摘要
本文综述了迁移学习在强化学习问题设置中的应用。RL已经成为序列决策问题的关键的解决方案。随着RL在各个领域的快速发展。包括机器人技术和游戏,迁移学习是通过利用和迁移外部专业知识来促进学习过程来帮助RL的一项重要技术。在这篇综述中,我们回顾了在RL领域中迁移学习的中心问题,提供了一个最先进技术的系统分类。我们分析他们的目标,方法,应用,以及在RL框架下这些迁移学习技术将是可接近的。本文从RL的角度探讨了迁移学习与其他相关话题的关系,并探讨了RL迁移学习的潜在挑战和未来发展方向。
关键词:迁移学习,强化学习,综述,机器学习
介绍
强化学习(RL)被认为是解决连续决策任务的一种有效方法,在这种方法中,学习主体通过与环境相互作用,通过[1]来提高其性能。源于控制论并在计算机科学领域蓬勃发展的RL已被广泛应用于学术界和工业界,以解决以前难以解决的任务。此外,随着深度学习的快速发展,应用深度学习服务于学习任务的集成框架在近年来得到了广泛的研究和发展。DL和RL的组合结构称为深度强化学习[2](Deep Reinforcement Learning, DRL)。
DRL在机器人控制[3]、[4]、玩[5]游戏等领域取得了巨大的成功。在医疗保健系统[6]、电网[7]、智能交通系统[8]、[9]等领域也具有广阔的应用前景。
在这些快速发展的同时,DRL也面临着挑战。在许多强化学习应用中,环境模型通常是未知的,只有收集到足够的交互经验,agent才能利用其对环境的知识来改进其性能。由于环境反馈的部分可观察性、稀疏性或延迟性以及高维观察和/或行动空间等问题,学习主体在没有利用任何先验知识的情况下寻找好的策略是非常耗时的。因此,迁移学习作为一种利用外部专业知识来加速学习过程的技术,在强化学习中成为一个重要的课题。
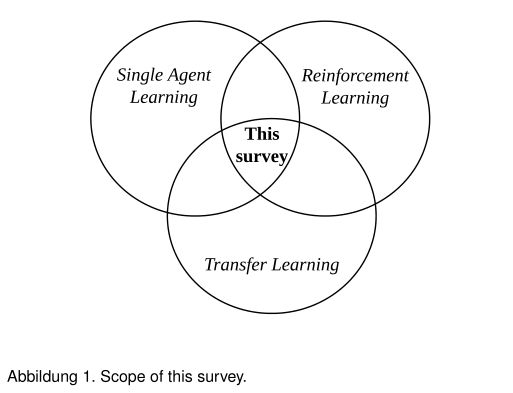
在监督学习(SL)领域[10]中,TL得到了广泛的研究。与SL场景相比,由于MDP环境中涉及的组件更多,RL中的TL(尤其是DRL中的TL)通常更复杂。MDP的组件(知识来自何处)可能与知识转移到何处不同。此外,专家知识也可以采取不同的形式,以不同的方式转移,特别是在深度神经网络的帮助下。随着DRL的快速发展,以前总结用于RL的TL方法的努力没有包括DRL的最新发展。注意到所有这些不同的角度和可能性,我们全面总结了在深度强化学习(TL in DRL)领域迁移学习的最新进展。我们将把它们分成不同的子主题,回顾每个主题的理论和应用,并找出它们之间的联系。
本综述的其余部分组织如下:在第2节中,我们介绍了强化学习的背景,关键的DRL算法,并带来了这篇综述中使用的重要术语。我们还简要介绍了与TL不同但又紧密相关的相关研究领域(第2.3节)。
在第3节中,我们采用多种视角来评价TL方法,提供了对这些方法进行分类的不同方法(第3.1节),讨论了迁移源和目标之间的潜在差异(第3.2节),并总结了评价TL有效性的常用指标(第3.3节)。
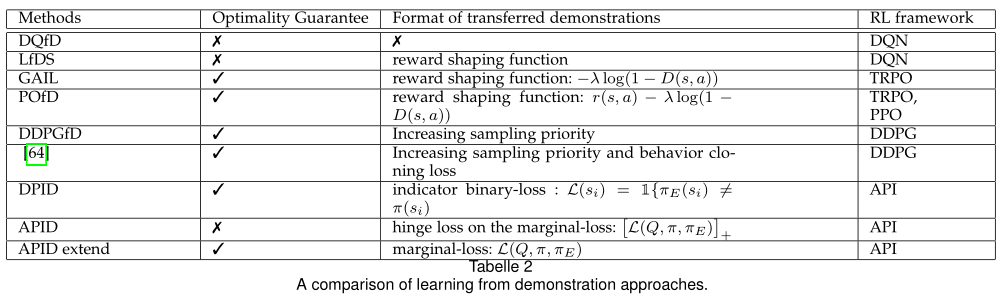
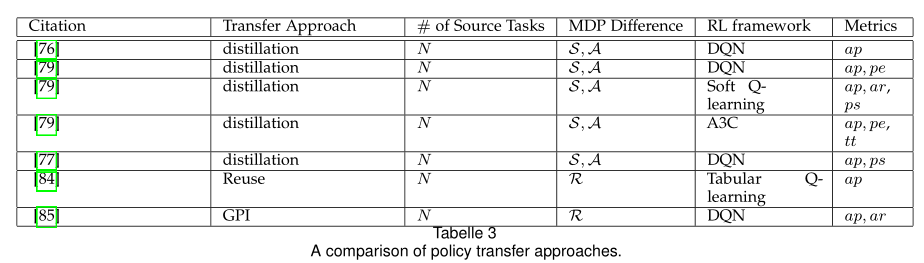
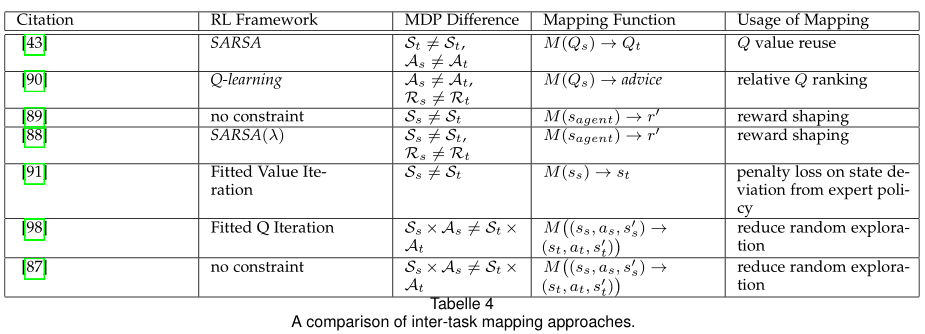
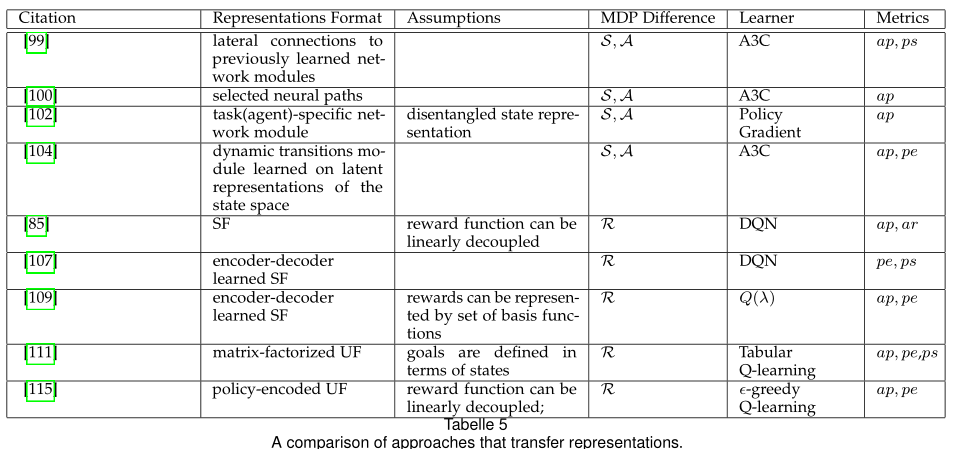
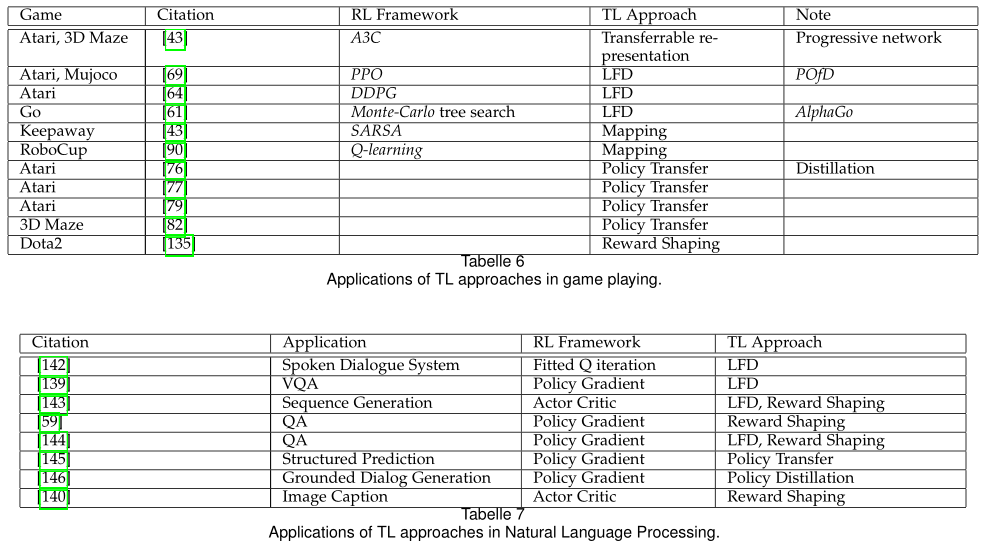
第4节详细说明了DRL领域中最新的TL方法。特别是,所讨论的内容主要是按照迁移知识的形式组织的,如成型的奖励(4.1节)、先前的演示(4.2节)、专家策略(4.3节),或者按照转移发生的方式组织的,如任务间映射(4.4节)、学习可转移表示(4.5节和4.6节)等。我们在第5节讨论了TL在DRL中的应用,并在第6节提供了一些值得研究的未来展望。