失函数,SMBOP定义了监督信号。给定正确 SQL 程序,将其转换为黄金平衡关系代数树。在训练期间,我们应用“自下而上的教师强制”,也就是说,我们用来自 Zgold 的所有树填充光束 Zt,然后用得分最高的非黄金预测树填充光束的其余部分(大小为 K)。这保证了我们将能够在每个解码步骤计算损失,如下所述。损失函数如下所示:

实验结果
该论文使用了Spider数据集进行了实验。

可见,SMBOP在执行准确率上取得了最优的结果。
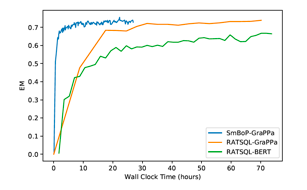
SMBOP在效率上也比自回归解码器更强。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

