学界 | 伯克利、OpenAI等提出基于模型的元策略优化强化学习
选自arXiv
机器之心编译
参与:乾树、王淑婷
基于模型的强化学习方法数据效率高,前景可观。本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能。
引言
强化学习领域近期取得的很多成就都是通过无模型强化学习算法 [1,2,3] 实现的。无模型(MF)算法倾向于实现最佳性能,通常可应用且易于实现。
然而,这是以数据密集为代价实现的,当与诸如神经网络的大容量函数近似器结合时,情况会恶化。它们的高样本复杂性阻碍其应用于机器人控制任务,在这些任务上收集数据代价高昂。
相比之下,基于模型的(MB)强化学习方法可以通过明显更少的样本来学习。这类学习方法使用习得的环境动态模型,而此模型能够执行策略优化。学习动态模型能以样本高效的方式完成,因为它们是用标准的监督学习技术训练而成,允许使用非策略数据。
然而,精确的动态模型往往比良好的策略复杂得多。例如,将水倒入杯中可以通过相当简单的策略来实现,但是对该任务的潜在动态进行建模是非常复杂的。
因此,基于模型的方法只能在更有限的一系列问题上学习良好的策略,即使学习了良好的政策,它们的表现通常也会远低于无模型的方法 [4,5]。
基于模型的方法倾向于依靠准确(学习到的)的动态模型来解决任务。如果动态模型不够精确,则策略优化容易过度拟合模型的缺陷,导致次优行为甚至是灾难性故障。
该问题在文献中被称为模型偏差 [6]。以前的研究试图通过表征模型的不确定性和学习鲁棒的策略来减轻模型偏差 [6,7,8,9,10],通常使用集合来表示后验。本文也使用集合,但却截然不同。
本文提出基于模型的元策略优化(MB-MPO),这是以前基于模型的 RL 方法的正交版本:传统的基于模型的 RL 方法要求学习到的动态模型足够准确,以便学习在现实世界中也能取得成功的策略,但是本文提出的方法放弃了对这种准确性的依赖。它通过学习动态模型集合并将策略优化步骤构建为元学习问题来实现同样的目标。
在 RL 中,元学习旨在学习一种能够快速适应新任务或环境的策略 [11,12,13,14,15]。使用模型作为学习模拟器,MB-MPO 学习的策略可以通过一个梯度步快速地适应任何合适的动态模型。该优化目标引导元策略在集合中实现内部一致的动态预测,同时将模型间最佳行为的负担转移到适应步骤。
这样下来,学习到策略表现出较少的模型偏差,因此不必保守行事。尽管在如何收集轨迹样本和训练动态模型方面与先前的 MB 方法有很多相同之处,但是用于策略优化(和依赖)的学习到的动态模型从根本上是不同的。
在本文中,研究者展示了 1)基于模型的策略优化可以学习与无模型方法中渐近性能相匹配的策略,同时显著提高采样效率,2)MB-MPO 在较难的控制任务方面始终优于以前基于模型的方法,3)当模型存在很大的偏差时,仍然可以学习。
本文方法的低样本复杂性使其适用于真实世界的机器人。例如,它能够在两小时内基于真实数据, 找到高维且复杂的四维运动世界的最优策略。请注意,使用无模型方法学习此类策略所需的数据量要高出 10 倍- 100 倍,并且研究者所知,之前的基于模型的方法在此类任务中无法获得与无模型相近的性能。
论文:Model-Based Reinforcement Learning via Meta-Policy Optimization

论文地址:https://arxiv.org/abs/1809.05214
基于模型的强化学习方法数据效率高,前景可观。然而,由于学习动态模型的挑战在于完全匹配现实世界的动态,研究者们努力实现与无模型方法相同的渐近性能。他们提出了基于模型的元策略优化(MB-MPO),这种方法放弃了对精准可学习动态模型的强烈依赖。
使用可学习动态模型集合,MB-MPO 元学习学会了通过策略梯度步快速适应集合中任何模型的策略。这驱使元策略在模型集合中实现内部一致的动态预测,同时将模型间最佳行为的负担转移到适应步骤。
实验表明,MB-MPO 比以前基于模型的方法更能够应对模型缺陷。最后,我们证明了本文的方法能够取得与无模型方法相近的性能,同时需要的经验更少。
实验
我们实验评估的目的是测试以下问题:1)MBMPO 如何与最先进的无模型和基于模型的方法对比样本复杂性和渐近性能?2)模型的不确定性如何影响策略的可塑性?3)我们的方法对不完美模型有多鲁棒?
为了回答以上问题,我们在 Mujoco 模拟器中针对六个连续控制基准任务评估了该方法 [44]。附录 A.3 中给出了环境配置以及实验设置的详细描述。
在接下来的所有实验中,更新前策略用于报告使用该方法获得的平均奖励。报告的性能至少是三个随机种子的平均值。源代码和实验数据可在我们的补充网站上找到。

图 8:实验中使用的 Mujoco 环境。从左到右:游泳的人,猎豹,2D 行人,PR 2,跳虫,蚂蚁。
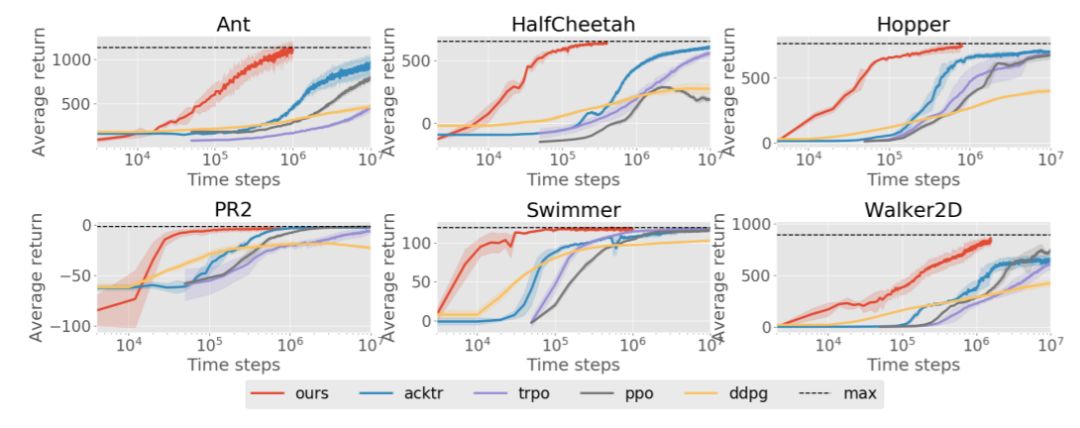
图 1:MB-MPO(「我们的」)的学习曲线和六种不同的 Mujoco 环境中四种最先进的无模型方法,基准为 200 时间步。MB-MPO 能够在降低两个数量级的样本上达到无模型方法的渐近性能。
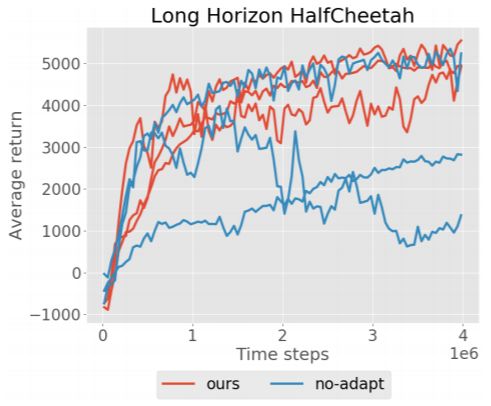
图 5:该方法有无模型改动的比较。描述了在猎豹环境中使用三个不同的随机种子进行训练期间平均回报的变化,其中基准为 1000 个时间步长。
算法
在下文中,我们描述了该方法的整体算法(参见算法 1)。首先,我们使用不同的随机权重初始化模型和策略。然后,继续收集数据。在第一次迭代中,使用随机控制器收集来自现实世界的数据,并存储在缓冲器 D 中。
在随后的迭代中,利用适应的策略 {πθ01,...,πθ0K} 收集来自现实世界的轨迹,然后与来自先前迭代的轨迹聚合。根据 4.1 节中阐述的步骤,使用聚合的实际环境样本对模型进行训练。
该算法通过使用策略 πθ 从每个模型集合 {fφ1,...,fφK} 自动生成轨迹来进行。这些轨迹用于执行内部适应策略梯度步,产生适应的策略 {πθ01,...,πθ0K}。最后,研究者使用适应的策略 πθ0k 和模型 fφk 生成虚拟轨迹,并优化元目标的策略(如 4.2 节中所述)。重复这些步骤,直到达到预期的性能。该算法返回优化的更新前参数 θ。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

