你一直在用的Beam Search,是否真的有效?

NewBeeNLP公众号原创出品 公众号专栏作者 @Maple小七 北京邮电大学·模式识别与智能系统
来自EMNLP2020 最佳论文荣誉提名奖 的一篇工作

论文:If beam search is the answer, what was the question?[1]
源码: https://github.com/rycolab/uid-decoding
「Key insight:」 在序列生成模型中,增大beam search的搜索宽度反而会导致生成文本质量的下降,为了研究beam search隐含的归纳偏差,作者通过探索解码目标MAP的正则项,将beam search隐含的归纳偏差与认知科学中的均匀信息密度(UID)假说联系起来,通过实验证明了UID假说与文本质量的强相关性,以及beam search隐含的归纳偏差使得模型能够生成更符合UID假设的文本,恰好弥补了模型本身的误差。
Introduction
beam search是神经序列生成模型最基本的解码算法,最早出现于1970年,虽然NLP模型的结构在不断地更新,但在模型解码阶段beam search几乎一直都是大家默认的选择,因此beam search可以说是NLP系统的一个基石。beam search作为一种启发式搜索算法,并不能保证或是有效逼近全局最优解,但大量实践表明beam search给出的结果几乎总是令人满意的。
然而,在machine translation、image captioning等涉及语言生成的研究领域中,有一个令人震惊甚至不安的事实是:「增大beam search的搜索宽度 反而会导致BLEU和ROUGE分数的下降」,而传统的SMT(如phrase-based MT)与NMT恰恰相反,对SMT来说,搜索宽度是越大越好的( ),而NMT的 值一般不超过5。
直观上来看,加大搜索宽度 理应搜索到似然概率更高的候选句,当 时,beam search将等价于exact search,即能够搜索到全局最优序列。然而实验表明该全局最优序列的BLEU分数往往很低,有时候全局最优序列甚至是空字符串,这充分表明模型建立的 是有问题的,而beam search隐含的归纳偏差恰好在一定程度上校准了模型本身的误差。综上,beam search的反常现象被认为是机器翻译面临的六大挑战之一(Koehn & Knowles, 2017[2])。
Related Work
已经有不少研究都论述了这个问题,On NMT Search Errors and Model Errors(EMNLP 2019)[3]一文给出了一种求得全局最优解的解码方法(exact search),即利用生成序列得分的单调性
可以过滤掉绝大部分不必要的搜索路径,但做一次exact search的时间开销还是非常大的。作者发现beam search给出的解在绝大多数情况下都没有足够接近exact search给出的解,但exact search生成的文本的BLEU分数比beam search要糟糕得多,「这说明beam search的成功并不是因为它能够很好地逼近exact search,而是因为beam search算法本身有良好的inductive bias,恰好抵消了模型本身的误差。」
Breaking the Beam Search Curse(EMNLP 2018)[4]一文发现BLEU的下降主要是因为模型更偏好更短的句子,从而导致了BLEU中的brevity penalty项减小,而句子长度的减小是因为搜索宽度的增加会使得算法更容易找到<eos>。因此实践中常会给解码目标加上长度正则化[5](Length Normalization),不过,虽然长度正则化可以在一定程度上减轻这种现象,但并不能完全消除它,当搜索宽度增大时,BLEU仍会发生明显的下降,这篇文章也没有从理论上解释为什么模型更偏好短句。
也有不少研究给出了一些启发式的方法来约束beam search(Empirical analysis of beam search performance degradation(ICML 2019)[6]),但还没有人深入讨论beam search本身的inductive bias到底是什么,本文作者引用了认知科学中被广泛承认的「uniform information density hypothesis」来解释了beam search隐含的归纳偏差是什么以及为什么beam search生成的句子更符合人类的认知。
Neural Probabilistic Text Generation
首先简要介绍一下beam search算法的基本形式,通常的概率文本生成模型在假设空间 上定义了一个条件概率分布
其中 是词汇表 的克林闭包,模型的解码目标是找到似然概率最大的假设,即最大化后验概率(MAP):
由于多数模型的解码过程不具有马尔可夫性,因此动态规划是不适用的,实际上,RNN的解码过程已经被证明是一个NP-hard问题[7]。因此解码过程几乎只能采用启发式方法,比如beam search。
Beam Search
beam search是一种截断的广度优先搜索,可以看作是greedy search的简单推广,beam search可表示为
其中每个时刻 的候选集为 。虽然解码目标是要求得似然概率最高的假设,但我们也可以度量整个候选集的似然概率
而beam search实际上就是集合版本的greedy search。
Alternative Decoding Objectives
单纯采用上面的MAP目标函数生成的文本通常不够理想,其中一个问题是模型生成的文本通常很短且偏向于使用高频词,因此有不少工作是在MAP的基础上加入一些正则化来增强解码目标,比如最经典的长度正则化
和面向attention结构的覆盖度正则化(鼓励attention不要过度集中在一个input token上)
虽然这些方法能够提高生成文本的质量,但都只是启发式的改进,没有发现和解决本质的问题,当增大beam search的搜索宽度时,这些正则化方法生成的文本质量还是会明显的下降。
Deriving Beam Search
我们可以将上述的正则化方法统一为 :
如何更好地设计适合beam search的 呢?我们不如反过来思考这个问题:如果想将beam search转化为exact search, 应该如何确定?
既然beam search是greedy search的推广,那我们就先考虑greedy search。greedy search在每一步选择似然概率最高的token,将这个过程转化为信息论的语言,就是greedy search在每一步选择自信息最少的token(论文中作者用surprisal这个概念来指代self-information),或者说,给人带来的困惑最少的token。因此作者给出了「时序自信息」(time-dependent surprisal)的概念:
刻画的是在 时刻生成单词 的自信息。我们考虑给greedy search加上如下的正则项
直观上来看,该正则项鼓励在每一步都选择自信息最少,或者说概率最高的token。不难看出,当 时,对正则化前的优化目标做greedy search等价于对正则化后的优化目标 做exact search,我们可以将这一结论推广到beam search上,即解码的目标函数为
其中 被定义为
不难证明,「当 时,宽度为 的beam search对原始优化目标求得的解正是加上正则化项后的优化目标的全局最优解。」
From Beam Search to UID
beam search在每一步给出似然概率最大的大小为 的候选集,从信息论的角度来看,就是保证每一步生成的单词所带来的信息量最小,因此这样搜索到的句子的信息量就倾向于均匀分布在每一个单词中,而exact search给出的全局最优解可能会为了追求整体的似然概率最大而给出信息分布不均衡的序列。
作者将这样的想法和认知科学领域中的**均匀信息密度假说**[8](Uniform Information Density hypothesis,UID)联系了起来,UID假说于2010年正式提出,已经有不少研究倾向于承认该假说是成立的:
在语法定义的范围内,说话者更喜欢信息密度更均匀的话语。当说话者可以在几种语法变体之间来选择如何编码他们的信息时,他们喜欢信息密度更一致的变体(其他条件不变)
UID假设源于语法归约的研究,比如考虑How big is the family (that) you cook for?这句话,省略that并不会影响句子整体的语义,但人类往往偏好加上that这个过渡词,因为这会让句子的理解更轻松,而去掉that后you将要承担更大的信息量,它既要指示从句的开始,又是从句本身的一部分。因此加入that会分散you的信息量,让整个句子的信息密度更均匀。也就是说,「当从句前面积累的信息量太大时,说话者就会把that强调出来,让听众在消化主句信息的同时更好地接受从句中的信息。」 由于UID假说涉及人类的认知过程,因此可以认为它是不受语种限制的,所有语言应该都存在UID现象。
不过UID假设有一个前提条件,即候选的句子应该都是「符合语法」且具有「相同语义」的,否则在测量或优化句子的信息密度时会引入其他的干扰因素。作者认为我们有理由相信生成模型赋予高似然概率的候选句子通常是语法正确的;另外尽管候选句子之前的语义不完全等价,但都倾向于表达相似的语义,因为它们都是和输入高度相关的。因此,「有理由认为上一节提到的优化目标中的 奖励生成句子的语法正确性和内容相关性,而 奖励更符合人类偏好或更符合UID假设的句子。」
The UID Bias in Beam Search
作者给出了机器翻译中的一个极端例子,即exact search给出的翻译是一个空字符串。当我们对MAP优化目标加入作者提出的正则化项后,随着 的增大,exact search解码出的句子质量就提高了很多,即更遵循UID假设。当 时,exact search给出了和beam search( )一样的结果。
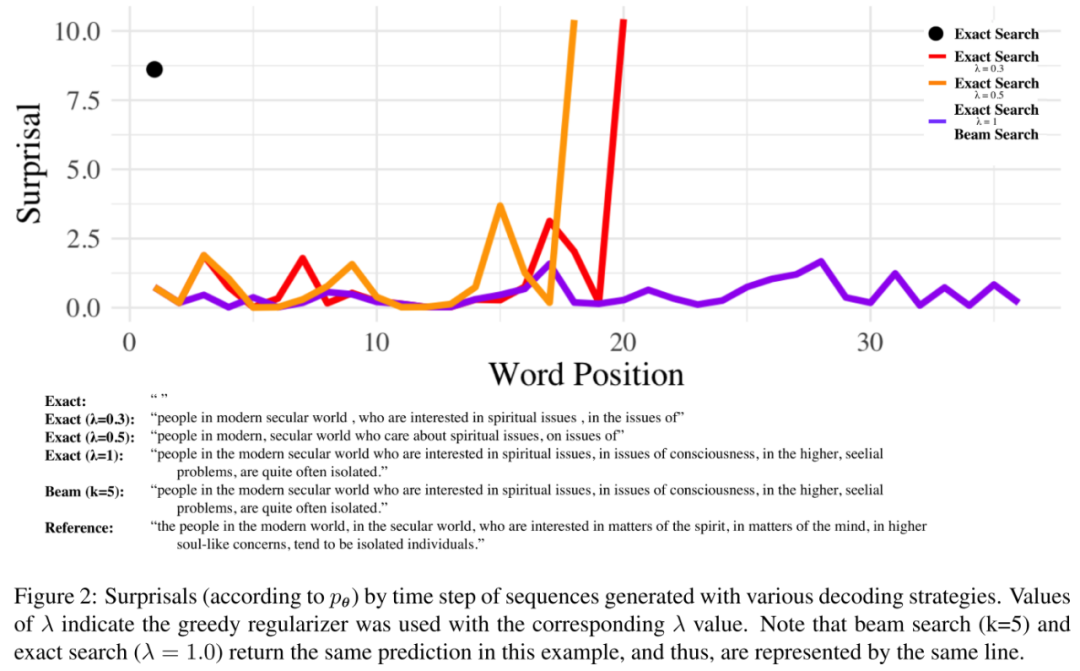
从上图中可以发现,一个全局最优解码的方案可能会在某个时间点选择一些高自信息的token来缩短生成句子的长度或是在后续的生成中能够选择低自信息的token,而加入了UID正则化项的优化目标生成的序列每个词的自信息都比较小且接近,从翻译结果上来看,也更符合人类的偏好(比如使用了更多的the)
Cognitive Motivation for Beam Search
综上,作者首先证明了beam search在特定的正则项约束下可以转化为一个精确的解码方式,然后将该正则项的表现和UID假设联系在了一起,因此作者认为beam search的成功在于它的搜索过程隐式地包含了UID假设,从而能够生成更符合人类习惯的句子。
Generalized UID Decoding
当然,UID只是一个概念,并非只有一种数学表达的方式,因此作者还给出并验证了如下的 :
「Variance Regularizer」
UID关注信息在整个句子中的分布,因此我们可以用每一时刻的自信息的方差来度量信息分布的均匀程度:
「Local Consistency」
该正则项鼓励相邻的词的自信息大小相近,如果每一个词的自信息都和上下文相近,则信息将倾向于均匀分布在句子的每个词中:
「Max Regularizer」
只惩罚句子中那些自信息最高的词:
「Squared Regularizer」
将每个词的自信息都按平方推向0:
这些Regularizer从不同的角度来对MAP增加UID约束,它们的实际表现差距应该不会很大。
Experiments
作者在机器翻译任务(IWSLT'14 De-En, WMT'14 En-Fr)上验证UID正则化的有效性,由于只是对解码过程做实验,不需要自己建立模型,所以作者直接调用了fairseq中基于Transformer的翻译模型,作者在不同的正则化强度 下,在测试集上使用Dijkstra算法求得上述加上UID正则项的优化目标的全局最优解,然后使用SacreBLEU评分系统为生成的翻译打分。
Exact Decoding
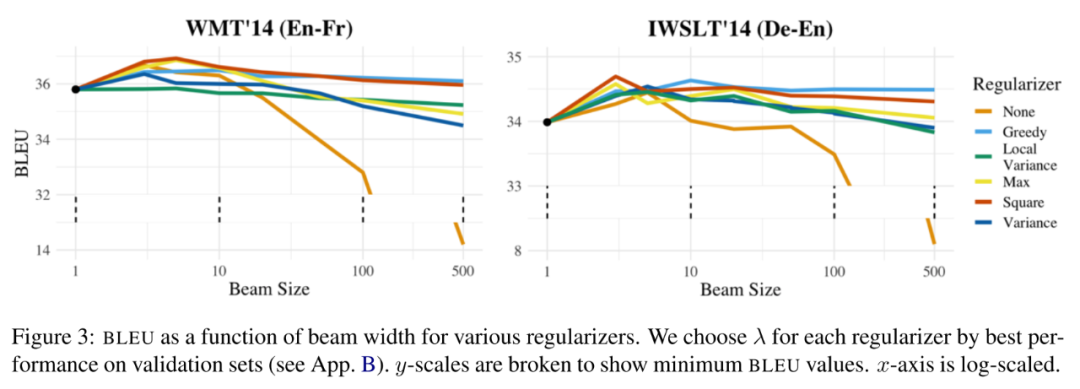
下图展示了随着正则化强度 的增加,全局最优解的BLEU分数和信息分布(自信息标准差)的变化趋势。可以发现,随着UID正则强度越来越大,exact search给出的翻译BLEU分数也逐渐提升,最后趋近于beam search( )给出的结果,同时生成序列的信息分布也越来越均匀。
另外,小图显示了BLEU分数和自信息标准差强烈的负相关关系( ),这表明UID假设的确是有效的。
Regularized Beam Search
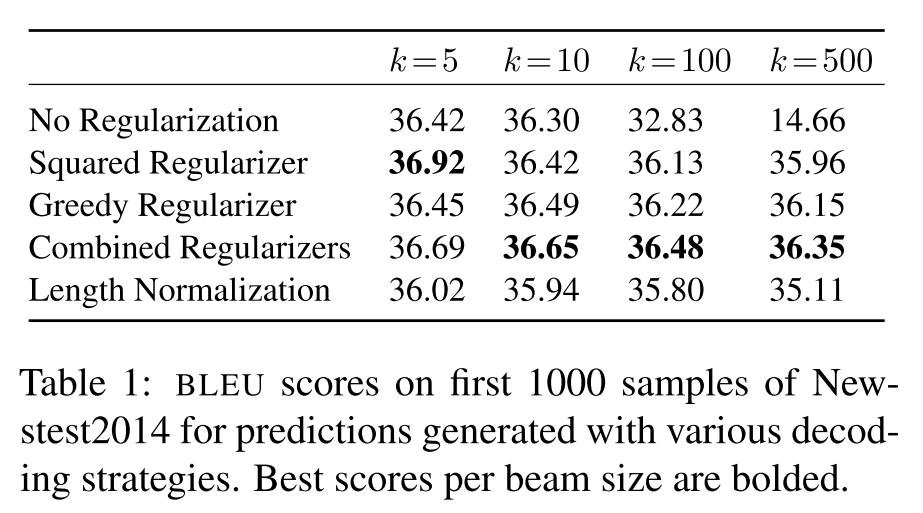
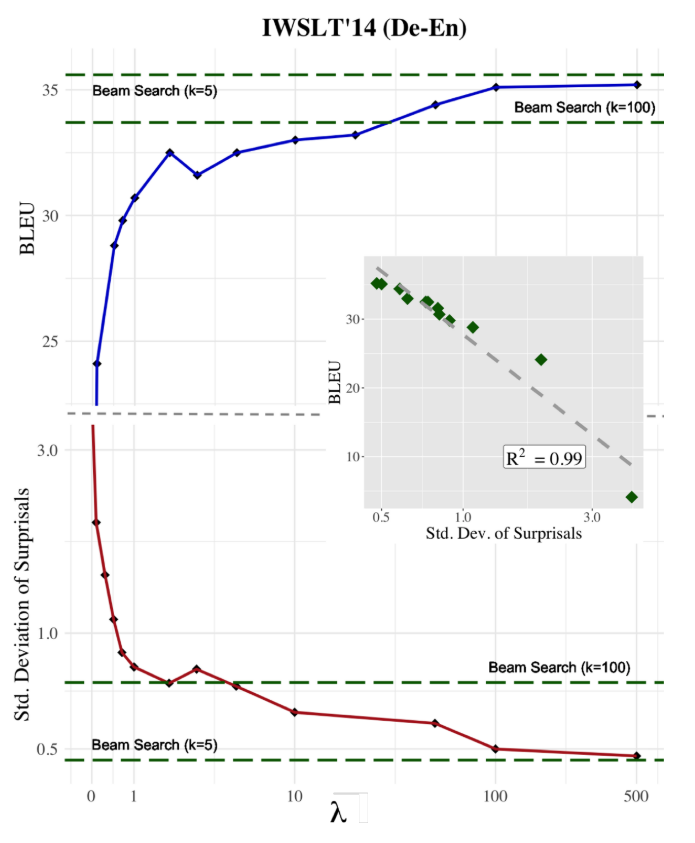
之前提到,在使用标准的MAP目标函数生成文本时,随着beam size的增大,文本质量会下降,因此作者测试了用beam search来解码加上UID正则化的目标函数,以验证UID正则化的有效性。
如下图所示,随着beam size的增大,比起标准的MAP,加上UID正则化的优化目标更不易受到影响,其中greedy正则化和square正则化表现最好,不过还是有一些轻微的下降,但和没有加正则化的MAP相比这点下降是微不足道的。
Discussing
-
需要注意的是,这篇论文只解释了beam search为什么好,但是没有解释exact search为什么这么糟糕,而后者实际上是更值得关注的问题,因为这表明模型本身是有问题的,也许是设计的目标函数和人类的认知不一致,也许用链式法则来建模句子是错的,也许是训练和测试的不一致导致的,而总是做次优决策的解码方式弥补了模型的不足。另外,我们也不能仅仅通过对解码的过程加正则项来优化决策,因为此时的得分已经不是单纯的似然概率了,增加的正则项并不是模型所训练的目标。
-
UID假设本身还是有一些启发式的感觉,UID假设本身是否站得住脚也是需要商榷的,毕竟人类的语言不能用一条假设就完全概括。实际上有一些研究认为UID虽然对句法归约比较有效,但在其他的语言现象中(如词序变换、句法变换)存在一些明显与UID假设相悖的结论[9]。
本文参考资料
If beam search is the answer, what was the question?: https://arxiv.org/abs/2010.02650
[2]Koehn & Knowles, 2017: https://www.aclweb.org/anthology/W17-3204/
[3]On NMT Search Errors and Model Errors(EMNLP 2019): https://arxiv.org/abs/1908.10090
[4]Breaking the Beam Search Curse(EMNLP 2018): https://www.aclweb.org/anthology/D18-1342.pdf
[5]长度正则化: https://arxiv.org/abs/1409.0473
[6]Empirical analysis of beam search performance degradation(ICML 2019): http://proceedings.mlr.press/v97/cohen19a.html
[7]NP-hard问题: https://arxiv.org/abs/1711.05408?context=cs.CC
[8]「均匀信息密度假说」: http://papers.nips.cc/paper/3129-speakers-optimize-information-density-through-syntactic-reduction.pdf
[9]相悖的结论: https://www.aclweb.org/anthology/W18-4605/
[10]Machine Translation Weekly 20: Search and Model Errors in Neural Machine translation: https://jlibovicky.github.io/2019/11/21/MT-Weekly-Search-and-Model-Errors.html
[11]Musings on typicality: https://benanne.github.io/2020/09/01/typicality.html
- END -

由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


