NLPCC:预训练在小米的推理优化落地


分享嘉宾:赵群 小米
整理编辑:陈锦龙
内容来源:DataFunTalk
导读:本文主要分享小米AI实验室NLP团队在NLPCC轻量级语言模型比赛上的经验,以及我们在预训练模型推理优化上所作的工作和达到的实际落地后的效果。此次分享的目的是帮助大家快速进入比赛,以及了解工业界中使用BERT之类的大型预训练模型时进行推理的相关优化手段。
首先和大家说一下比赛的背景和预训练模型中存在的问题。
1. NLP中的预训练
随着BERT的推出和发展,预训练模型成为目前工业界和比赛使用最广泛的模型。目前在各大NLP任务SOTA榜单上排前几名都是大型的预训练模型,比如原生BERT或者它的一些变体。
预训练模型的应用分为两个阶段,先进行预训练阶段 ( pre-training ),然后进行微调阶段 ( fine-tuning )。预训练阶段利用大规模的无监督预料,通常大于100g的量级,加上特定的无监督任务进行训练。用来预训练的任务有,经典的NSP ( next sentence predict )、MLM ( masked language model )、以及一些变体,如阿里发布的Structural language model。另外在预训练阶段时,embedding层的使用方式也有很多,比如NEZHA以及XLNET使用的相对位置编码。Pretrain阶段一般比较消耗计算资源,一般都是在大量的GPU集群上进行运算,并且计算很长的时间才能得到一个比较好的结果。
相对于复杂预训练任务,下游的微调任务就比较简单了。在预训练好的模型的基础上,只需要添加较少的网络参数,并在在下游有监督数据上进行少量的训练,就可以得到很不错的成果,这也是预训练技术能够被大量使用的基础条件。
2. 效率问题
然而就像天下没有免费的午餐一样,预训练技术在带来好处的同时也存在一些问题,这其中最为凸显的恐怕是效率问题了。
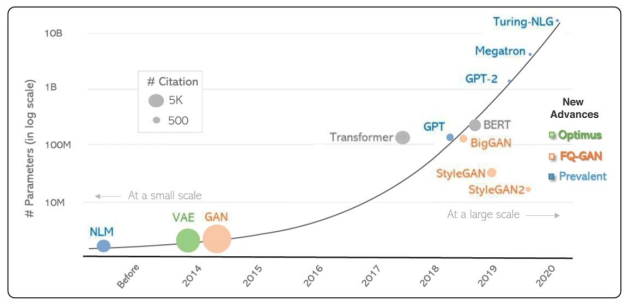
微软在发布TuringNLG模型的同时发布了这种图,从上图我们可以看到在BERT发布到现在,自然语言模型参数量的发展是指数型增大的,从BERT的1亿参数量、到GPT2的10亿、然后TuringNLG的100亿。模型变大带来的效率问题可以从训练和推理两个方面来体现。
在训练阶段,一个好的模型需要大量的语料支持,通常为了得到一个不错的模型,需要使用100g以上的训练数据。同时为了支持如此规模的数据集,使模型能拟合出不错的效果,就需要使用大量昂贵的GPU资源。而在推理阶段,大模型的推理时间比较长,那如何在高并发业务线上使用大模型,并且保证推理服务的性能 ( 比如服务延迟99分位数 ) 成为一个难题。由此可见,在预训练模型应用时必须考虑性价比,在效果提升和成本预算之间做一个合适的权衡。
3. 解决方向
针对这些效率上的问题,衍生出两个比较清晰的解决方向和思路。
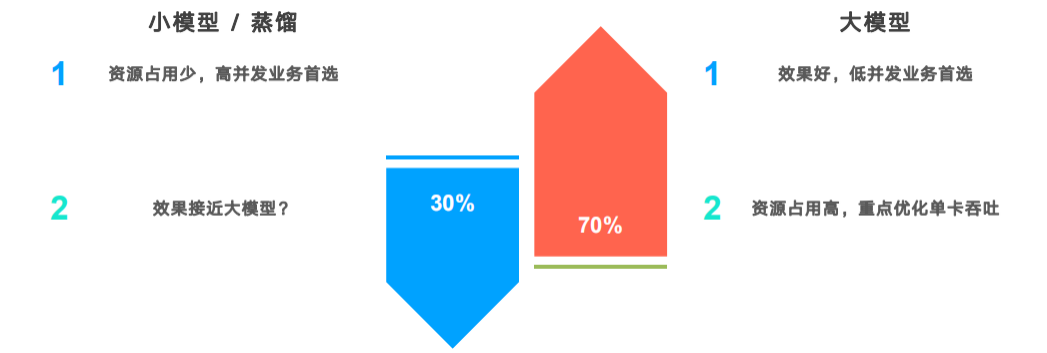
第一种方法是小模型或蒸馏,小模型是指参数特别少的模型,比如在NLPCC小模型比赛中聚焦的小于12M参数的模型。蒸馏是将训练好的BERT类大模型的能力迁移到较小的模型中,目前业界聚焦的任务是将12层的BERT-base模型蒸馏到6层的BERT上,并保证较少的性能损失。这种方法的主要优势是资源占用率比较少,适用于线上的高并发业务;并且通过一些方法能够实现与大模型类似的效果。
第二种方法是对大模型的优化,具体来说是指优化大模型在单张GPU上所能承受的最大流量,即吞吐量。这种方法的优势是效果较好,比较适合低并发业务。
1. 比赛介绍
比赛要求的小模型必须是小于12M参数的预训练模型,即1/9的BERT-base大小,最后在四个下游任务中测试模型效果并进行打分。评测涉及任务有:指代消歧 ( CLUEWSC2020 )、分类任务 ( CSL论文关键词识别 )、命名实体识别 ( CLUENER2020 ) 以及阅读理解 ( CMRC 2018 )。其中,指代消歧任务用的是小数据集 ( 1.2k左右 ),其余任务所用数据集大小为万级别。在小数据集上微调模型,尤其是小预训练模型,是比较影响模型效果的,后面我们会介绍这方面所做工作,希望能够对读者有所帮助。

用一句话来总结这个比赛,小模型的效果真的很差吗?我们直接来看比赛的结果。

其中,第一条我们提交的BERT-base的参考。可以看到相较于BERT模型,小模型在分类、NER以及阅读理解任务上都可以将差距缩小到1.5%以内。而在wsc任务上由于数据集太小,导致微调时效果的抖动非常大效果会略差一点,而实际中很少有这么小的数据集。
2. 经验分享
接下来主要介绍一下我们的解决方案。在直接预训练小模型和蒸馏的方式选择上,我们采用了前者。

我们在比赛中所做的工作主要分为了3个方面,首先是数据。我们一共收集了160g的原始中文语料,并剔除了一些口语、表情、微博段子、网络流行用语比较多的语料,最终筛选出35g+相对通用的语料。为了快速得到实验结果,我们在输入长度上采用了256的大小,同时也正在尝试512的长度,以便在阅读理解等需要更长的句子输入的任务上得到更好一点的效果。
在模型方面,我们选用了6层的高瘦模型,并通过以下公式选择对应的Hidden size和Vocab size来保证模型参数总量小于12M。

大概介绍一下训练细节,我们使用了8张V100卡;采用了混合精度的方法;优化器为lamb优化器;batch size大概为14400,并每过十几步累积一次梯度;预训练任务选用了wwm-MLM。没有选用NSP任务的原因是,我们在测试MLM + NSP任务训练时出现了收敛较慢的现象,原因仍有待分析。最终训练结果是MLM loss达到了1.5 ~ 1.8之间,同时我们发现当loss到1.8左右时,分类任务和NER任务对应的表现已经很好了;继续训练当loss来到1.5附近时,阅读理解任务的效果提升较大,而分类任务和NER任务的表现开始有一些抖动。
遇到的问题:
同时我们分享两个在比赛过程中遇到的问题。
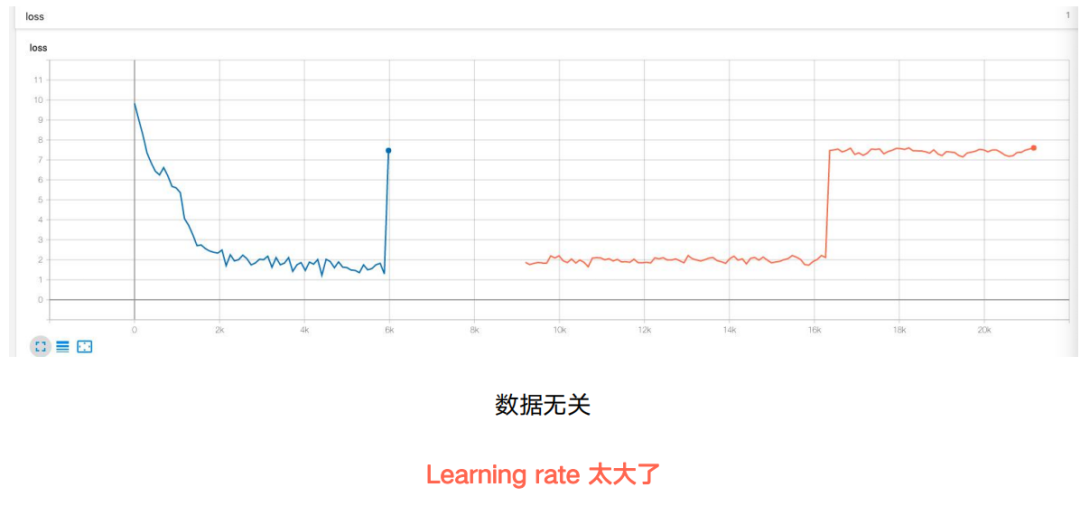
第一个是模型训练时的梯度爆炸,具体是每当loss收敛到1.5附近时就会出现梯度爆炸的问题。再排除了数据中的问题后,最终我们找到的解决方法是将初始的学习率调小,之后再没有遇到同样的问题。
第二个问题是,我们再尝试微软发布的Bert of theseus蒸馏方式时,发现该方法在本次小模型比赛中取得的效果不好,原因是使用该方法时Hidden Size不能改变,因此必须压缩层数来达到参数量的限制。同时,我们尝试用小的Hidden Size预训练一个模型,再去蒸馏一个12M的模型。可能是受限于Teacher模型的效果限制,得到的结果是不好的。
3. 后续尝试
同时,在比赛快结束的时候我们总结性的提出一些后续可以继续尝试的思路。
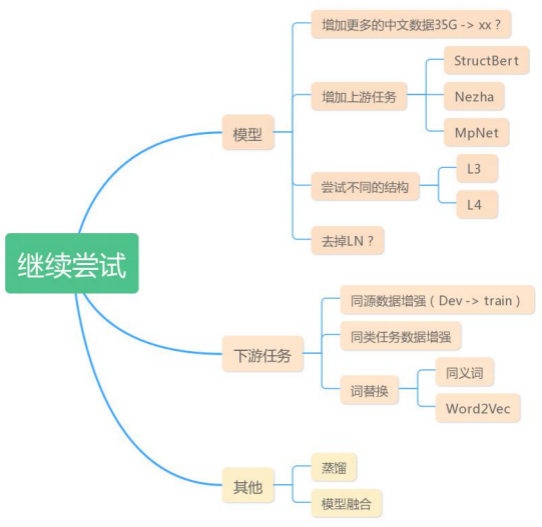
注:NLPCC比赛结束后,我们又尝试了一个数据增强和简单的蒸馏方法,目前在WSC和CLUENER两个任务上已经超过了bert-base的效果,并且排在了小模型排行榜第一名,详见如下:

以上就是这次NLPCC小模型比赛的经验分享,下面将分享一下大模型推理服务的优化以及在小米的落地情况。
1. 相关知识和现状
为了方便大家阅读,我们先介绍两个工程上评价服务的指标。

为什么要介绍这两个指标,是因为线上服务要在短时间内接受大量的请求,为了满足使用者的体验以及维护公司利益,必须要保证较高的可用性。

我们再来看一下在用大模型推理时,用一张T4卡能达到的最大QPS。如果模型用的是BERT base,句子计算长度设定为16,那么最大的QPS大概是100,这时P99已经比较高了,如果QPS设定为150服务将变得不可用;同时,如果模型是BERT-large,在同样的句子长度下,模型根本无法运行。在这种情况下假设有一个日活1000w+的服务要上线,QPS对应要求为2000,并使用BERT-base作计算推理。那么我们计算了一下,一共需要20张T4卡来满足需求,并且P99延迟会大于90ms,这是一个非常大的资源浪费。
2. 优化效果
开门见山的说,在优化后同样一张T4卡上可以达到什么样的效果呢?大家可以看下表中QPS和对应的P99表现,当QPS最大达到3000时,P99的延迟仍然保持在40ms以下。
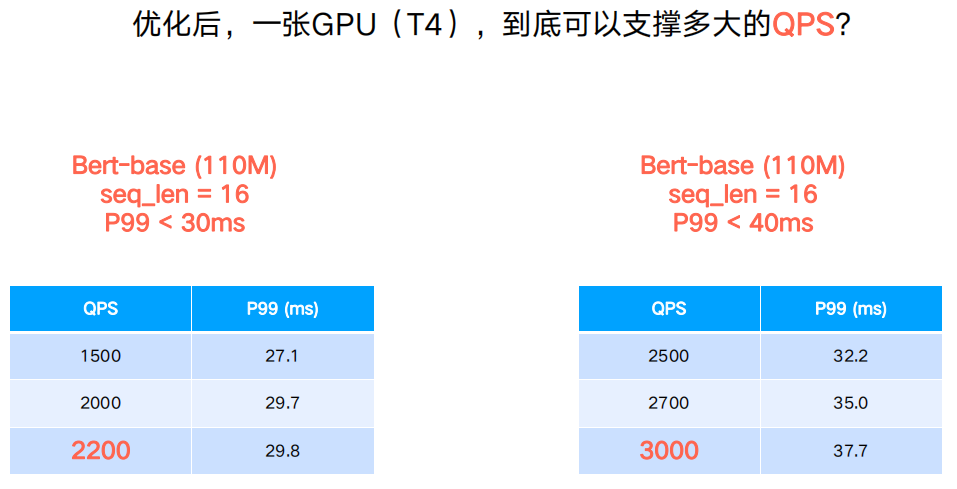
如果大家为了追求更好的效果使用BERT-large模型,使用相同的推理优化方法能够达到的数据如下表,极限QPS大概是800左右。

总结一下优化效果,优化前如果BERT-base模型要放在线上推理,需要使用20张T4来满足需求。优化后可以将数量缩减到1张,一共节约了19倍的成本。
3. 实现方案
下面来介绍一下我们的优化方案。
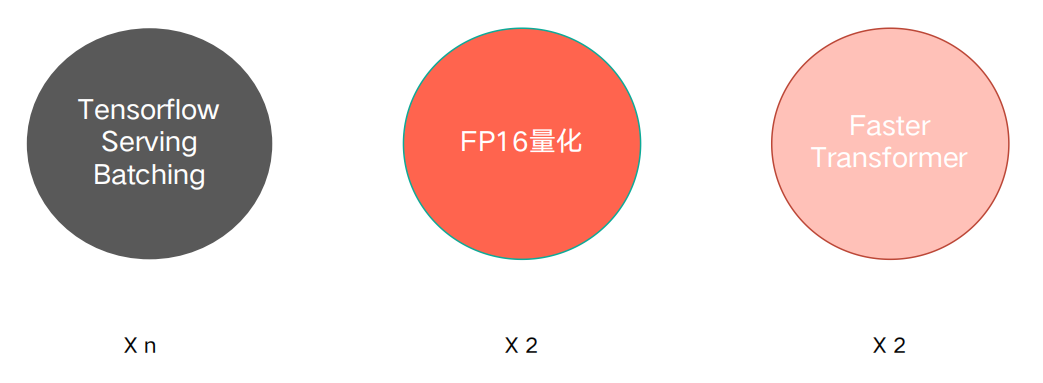
简单来说分为三个:
第一个是Tensorflow Serving提供的Batching功能,该方法能够提升n倍的服务性能;
第二个是FP16的量化,可以提升2倍服务性能;
第三个是NVIDIA开源的Faster Transformer库。
Tensorflow Serving Batching所做的是将多个请求合并在一起进行计算,这样可以利用GPU的并行性能。之所以能这样做是因为GPU在计算一定量的batch所消耗的时间和计算单挑所用时间相差不多。具体的原理是服务端在规定好的一段时间里持续接收请求并放入队列等待,如果请求数达到规定的数量或者队列等待时间超过规定时间,再进行推理运算。另外一个经验是在使用TF-Serving Batching时,服务端做Padding会用随机数填充,所以建议大家在Client端做Padding。

在用FP16优化中,我们使用了TensorCore来做加速,将模型图中FP32精度的节点全部转换为FP16,从而降低模型推理需要计算的运算量 ( 每秒浮点运算次数TFLOPs )。在BERT-base上实验,这种方法很稳定,损失基本上控制在万分位,是一个非常值得使用的方法。

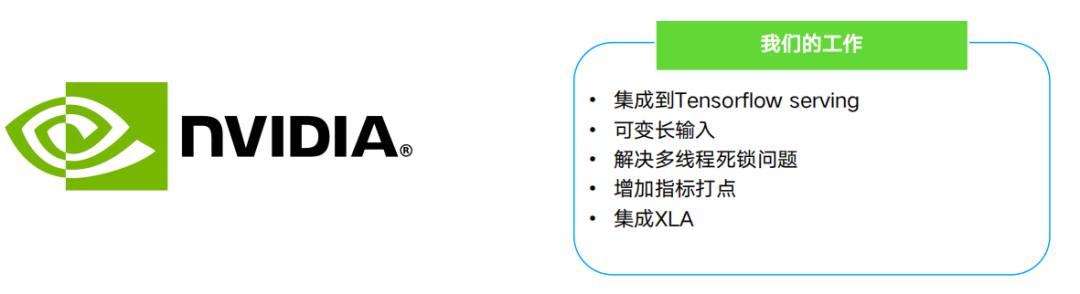
第三个方法是用Fast Transformer,大家感兴趣可以去github了解源码。我们在这基础上所做的工作是,将Fast Transformer集成到Tensorflow Serving上,并且支持对可变长度输入的处理等等。大家可以访问英伟达的github主页了解更多。
4. 线上效果
前面在评测这些优化方法时用到的数据都是压测数据,那么在真实线上业务的表现怎么样呢,我们用小爱同学的闲聊业务来举例说明。
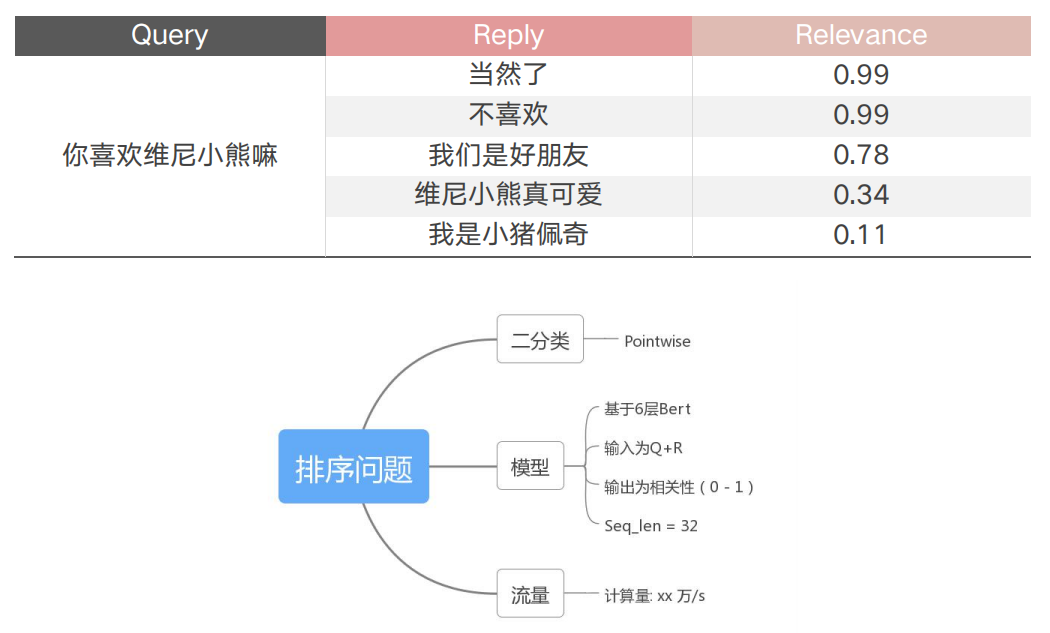
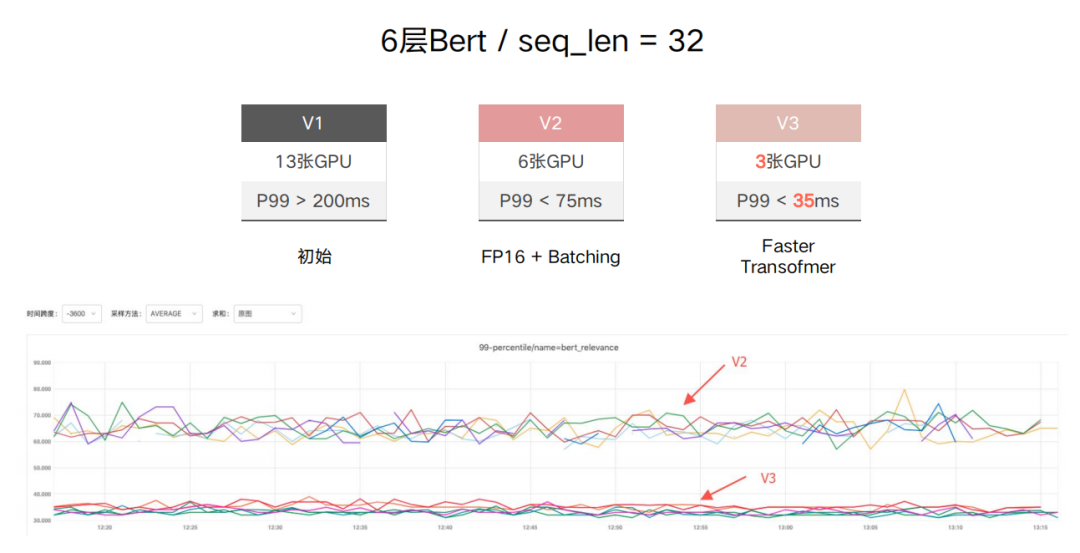
这个任务是一个问答排序问题,比如用户问"你喜欢维尼小熊嘛",这时对应的答案可能有好多种,按照先检索后排序的方法,需要对输入和每个回答计算一个相似度。我们使用的方案是Pointwise的BERT二分类,使用的模型为6层的BERT,输入长度为32,输入为Query+Reply,输出为0-1的相关性。下面是服务的优化效果,我们一共分为了三个版本,在使用了这三种优化方法后成功的将13张GPU压缩到了3张GPU,并且P99从200ms+降到了35ms,效果还是比较明显的。

我们的分享就结束了,一共讲了三个部分,先分享了我们在NLPCC小模型比赛上的经验,然后介绍了预训练推理优化在小米的相关落地,最后感谢赛事主办方CLUE&NLPCC提供这样一次赛事。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
社群推荐:


分享嘉宾
▬

赵群
小米 | 高级软件工程师
2014年硕士毕业于中国人民大学,同年加入微软Bing广告组。2017年加入小米AI实验室NLP应用组,参与了闲聊机器人在小米小爱同学的搭建与落地,现聚焦在预训练通用优化方向。
本文视频:

关于 CLUE:
CLUE benchmark 是由国内外的中文自然语言处理爱好者自发成立的开源组织,为更好的服务中文语言理解、任务和产业界,做为通用语言模型测评的补充,通过完善中文语言理解基础设施的方式来促进中文语言模型的发展。
成立至今,CLUE 已经在 arxiv 上发表三篇技术报告,包括 ner,pretrained model 以及 CLUE,在 github 上的项目 star 数已经破千。
CLUE 的模型排行榜目前已经吸引了阿里、腾讯、华为、google、Stanford、人大等大厂名校的同学的参与,第一名暂时为华为的 NEZHA,欢迎各路大神前来踢馆。
CLUE 成员包括来自 google、百度、阿里、腾讯等在内的大厂成员,也有来自 Stanford,CMU,爱丁堡,北大,人大等国内外知名院校的同学,也欢迎大家加入我们,一起为中文 NLP 做出贡献。
联系邮箱:
CLUEbenchmark@163.com
CLUE 网址:
https://www.CLUEbenchmarks.com
关于我们:

🧐分享、点赞、在看,给个三连击呗!👇




