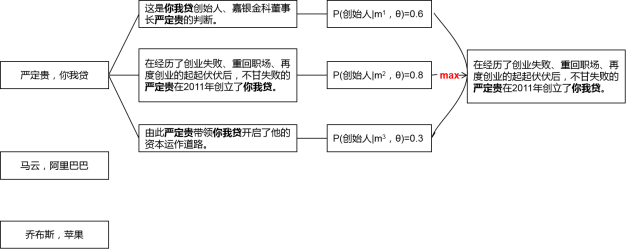
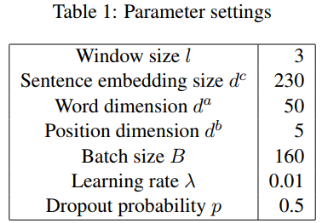
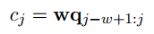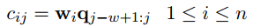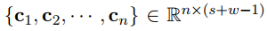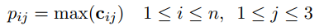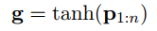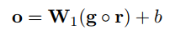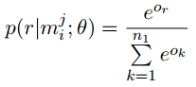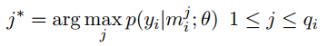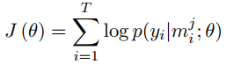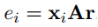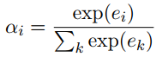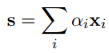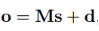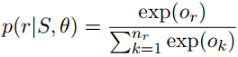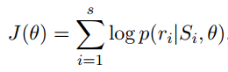第二篇论文是《Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks》,是用
神
经网络结合远程监督做关系抽取
的扛鼎之作。
(一)神经网络提取特征
用PCNNs的神经网络结构自动学习文本特征,代替复杂的人工构造特征和特征处理流程。
PCNNs(Piecewise Convolutional Neural Networks),包含两层含义:Piecewise max pooling layer 和 Convolutional Neural Networds,对应到
最大池化层和卷积层
。
用卷积神经网络强大的特征提取功能,自动抽取丰富的特征,并且减少人工设计特征和NLP工具库抽取特征带来的误差。
设计了分段最大池化层(三段,Piecewise max pooling layer)代替一般的最大池化层,提取更丰富的文本结构特征。
一般的最大池化层直接从多个特征中选出一个最重要的特征,实际上是对卷积层的输出进行降维,但问题是维度降低过快,无法获取实体对在句子中所拥有的结构信息。
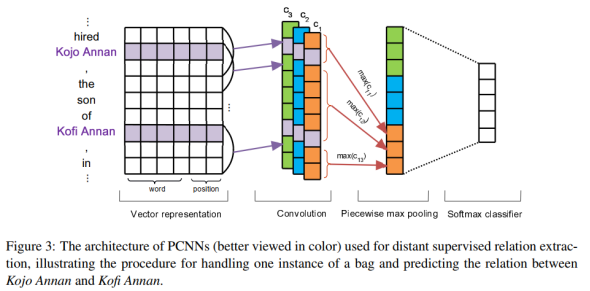
如下图,把一个句子按两个实体切分为前、中、后三部分的词语,然后将一般的最大池化层相应地划分为三段最大池化层,从而获取句子的结构信息。
![]()
用多实例学习(Multi-Instances Learning)解决远程监督做自动标注的错误标注问题。
远程监督本质上是一种自动标注样本的方法,
但是它的假设太强了,会导致错误标注样本的问题。
论文认为远程监督做关系抽取类似于多实例问题(Multi-Instances Problem)。知识图谱中一个实体对(论文中的Bag)的关系是已知的,而外部语料库中包含该实体对的多个句子(Instances of Bag),表达的关系是未知的(自动标注的结果未知真假)。
那么
多实例学习的假设是:这些句子中至少有一个句子表达了已知的关系
。于是从多个句子中只挑出最重要的一个句子,作为这个实体对的样本加入到训练中。
本篇论文设计了一个目标函数,在学习过程中,把句子关系标签的不确定性考虑进去,从而缓解错误标注的问题。
总结一下,本文的亮点在于
把多实例学习、卷积神经网络和分段最大池化结合起来,用于缓解句子的错误标注问题和人工设计特征的误差问题
,提升关系抽取的效果。
这篇论文把PCNNs的神经网络结构和多实例学习结合,完成关系抽取的任务。
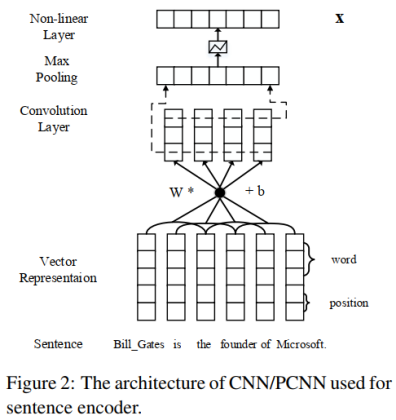
PCNNs网络结构处理一个句子的流程分为四步:
特征表示、卷积、分段最大池化和softmax分类
。具体如下图所示。
使用
词嵌入
(Word Embeddings)和
位置特征嵌入
(Position Embeddings),然后把句子中每个词的这两种特征拼接起来。
词嵌入使用的是预训练的Word2Vec词向量,用Skip-Gram模型来训练。
位置特征是某个词与两个实体的相对距离,位置特征嵌入就是把两个相对距离转化为向量,再拼接起来。
比如下面这个句子中,单词son和实体Kojo Annan的相对距离为3,和实体Kofi Annan的相对距离为-2。
假设词嵌入的维度是dw,位置特征嵌入的维度是dp,那么每个词的特征向量的维度就是:d=dw+2*dp。假设句子长度为s,那么神经网络的输入就是s×d维的矩阵。
假设卷积核的宽为w(滑动窗口),长为d(词的特征向量维度),那么卷积核的大小为W=w * d。步长为1。
输入层为q = s×d维的矩阵,卷积操作就是每滑动一次,就用卷积核W与q的w-gram做点积,得到一个数值。
卷积完成后会得到(s+w-1)个数值,也就是长度为(s+w-1)的向量c。文本的卷积和图像的卷积不同,只能沿着句子的长度方向滑动,所以得到的是一个向量而不是矩阵。
为了得到更丰富的特征,使用了n个卷积核W={W1, W2, ... Wn},第i个卷积核滑动一次得到的数值为:
把每个卷积核得到的向量ci按两个实体划分为三部分{ci1, ci2, ..., ci3},分段最大池化也就是分别取每个部分的最大值:
那么对于每个卷积核得到的向量ci,我们都能得到一个3维的向量pi。为了便于下一步输入到softmax层,把n个卷积核经过池化后的向量pi拼接成一个向量p1:n,长度为3n。
最后用tanh激活函数进行非线性处理,得到最终的输出:
把池化层得到的g输入到softmax层,计算属于每种关系的概率值。论文中使用了Dropout正则化,把池化层的输出g以r的概率随机丢弃,得到的softmax层的输出为:
输出的向量是关系的概率分布,长度为关系的种类(n1)。概率值最大的关系就是句子中的实体对被预测的关系。
我们知道一般神经网络模型的套路是,batch-size个句子经过神经网络的sotfmax层后,得到batch-size个概率分布,然后与关系标签的one-hot向量相比较,计算交叉熵损失,最后进行反向传播。
因此上述PCNNs网络结构的处理流程仅是一次正向传播的过程。
PCNNs结合多实例学习的做法则有些差别,目标函数仍然是交叉熵损失函数,但是基于实体对级别(论文中的bags)去计算损失,而不是基于句子级别(论文中的instances)。这是什么意思呢?
第一步,对于每个实体对,会有很多包含该实体对的句子(qi个),每个句子经过softmax层都可以得到一个概率分布,进而得到预测的关系标签和概率值。
为了消除错误标注样本的影响,从这些句子中
仅挑出一个概率值最大的句子和它的预测结果,作为这个实体对的预测结果,用于计算交叉熵损失
。
第二步,
如果一个batch-size有T个实体对,那么用第一步挑选出来的T个句子,计算交叉熵损失
:
如下是算法的伪代码,θ是PCNNs的参数,Eq.(9)是第一步中的公式。
知识图谱为Freebase,外部文档库为NYT。把NYT文档库中2005-2006年的句子作为训练集,2007年的句子作为测试集。
评估方法沿用第一篇论文中的方法,留出法和人工校验相结合。
预训练的词向量方面,本文用Skip-Gram模型和NYT文档库训练了50维的词向量。
调参方面,PCNNs网络结构中有两个参数比较重要:
卷积核的滑动窗口大小和卷积核的个数。
本文使用网格搜索,最终确定滑动窗口为3,卷积核个数为230。
使用留出法和人工校验法来评估模型的效果。这里对这两种评估方法进行补充说明:
留出法的做法是把Freebase中一半的实体对用于训练,一半的实体对用于测试。
多分类模型训练好之后,对外部文档库NYT中的测试集进行预测,得到测试集中实体对的关系标签。
如果新发现的实体对有N个,其中有n个出现在Freebase的测试集中,那么查准率(Precision)为n/N,而不在Freebase测试集中的实体对就视为不存在关系。
可是由于Freebase中的实体对太少了,新发现的、不在Freebase里的实体对并非真的不存在关系,这就会出现假负例(False Negatives)的问题,
低估了查准率
。
所以人工校验的方法是对留出法的一个补充,对于那些
新发现的、不在Freebase测试集中的实体对
(一个实体不在或者两个实体都不在)进行检查,计算查准率。
所以留出法和人工校验要评估的两个新实体对集合是没有交集的。具体做法是从这些新实体对中选择概率值最高的前N个,然后人工检查其中关系标签正确的实体对,如果有n个,那么查准率为n/N。
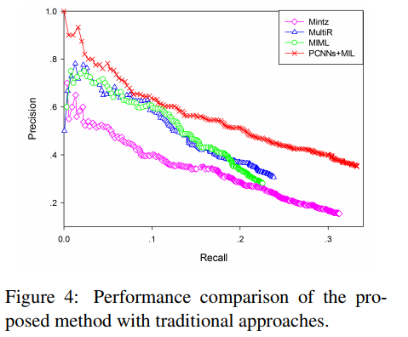
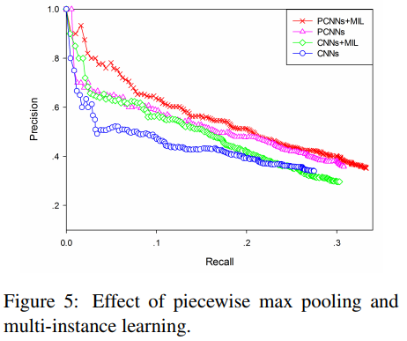
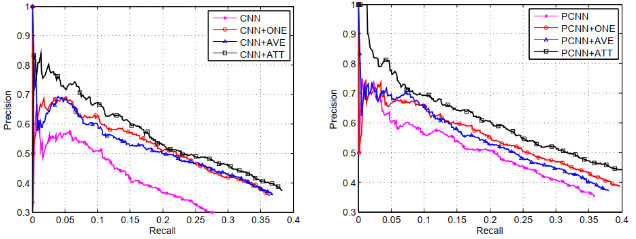
首先把PCNNs结合多实例学习的远程监督模型(记为PCNNs+MIL),与人工构造特征的远程监督算法(记为Mintz)和多实例学习的算法(记为MultiR和MIML)进行比较。
从下面的实验结果中可以看到,无论是查准率还是查全率,PCNNs+MIL模型都显著优于其他模型,这说明用卷积神经网络作为自动特征抽取器,可以有效降低人工构造特征和NLP工具提取特征带来的误差。
将分段最大池化和普通的最大池化的效果进行对比(PCNNs VS CNNs),将结合多实例学习的卷积网络与单纯的卷积网络进行对比(PCNNs+MIL VS PCNNs)。
可以看到,分段最大池化比普通的最大池化效果更好,表明分段最大池化可以抽取更丰富的结构特征。
把多实例学习加入到卷积网络中,效果也有一定的提升,表明多实例学习可以缓解样本标注错误的问题。
这篇论文中,分段最大池化的奇思妙想来自于传统人工构造特征的思想,而
多实例学习的引入缓解了第一篇论文中的样本错误标注问题
。这篇论文出来以后是当时的SOTA。
不足之处在于,多实例学习仅从包含某个实体对的多个句子中,挑出一个最可能的句子来训练,这必然会损失大量的信息。
所以有学者提出用句子级别的注意力机制来解决这个问题。
第三篇论文是《Neural Relation Extraction with Selective Attention over Instances》,这篇论文首次把注意力机制引入到了关系抽取的远程监督算法中,刷新了当时的SOTA。论文作者中有清华刘知远老师。
这篇论文要解决的问题,就是
多实例学习会遗漏大量信息的问题
。
所以这篇论文用句子级别的注意力机制代替多实例学习,对于包含某实体对的所有句子,
给每一个句子计算一个注意力得分,动态地降低标注错误的样本的得分
,再进行加权求和,从而充分利用所有句子的信息。
多实例学习相当于硬注意力机制(Hard Attention),而我们耳熟能详的以及论文中用到的注意力机制是选择性注意力机制(Selective Attention)或者说软注意力机制(Soft Attention)。
所以
多实例学习其实是选择性注意力机制的特殊情况
(只有一个句子的权重为1,其他全为0)。
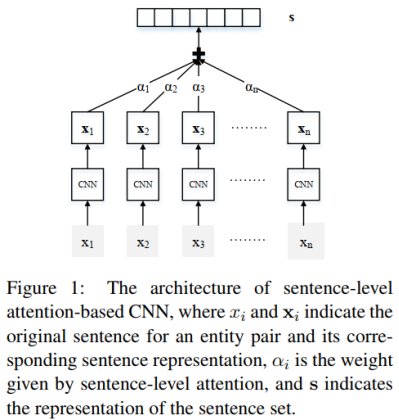
句子编码器就是上一篇论文中的PCNN或CNN网络结构,由卷积神经网络的输入层、卷积层、池化层、非线性映射层(或者说激活函数)构成。
文本特征同样用
词嵌入和位置特征嵌入
,池化层用
普通的最大池化或者分段最大池化。
因此,本文的句子编码器部分输出的是一个句子经过最大池化并且非线性激活后的特征向量,用于输入到注意力层。这部分和上一篇论文基本相同,无须赘述。
句子编码器的作用是抽取一个句子的特征,得到一个特征向量。
如果外部文档库中包含某实体对的句子有n条,那么经过句子编码器的处理后,可以得到n个特征向量:x
1
, x
2
, ..., x
n
。
在句子编码器和softmax层之间加一个选择性注意力层
,那么处理的步骤如下:
第一步:计算句子的特征向量x
i
和关系标签r的匹配度e
i
,并计算注意力得分α
i
。公式中的r是关系标签的向量表示。
第二步:计算该实体对的特征向量s。该实体对的特征向量是所有句子的特征向量xi的加权之和,权重为每个句子的注意力得分αi。
第三步:经过softmax层得到该实体对关于所有关系的概率分布,概率值最大的关系为预测的关系标签。
如果一个batch-size有s个实体对,那么用s个实体对的概率分布,计算交叉熵损失:
(1)数据集和评估方法
数据集和上一篇论文一样,知识图谱是Freebase,外部的文档库是NYT(New York Times corpus)。划分数据集的做法也一致。评估方法采用留出法,不再赘述。
用NYT数据集训练Word2Vec,用网格搜索(Grid Search)确定参数。
句子编码器分别采用CNN和PCNN的网络结构,PCNN+ONE表示PCNN结合多实例学习的模型,PCNN+ATT表示论文中的选择性注意力模型,PCNN+AVE表示对各句子求算术平均的模型(每个句子的注意力得分相同)。
实验结果表明,无论是CNN还是PCNN,加入注意力机制的模型在查准率和查全率上,都显著优于其他模型。
论文还有其他更细致的实验,欲知详情,请自行翻看论文。
这篇论文把注意力机制和CNN句子编码器结合,用来解决多实例学习存在的遗漏信息问题,更好地缓解了远程监督算法中的样本错误标注问题。
注意力机制在NLP任务中的效果是有目共睹的,PCNN+ATT的模型看起来非常漂亮,那么有什么改进方向呢?
开头我们说了,
关系抽取可以分为流水线式抽取(Pipline)和联合抽取(Joint Extraction)两种
,流水线式抽取就是把关系抽取的任务分为两个步骤:首先做实体识别,再抽取出两个实体的关系;而联合抽取的方式就是一步到位,同时抽取出实体和关系。
因此上面介绍的三篇论文中的模型都属于流水线式抽取的方法,实体识别和关系抽取的模型是分开的,那么
实体识别中的误差会影响到关系抽取的效果
。
而联合抽取用一个模型直接做到了实体识别和关系抽取,是一个值得研究的方向。
参考资料:
1、《Speech and Language Processing》(Third Edition draft)第17章
2、《cs224u: Relation extraction with distant supervision》
3、《Distant supervision for relation extraction without labeled data》
4、《Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks》
5、《Neural Relation Extraction with Selective Attention over Instances》
6、《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》