超越MoCo/SimCLR!华人博士提出PCL:无监督学习技术新前沿
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达


本文转载自:新智元
本文转载自:新智元
来源:einstein.ai
编辑:白峰
【导读】继MoCo和SimCLR之后无监督学习的又一里程碑!Salesforce的华人科学家(Junnan Li)介绍了一种新无监督式神经网络学习方法,这种方法能够从数百万个未标记的图像中训练深层神经网络,让我们离机器智能又进了一步。

链接:https://arxiv.org/abs/2005.04966
本文提出的原型对比学习(PCL) ,统一了无监督式学习的两个学派: 聚类学习和对比学习。PCL 推动了机器学习和人工智能的圣杯--无监督式学习技术的进步,并向无需人类指导的机器智能迈出了重要的一步。
为什么是无监督学习
深层神经网络在许多方面取得了前所未有的进展,比如图像分类和目标检测。大部分的进步都是由监督式学习 / 标签模式驱动的,得到这么好的性能很大程度上依赖于大量带有人工注释的标签(例如 ImageNet)。
然而,手工标注的成本是十分昂贵的,很难扩大规模。另一方面,互联网上存在着几乎无限量的未标记图片。非监督式学习是唯一适合开发未标记数据这个大金矿的方法。
首先,让我们来谈谈两个流行的无监督式学习算法学派: 聚类和对比学习。
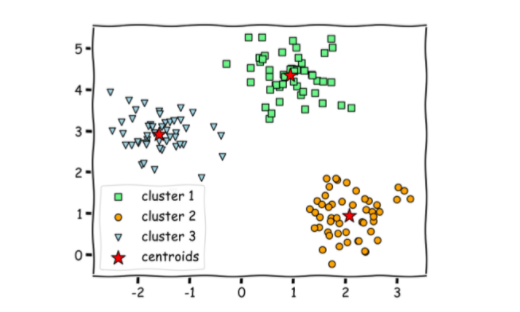
聚类:机器学习中最常见的无监督式学习任务之一。
它是将数据集划分为若干个组的过程,聚类算法将相似的数据点组合在一起,而不同的数据点组合在不同的组中。
在所有的聚类方法中,K 均值是最简单和最流行的方法之一。它是一个迭代算法,目的是将数据集划分为 k 组(聚类) ,其中每个数据点只属于一类,聚类中每个数据点和聚类质心(属于该聚类的所有数据点的算术平均值)平方距离之和最小。
对比学习: 无监督式学习的一个新兴学派
随着深层神经网络的出现,对比无监督式学习已经成为一个流行的方法学派,它训练深层神经网络而不用标签。经过训练的网络能够从图像中提取有意义的特征(表示) ,这将提高其他下游任务的性能。
对比无监督式学习主要是从数据本身学习有用的表征,所以也称为对比自我监督学习。
许多最先进的对比学习方法(例如 MoCo 和 SimCLR )都是基于实例辨别的任务。
实例鉴别训练一个网络来分类两个图像是否来自同一个源图像,如图 1(a)所示。该网络(例如 CNN 编码器)将每个图像裁剪投影到一个嵌入中,并将同源的嵌入彼此拉近,同时将不同源的嵌入分开。通过解决实例识别任务,期望网络学习到一个有用的图像表示。
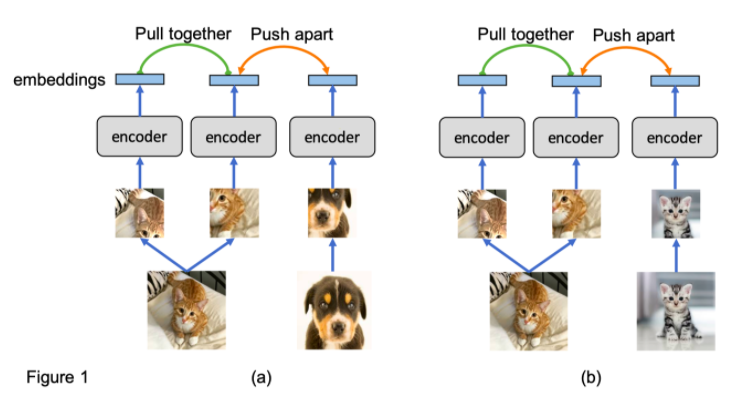
实例鉴别在无监督表征学习中表现出了良好的性能。然而,它有两个局限性。
首先,利用低层线索就可以区分不同的实例,因此网络不一定学习到有用的语义知识。
其次,如图 1(b)所示,来自同一个类(cat)的图像被视为不同的实例,它们的嵌入被推开。这是不可取的,因为具有相似语义的图像应该具有相似的嵌入。为了解决上述缺点,我们提出了一种无监督表征学习的新方法: 原型对比学习(PCL)。
原型对比学习: 统一对比学习和聚类学习
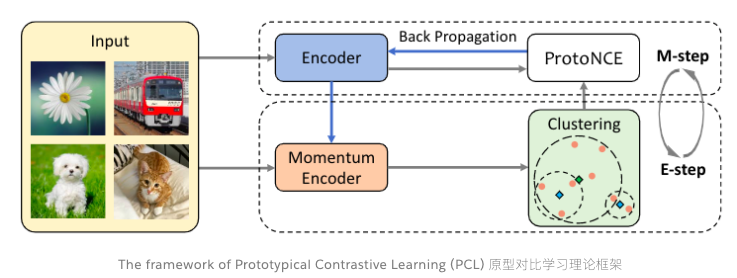
原型对比学习是无监督表征学习的一种新方法,它综合了对比学习和聚类学习的优点。
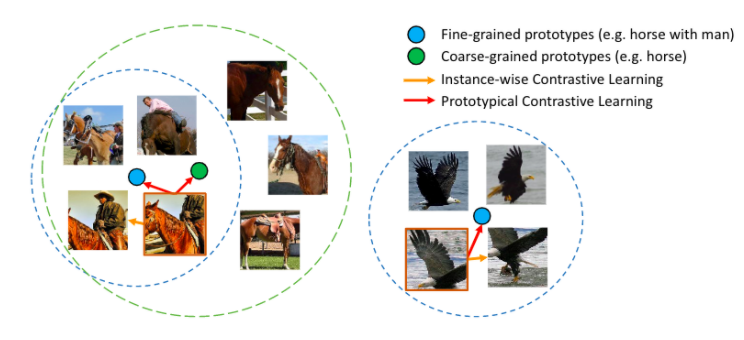
在 PCL 中,我们引入了一个「原型」作为由相似图像形成的簇的质心。我们将每个图像分配给不同粒度的多个原型。训练的目标是使每个图像嵌入更接近其相关原型,这是通过最小化一个 ProtoNCE 损失函数来实现的。
在高层次上,PCL 的目标是找到给定观测图像的最大似然估计(MLE)模型参数:
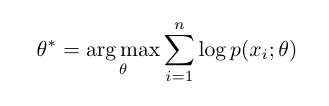
我们引入原型 c 作为与观测数据相关的潜在变量,提出了一种期望最大化算法来求解最大似然估计。在 E-step 中,我们通过执行 K 平均算法估计原型的概率。在 m 步中,我们通过训练模型来最大化似然估计,从而最小化一个 ProtoNCE 损失:
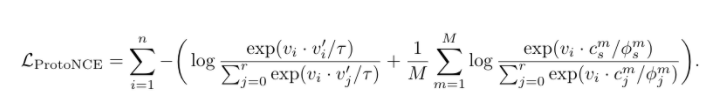
PCL 的表现如何?
我们在三个任务上对 PCL 进行评估,在所有情况下,它都达到了最先进的性能。
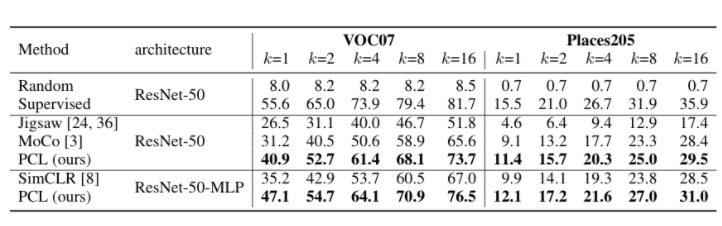
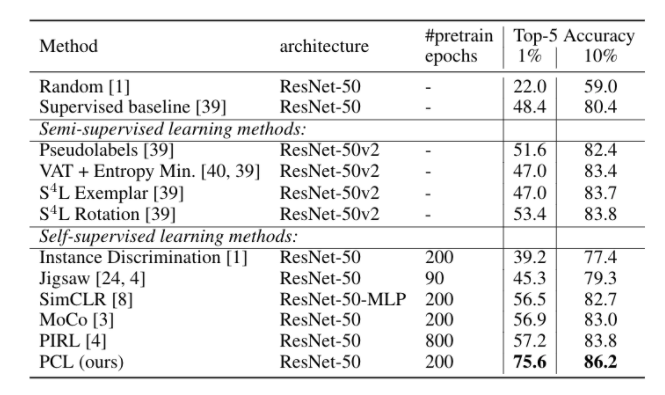
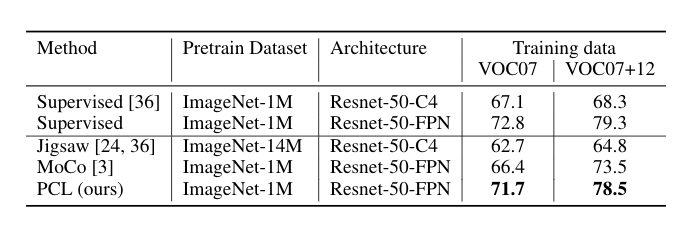
学到的表征是什么样子的?

作者简介:Junnan Li,Salesforce亚洲研究院科学家,香港大学电子工程学学士,新加坡国立大学计算机博士,主要研究方向计算机视觉和深度学习、非监督式学习,弱监督学习,迁移学习和社交场景理解。

论文下载
在CVer公众号后台回复:PCL,即可下载本论文
重磅!CVer论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1800+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI/NIPS等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!


