学习如何学习的算法:简述元学习研究方向现状

选自TowardsDataScience
作者:Cody Marie Wild
机器之心编译
参与:李诗萌、李泽南
要想实现足够聪明的人工智能,算法必须学会如何学习。很多研究者们曾对此提出过不同的解决方案,其中包括 UC Berkeley 的研究人员提出的与模型无关的元学习(MAML)方法。本文将以 MAML 为例对目前的元学习方向进行简要介绍。
对我而言,第一次听到元学习的预述时,是一个极其兴奋的过程:建立不仅能够进行学习,还能学会如何进行学习的机器项目。元学习试图开发出可以根据性能信号做出响应,从而对结构基础层次以及参数空间进行修改的算法,这些算法在新环境中可以利用之前积累的经验。简言之:当未来主义者们编织通用 AI 的梦想时,这些算法是实现梦想必不可少的组成部分。
本文的目的在于将这个问题的高度降低,从我们想得到的、自我修正算法做得到的事情出发,到这个领域现在的发展状况:算法取得的成就、局限性,以及我们离强大的多任务智能有多远。
为什么人类可以做到这些事?
具体地讲:在许多强化学习任务中,和人类花费的时间相比,算法需要花费惊人的时间对任务进行学习;在玩 Atari 游戏时,机器需要 83 小时(或 1800 万帧)才能有人类几小时就能有的表现。
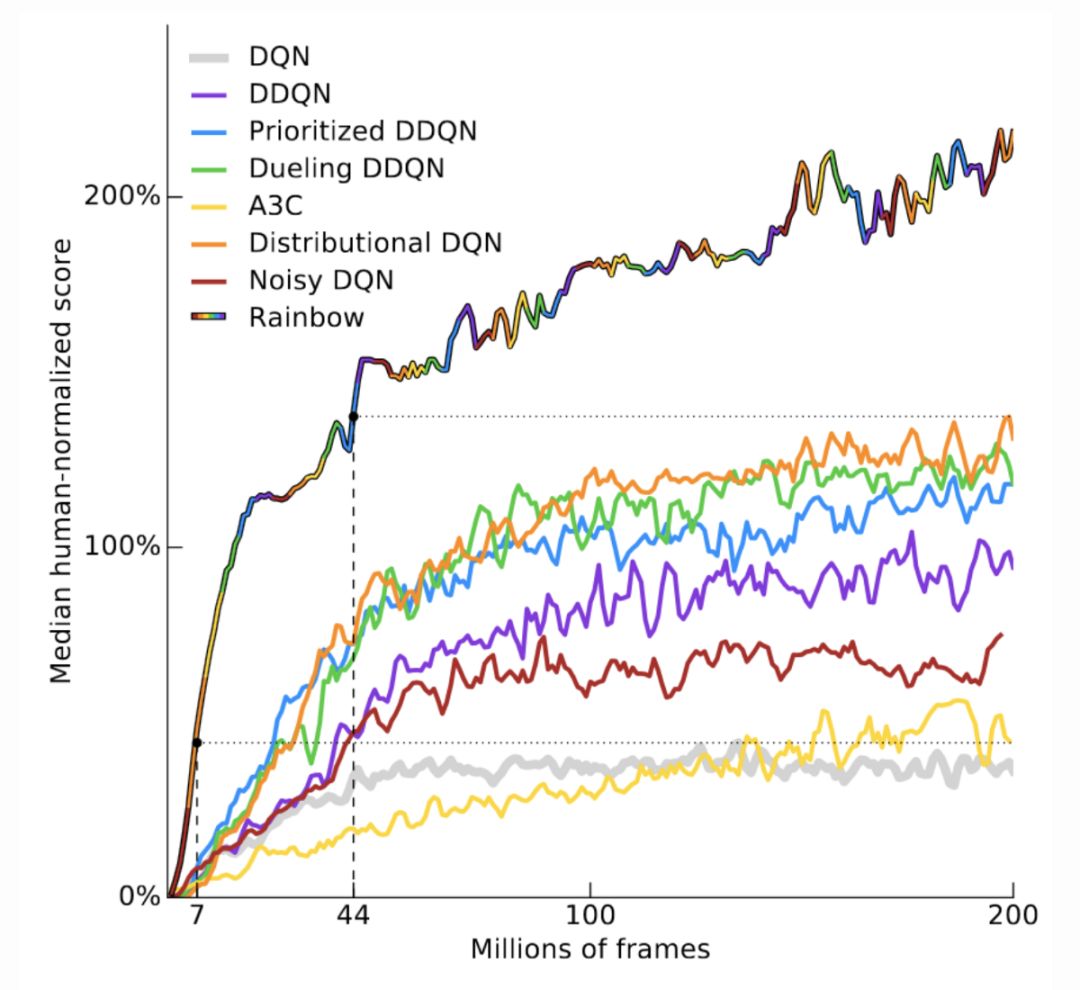
来自近期 Rainbow RL 论文中的图片
这种差异导致机器学习研究人员将问题设计为:人类大脑中针对这项任务使用的工具和能力是什么,以及我们如何用统计和信息理论的方法转化这些工具。针对该问题,元学习研究人员提出了两种主要理论,这两种理论大致与这些工具相关。
学习的先验:人类可以很快地学会新任务是因为我们可以利用在过去的任务中学到的信息,比如物体在空间里移动的直观的物理知识,或者是在游戏中掉血得到的奖励会比较低这样的元知识。
学习的策略:在我们的生活中(也许是从进化时间上讲的),我们收集的不仅是关于这个世界对象级的信息,还生成了一种神经结构,这种神经结构在将输入转化为输出或策略的问题上的效率更高,即使是在新环境中也不例外。
显然,这两个想法并非互相排斥,在这两个想法间也没有严格的界限:一些与现在的世界交互的硬编码策略可能是基于这个世界的深度先验的,例如(至少就本文而言)这个世界是有因果结构的。也就是说,我认为这个世界上的事情都可以用这两个标签分开,而且可以将这两个标签看作相关轴的极点。
不要丢弃我的(单)样本
在深入探讨元学习之前,了解单样本学习相关领域的一些概念是很有用的。元学习的问题在于「我该如何建立一个可以很快学习新任务的模型」,而单样本学习的问题在于「我该如何建立一个在看过一类的一个样本后,就能学会该如何将这一类分出来的模型」。
让我们从概念上思考一下:是什么让单样本学习变得困难?如果我们仅用相关类别的一个样本试着训练一个原始模型,这个模型几乎肯定会过拟合。如果一个模型只看过一幅图,比如数字 3,这个模型就无法理解一张图经过什么样的像素变化,仍然保持 3 的基本特征。例如,如果这个模型只显示了下面这列数字的前三个样本,它怎么会知道第二个 3 是同一类的一个样本呢?理论上讲,在网络学习中,我们想要的类别标签有可能与字母的粗细程度有关吗?对我们而言做出这样的推断这很傻,但是在只有一个「3」的样本的情况下,想让神经网络能做出这样的推理就很困难了。
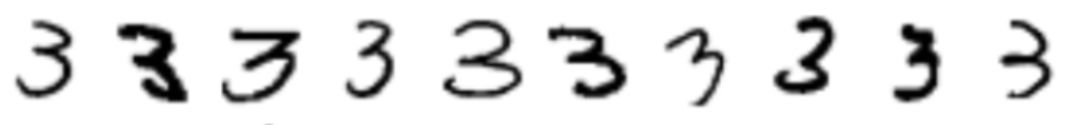
有更多样本会有助于解决这一问题,因为我们可以学习一张图中什么样的特征可以定义其主要特征——两个凸的形状,大部分是垂直的方向,以及无关紧要的改变——线的粗细、还有角度。为了成功实现单样本学习,我们不得不激励网络,在没有给出每一个数字间差别的情况下,学习什么样的表征可以将一个数字从其他数字中区别出来。
单样本学习的常用技术是学习一个嵌入空间,在这个空间中计算出两个样本表征间的欧几里德相似性,这能很好地计算出这两个样本是否属于同一类。直观地讲,这需要学习分布中类别间差异的内部维度(在我的样本中,分布在数字中),并学习如何将输入压缩和转换成那些最相关的维度。
我发现记住这个问题是一个很有用的基础,尽管不是学习如何总结存在于类别分布中的碎片化信息和模式,而是学习存在于任务中的类的分布规律,每一类都有自己的内部结构或目标。
如果要从最抽象开始,构造一个神经网络元参数的等级,会有点像这样:
通过使用超参数梯度下降,网络从任务的全部分布中学习到有用的表征。MAML 和 Reptile 是有关于此的直接的好例子,分享层级结构的元学习是一种有趣的方法,这种方法可以通过主策略的控制学习到清晰的子策略作为表征。
网络学习要优化梯度下降的参数。这些参数就像是学习率、动量以及权重之于自适应学习率算法。我们在此沿着修改学习算法本身的轨道修改参数,但是有局限性。这就是 Learning to Learn By Gradient Descent by Gradient Descent 所做的。是的,这就是这篇文章真正的标题。
一个学习内部优化器的网络,内部优化器本身就是一个网络。也就是说,使用梯度下降更新神经优化器网络参数使得网络在整个项目中获得很好的表现,但是在网络中每个项目从输入数据到输出预测结果的映射都是由网络指导的。这就是 RL² 和 A Simple Neural Attentive Meta Learner 起作用的原因。
为了使这篇文章更简明,我将主要叙述 1 和 3,以说明这个问题的两个概念性的结局。
其他名称的任务
另一个简短的问题——我保证是最后一个——我希望澄清一个可能会造成困惑的话题。一般而言,在元学习的讨论中,你会看到「任务分布」的提法。你可能会注意到这个概念定义不明,而你的注意是对的。对于一个问题是一个任务还是多个任务中的一个分布,人们似乎还没有明确的标准。例如,我们应该将 ImageNet 视为一个任务——目标识别——还是许多任务——识别狗是一个任务而识别猫是另一个任务呢?为什么将玩 Atari 游戏视为一个任务,而不是将游戏的每一个等级作为一个独立任务的几个任务?
我能得到的有:
「任务」的概念是用已经建立的数据集进行卷积,从而可以自然地将在一个数据集上进行学习认为是单个任务
对于任何给定分布的任务,这些任务之间的不同之处都是非常显著的(例如,每一个学习振幅不同的正弦曲线的任务和每一个在玩不同 Atari 游戏的任务之间的差别)
所以,这不仅仅是说「啊,这个方法可以推广到这个任务分配的例子上,所以这是一个很好的指标,这个指标可以在任务中一些任意且不同的分布上表现良好」。从方法角度上讲,这当然不是方法有效的不好的证据,但我们确实需要用批判性思维考虑这种网络要表现出多大的灵活性才能在所有任务中都能表现出色。
那些令人费解的动物命名的方法
在 2017 年早些时候,Chelsea Finn 及其来自 UC Berkeley 的团队就有了叫做 MAML的方法。
MAML(Model Agnostic Meta Learning,与模型无关的元学习)参见:与模型无关的元学习,UC Berkeley 提出一种可推广到各类任务的元学习方法。

如果你有心想要了解一下,请转向本文的「MAML 的种类」部分。
在学习策略和学习先验之间,这种方法更倾向于后者。这种网络的目标在于训练一个模型,给新任务一步梯度更新,就可以很好地归纳该任务。就像是伪代码算法。
1. 初始化网络参数 θ。
2. 在分布任务 T 中选择一些任务 t。从训练集中取出 k 个样本,在当前参数集所在位置执行一步梯度步骤,最终得到一组参数。
3. 用最后一组参数在测试集中测试评估模型性能。
4. 然后,取初始参数θ作为任务 t 测试集性能的梯度。然后根据这一梯度更新参数。回到第一步,使用刚刚更新过的θ作为这一步的初始θ值。
这是在做什么?从抽象层面上讲,这是在寻找参数空间中的一个点,就分布任务中的许多任务而言,这个点是最接近好的泛化点的。你也可以认为这迫使模型在探索参数空间时保留了一些不确定性和谨慎性。简单说,一个认为梯度能完全表示母体分布的网络,可能会进入一个损失特别低的区域,MAML 会做出更多激励行为来找到一个靠近多个峰顶端的区域,这些峰每一个的损失都很低。正是这种谨慎的激励使 MAML 不会像一般通过少量来自新任务的样本训练的模型一样过拟合。
2018 年的早些时候文献中提出了一种叫做 Reptile 的更新方法。正如你可能从它的名字中猜出来的那样——从更早的 MAML 中猜——Reptile 来自 MAML 的预述,但是找到了一种计算循环更新初始化参数的方法,这种方法的计算效率会更高。MAML 明确取出与初始化参数 θ 相关的测试集损失的梯度,Reptile 仅在每项任务中执行了 SGD 更新的几步,然后用更新结束时的权重和初始权重的差异,作为更新初始权重的梯度。
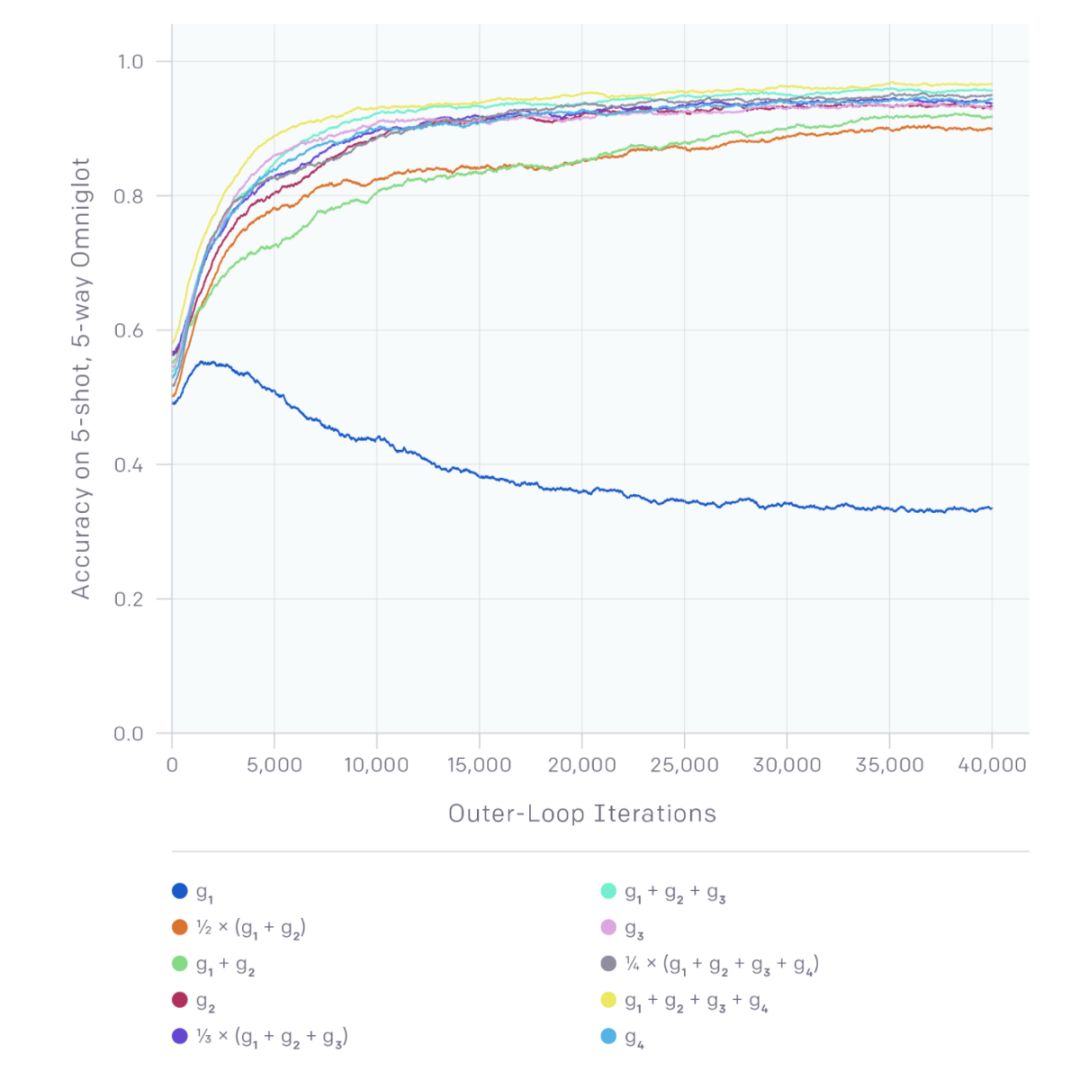
g_1 在此表示每个任务只执行一次梯度下降步骤得到的更新后的梯度。
这项工作从根本上讲有一些奇怪——这看起来和将所有任务合并为一个任务对模型进行训练没有任何不同。然而,作者提出,由于对每项任务都使用了 SGD 的多个步骤,每个任务损失函数的二次导数则被赋予影响力。为了做到这一点,他们将更新分为两部分:
1. 任务会得到「联合训练损失」的结果,也就是说,你会得到用合并的任务作为数据集训练出来的结果。
2. SGD 小批次梯度都是接近的:也就是说,在通过小批次后,梯度下降的程度很低。
我选择 MAML/Reptile 组作为「学习先验」的代表,因为从理论上讲,这个网络通过对内部表征进行学习,不仅有助于对任务的全部分布进行分类,还可以使表征与参数空间接近,从而使表征得到广泛应用。
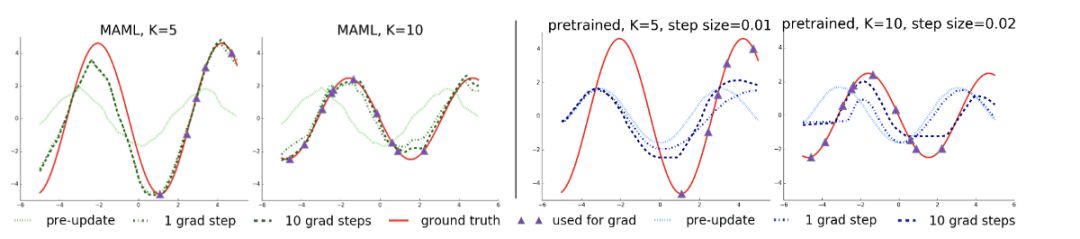
为了对这个点进行分类,我们先看一下上图。上图对 MAML 和预训练网络进行比较,这两个网络都用一组由不同相位与振幅组成的正弦曲线回归任务训练。在这个点上,两者针对新的特定任务都进行了「微调」:红色曲线所示。紫色三角代表少数梯度步骤中使用的数据点。与预训练模型相比,MAML 学到了,正弦曲线具有周期性结构:在 K=5 时,它可以在没有观察到这一区域数据的情况下更快地将左边的峰值移到正确的地方。尽管很难判断我们的解释是不是网络的真正机制,但我们可以推断 MAML 在算出两个相关正弦曲线不同之处——相位和振幅——方面做得更好,那么是如何从这些已给数据的表征进行学习的呢?
网络一路向下

对一些人来说,他们的想法是使用已知算法,例如梯度下降,来对全局先验进行学习。但是谁说已经设计出来的算法就是最高效的呢?难道我们不能学到更好的方法吗?
这就是 RL²(通过慢速强化学习进行快速强化学习)所采用的方法。这个模型的基础结构式循环神经网络(具体来说,是一个 LTSM 网络)。因为 RNN 可以储存状态信息,还可以给出不同输出并将这些输出作为该状态的函数,理论上讲这就有可能学到任意可计算的算法:也就是说它们都具有图灵完备的潜力。以此为基础,RL² 的作者构建了一个 RNN,每一个用于训练 RNN 的「序列」都是一组具有特定 MDP(Markov Decision Process,马尔科夫决策过程。从这个角度解释,你只需将每次 MDP 看作环境中定义一系列可能行为且通过这些行为产生奖励)的经验集合。接着会在许多序列上训练这个 RNN,像一般的 RNN 一样,这是为了对应多个不同的 MDP,可以对 RNN 的参数进行优化,可以使所有序列或试验中产生的遗憾(regret)较低。遗憾(regret)是一个可以捕获你一组事件中所有奖励的指标,所以除了激励网络在试验结束时得到更好的策略之外,它还可以激励网络更快地进行学习,因此会在低回报政策中更少地使用探索性行为。
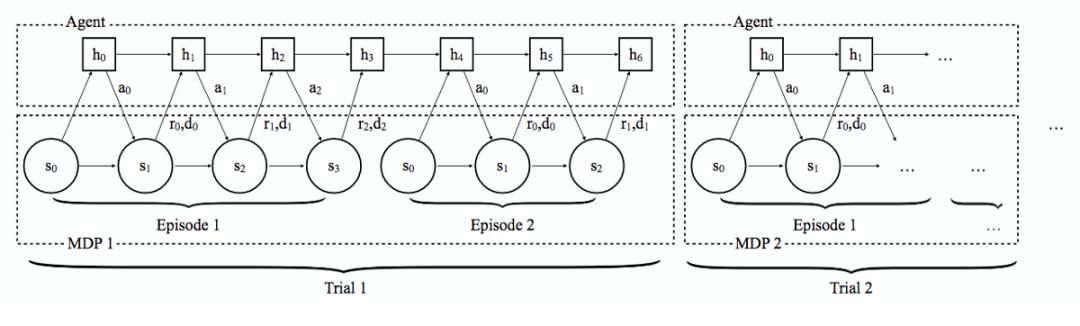
图中显示的是运行在多重试验上的 RNN 的内部工作,对应多个不同的 MDP。
在试验中的每一个点,网络都会通过在多个任务和隐藏状态的内容学习权重矩阵参数化函数,隐藏状态的内容是作为数据函数进行更新并充当一类动态参数集合。所以,RNN 学习的是如何更新隐藏状态的权重。然后,在一个给定的任务中,隐藏状态可以捕获关于网络确定性以及时间是用于探索还是利用的信息。作为数据函数,它可以看得到特定任务。从这个意义上讲,RNN 在学习一个可以决定如何能最好地探索空间、还可以更新其最好策略概念的算法,同时使该算法在任务的一组分布上得到很好的效果。该作者对 RL² 的架构和对任务进行渐进优化的算法进行比较,RL² 的表现与其相当。
我们可以扩展这种方法吗?
本文只是该领域一个非常简要的介绍,我肯定遗漏了很多想法和概念。如果你需要更多(信息更加丰富)的看法,我高度推荐这篇 Chelsea Finn 的博客,此人也是 MAML 论文的第一作者。
在这几周的过程中,我试着对这篇文章从概念上进行压缩,并试着对这篇文章进行理解,在这一过程中我产生了一系列问题:
这些方法该如何应用于更多样的任务?这些文章大多是在多样性较低的任务分布中从概念上进行了验证:参数不同的正弦曲线、参数不同的躲避老虎机、不同语言的字符识别。对我而言,在这些任务上做得好不代表在复杂程度不同、模式不同的任务上也可以有很好的表现,例如图像识别、问答和逻辑问题结合的任务。然而,人类的大脑确实从这些高度不同的任务集中形成了先验性,可以在不同的任务中来回传递关于这个世界的信息。我的主要问题在于:这些方法在这些更多样的任务中是否会像宣传的一样,只要你抛出更多单元进行计算就可以吗?或在任务多样性曲线上的一些点是否存在非线性效应,这样在这些多样性较低的任务中起作用的方法在高多样性的任务中就不会起作用了。
这些方法依赖的计算量有多大?这些文章中的大部分都旨在小而简单的数据集中进行操作的部分原因是,每当你训练一次,这一次就包括一个内部循环,这个内部循环则包含(有效地)用元参数效果相关的数据点训练模型,以及测试,这都是需要耗费相当大时间和计算量的。考虑到近期摩尔定律渐渐失效,在 Google 以外的地方对这些方法进行应用研究的可能性有多大?每个针对困难问题的内部循环迭代可能在 GPU 上运行数百个小时,在哪能有这样的条件呢?
这些方法与寻找能清晰对这个世界的先验进行编码的想法相比又如何呢?在人类世界中一个价值极高的工具就是语言。从机器学习方面而言,是将高度压缩的信息嵌入我们知道该如何转换概念的空间中,然后我们才可以将这些信息从一个人传递给另一个人。没人可以仅从自己的经验中就提取出这些信息,所以除非我们找出如何做出与学习算法相似的事,否则我怀疑我们是否真的可以通过整合这个世界上的知识建立模型,从而解决问题。

原文链接:https://towardsdatascience.com/learning-about-algorithms-that-learn-to-learn-9022f2fa3dd5






