
【导读】小样本学习是一类重要的机器学习方法,旨在解决数据缺少的情况下如何训练模型的问题。在CVPR2020的Tutorial,来自valeo.ai的学者给了Spyros Gidaris关于小样本学习的最新教程报告。

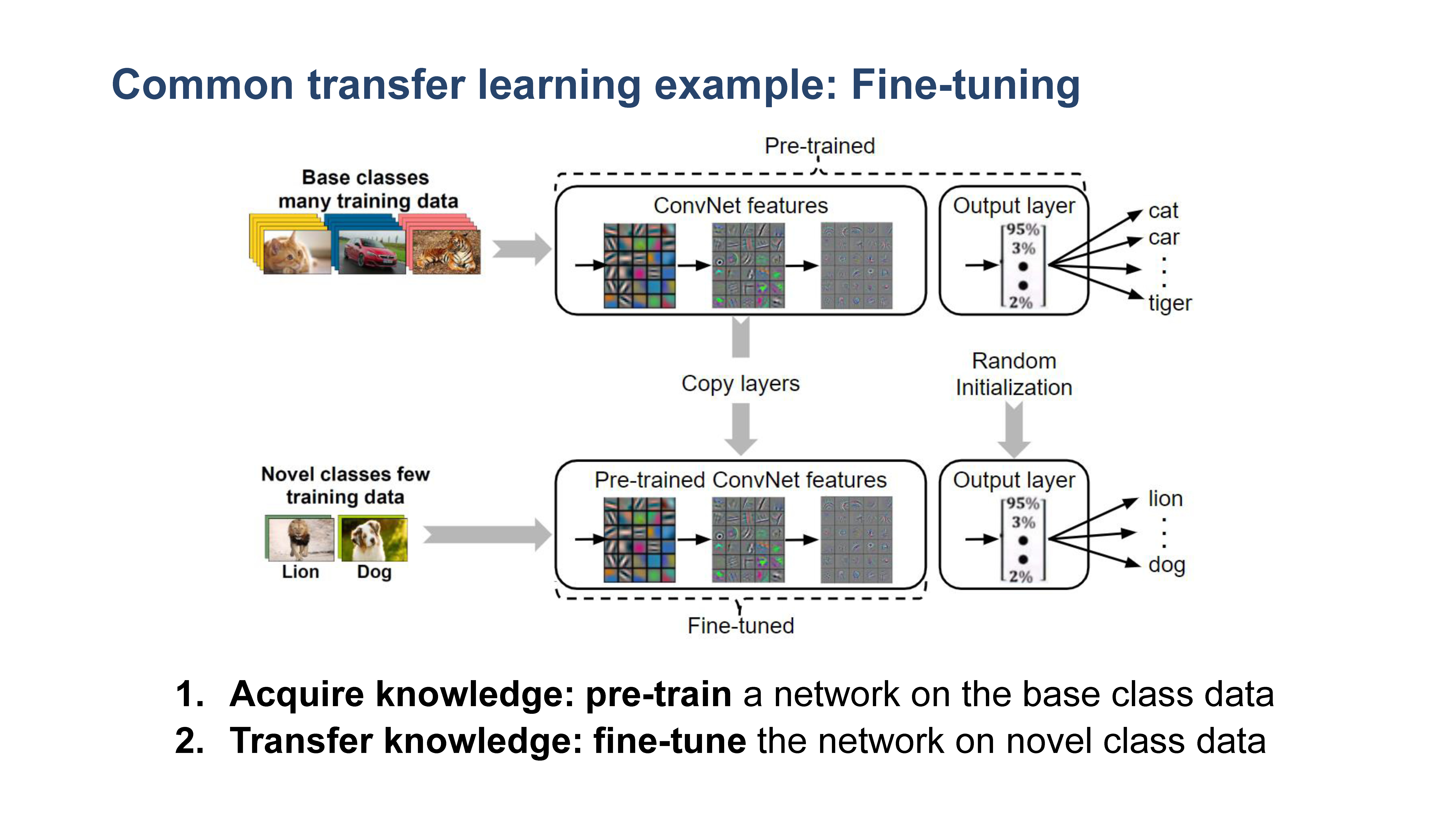
在过去的几年里,基于深度学习的方法在图像理解问题上取得了令人印象深刻的效果,如图像分类、目标检测或语义分割。然而,真实字计算机视觉应用程序通常需要模型能够(a)通过很少的注释例子学习,(b)不断适应新的数据而不忘记之前的知识。不幸的是,经典的监督深度学习方法在设计时并没有考虑到这些需求。因此,计算机视觉的下一个重大挑战是开发能够解决这方面现有方法的重要缺陷的学习方法。本教程将介绍实现这一目标的可能方法。小样本学习(FSL)利用先验知识,可以快速地泛化到只包含少量有监督信息的样本的新任务中。
https://annotation-efficient-learning.github.io/
目录内容:
- 概述
- 小样本学习种类
- 度量学习
- 带记忆模块的元学习
- 基于优化的元学习
- 学习预测模型参数
- 无遗忘小样本学习
- 结论

成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文