EMNLP2019 | 领域自适应的人岗匹配研究

作者 | 人民大学、BOSS直聘
编辑 | 唐里
求职招聘市场长期存在着职位类别分布不均衡、新兴职类不断涌现的现象,这一定程度上会造成某些职类下的训练数据不够充分,从而难以获得较好的人岗匹配模型,影响推荐匹配效果。本文提出了一种结合多领域知识和层次化迁移学习的深度全局匹配网络(Transferable Deep Global Match Network),该模型能够对简历和岗位描述之间的全局匹配模式进行有效建模,并且实现了在三个层次上的迁移学习,即句子层级、句对匹配层级以及全局匹配层级。基于在线招聘平台BOSS直聘数据集的实验结果表明,本文提出的模型效果超过了state-of-the-art的人岗匹配推荐方法,各项指标均有提升。实验证明,针对训练数据不够充分的相关职类,通过引入合适的领域知识进行迁移学习,可以有效提升人岗匹配推荐效果。该论文已被自然语言处理领域国际顶级会议EMNLP2019接收。
背景介绍
近年来,随着互联网求职招聘平台的不断发展,如何解决不断涌现的新兴职类下的冷启动问题以及某些职类领域的训练样本不充分问题,显得十分重要。通过引入其他职类领域的有效知识来辅助学习相关职类的匹配特征,既有助于解决特定情况下的标记样本数据不足问题,也有助于理解不同职类领域间特征数据的联系。传统的领域自适应学习过程大多针对单文本特征进行迁移,而基于领域自适应的人岗匹配则是针对简历文本和岗位描述文本的语义匹配信息进行迁移,从具有充足训练样本的职类领域迁移文本匹配的语义信息以及匹配模式到训练样本不充分的职类领域,通过这样的迁移学习能够使得训练样本不充分的职类领域学习到更加有效的人岗匹配模型,从而提高推荐匹配效果。
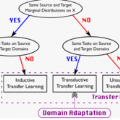
问题定义
本文定义的人岗匹配即简历文档与岗位描述文档的文档对匹配问题。在我们所研究的场景下,如果求职者与该岗位的招聘者发生聊天并且达成面试约定,则认为该求职者的简历文档与该招聘者的岗位描述文档达成匹配,即为正例;如果求职者与该岗位的招聘者发生聊天但双方最终未达成面试约定,则认为该求职者的简历文档与该招聘者的岗位描述文档未达成匹配,即为负例。其中,简历文档由多句相关工作经验组成,岗位描述文档由多句岗位职责及任职要求组成。同时,本文所研究的领域自适应限定在用一个训练样本丰富的职类领域辅助学习一个训练样本不充分的职类领域。这里训练样本不充分的职类领域定义为目标领域t,而源领域s则代表的是训练样本丰富的职类领域。
方法描述
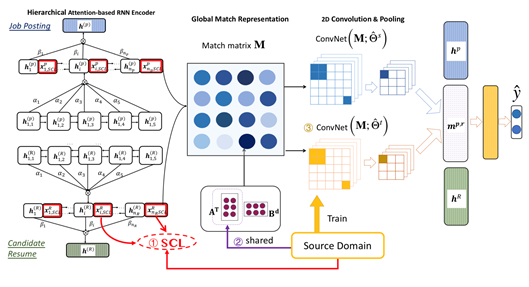
以下将从单领域人岗匹配模型和领域自适应两方面来介绍本文所采用方法的细节。如上图所示,单领域人岗匹配模型是一个面向简历文档和岗位描述文档的深度全局匹配网络框架,由层次化的文档表示、全局匹配表示,以及匹配结果预测三部分组成。领域自适应部分将重点介绍面向人岗匹配场景所设计的三个层次的迁移学习方法即结构化对应学习的句子增强表示、句对层级的匹配迁移,以及全局层级的匹配迁移。
单领域人岗匹配模型
1.层次化的文档表示
给定一个包含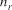
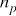
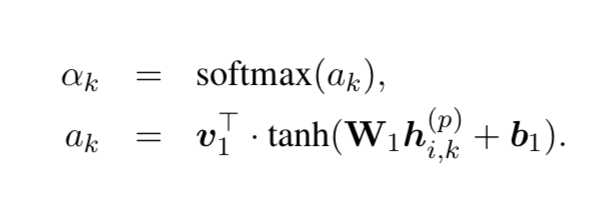
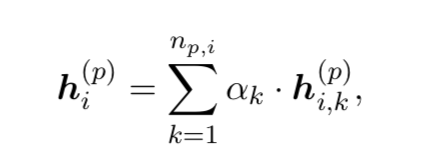
同样地,把句子当作是整个文档的基本单元,可以同样采用双向GRU和注意力机制来刻画整个简历或岗位描述的文档表示。
2.全局匹配表示
首先要计算简历文档与岗位描述文档句子间的相似度,输入有
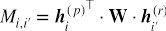
受到近些年图像识别领域的方法被引入解决文本匹配问题的启发,这里采用基于卷积的方式去刻画匹配层语义特征,以交错方式堆叠两个2维卷积层和2维最大池化层,并得到最终全局匹配层的表示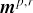
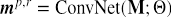
3.匹配结果预测
通过学习得到的匹配层表示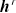
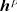
领域自适应的人岗匹配模型
如前文所述,为了解决冷启动问题以及某些职类领域训练样本不足导致的匹配效果变差,我们将训练好的源领域和目标领域的简历文档和岗位描述文档作为输入,经过迁移模块,输出目标领域的最终匹配结果。
1.结构化对应学习的句子增强表示
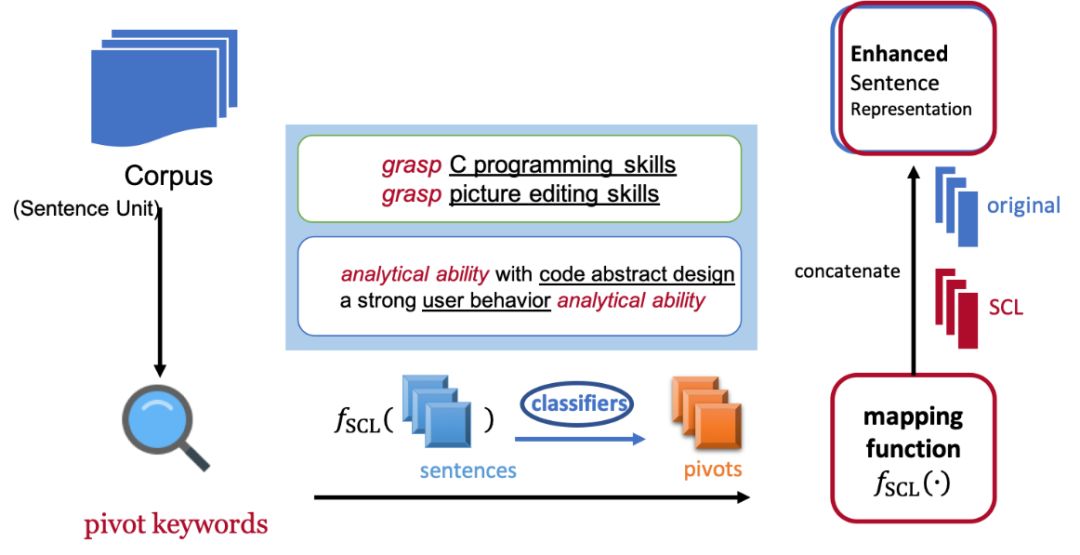
不同职类领域可能会有显著的语义差异,这使得获取跨领域的可迁移句子语义表示变得十分困难,受传统结构化对应学习的启发,这里采用跨领域的基于枢轴特征词的结构化对应学习(SCL)来刻画句子表示,考虑如下两个来自不同职类领域的片段。

虽然“C语言编程”和“图片编辑”的语义非常不同,但它们通过枢轴词grasp(掌握)来对齐这两个领域的技能要求。通过预先筛选出的多个高质量枢轴词,SCL算法能够通过大规模的共现数据来学习这种语义对齐。具体而言,SCL算法能够学习得到一个映射函数用来转换原始的表示到更具迁移性的表示。
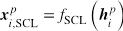
下图是一个SCL算法的流程图。
对于每一个句子得到基于层次化注意力机制的原始表示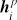
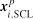
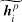
2.句对层级的匹配迁移
在计算简历文档与岗位描述文档间的句对匹配的时候,我们引入了变换矩阵w来计算句对相似度。
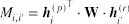
一个简单的迁移策略是将参数矩阵w共享在目标领域和源领域。然而这个方法会使得捕捉特定领域的匹配信息的灵活性降低,领域局部匹配信息在不同领域下可能会有较大变化,因此我们提出分解矩阵w变为两个矩阵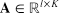
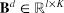
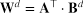
A由所有域共享,而B是针对特定领域的。通过这样的分解策略,不但可以实现跨域共享参数,也可以更好地捕获特定领域的信息。
3.全局层级的匹配迁移
我们认为不仅句子层级的语义表示和句对层级的语义匹配在不同职类领域是可迁移的,针对人岗匹配这一场景,全局层级的语义匹配也是可以跨领域进行迁移学习的。具体地,我们假设匹配过程中匹配矩阵到最终匹配表示的参数是可迁移的。因此,首先采用具有丰富训练样本的源领域训练参数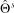

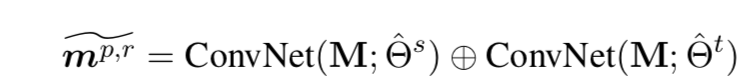
我们采用整体训练样本的二分类交叉熵损失作为目标损失,采用Adam进行参数优化。
实验效果
本文基于在线招聘平台BOSS直聘的6个职类领域的抽样数据集进行相关实验,包含2个具有较大规模抽样数据的职类和4个抽样数据规模较小的职类。具体数据描述如下表所示。
单领域匹配模型的结果
对比方法
1)DSSM [1]提出的深度结构语义匹配模型
2)BPJFNN [2]提出的基于循环神经网络的匹配模型
3)PJFNN [3]提出的基于卷积神经网络的匹配模型
4)APJFNN [2]提出的基于层级注意力机制的匹配模型
根据表格中的实验结果,可得如下结论:

1) 在单领域的实验中,与BPJFNN和PJFNN仅采用文档刻画整个句子的语义表示不同,APJFNN(层级注意力机制的匹配模型)在三个比较方法中取得了最好的效果,因为该方法设计了四个层级的细粒度的简历文档和岗位描述文档的句子粒度的表示,这也说明了采用细粒度的注意力机制可以有效捕捉语义信息。
2) 从实验结果看,我们提出的深度全局匹配网络模型均高于其他比较方法,这说明通过全局匹配的方式不但能捕获良好的句子语义信息,同时还能高效捕获句对之间的匹配模式和匹配语义特征,这对于人岗匹配这样的复杂匹配问题尤为重要。
领域自适应的结果
对比方法
1) SCL-MI[4] 基于互信息的方式抽取枢轴词进行结构对应学习的自适应
2) AE-SCL-SR[5] 在SCL上提出共享低维表示
3) ASP-MTL[6] 提出对抗多任务学习的框架去学习共享和私有的表示
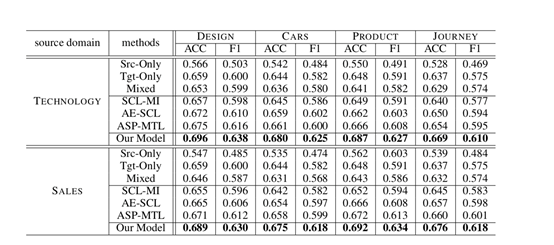
根据表格中的实验结果,可得如下结论:
1) 为了说明合理引入领域知识才能提升匹配效果,这里Tgt-Only代表了单领域训练的效果,Src-Only代表使用源领域训练的模型对目标领域预测,Mixed代表了将源领域和目标领域数据混合。可以发现混合数据或使用源领域进行目标领域预测都会降低匹配效果,这说明简单混合或不合理选择领域有关的特征信息引入其它领域,会降低匹配的精度。
2) 在对比方法中,采用AE-SCL和ASP-MTL,均较单一领域的匹配效果有所提升,尤其是ASP-MTL取得比较方法里最好的效果,由于ASP-MTL采用了对抗的机制,既使用共享特征又保留独享特征,合理迁移了相关的知识从而取得更好的效果。
3) 我们的方法在所有方法里取得了最好的效果,可以看到由于在该方法中既进一步增强句子级别的语义表示又加强了匹配语义特征的迁移,使得这样的模型在样本不充分的领域取得了更好且更具解释性的表现。
除了上述的实验指标分析,我们也同时分析了为什么采用重用源域卷积层可以进一步提升表现。

在上图中可以看出全局匹配层在正例和负例的匹配模式明显不同,对比图a和图c可以看出它们的匹配模式通常发生在对角线上,这说明绝大部分的岗位描述和简历能匹配且在所有领域具备相似的情况,而在不匹配的例子中虽然也存在大量的匹配对,但它们的匹配模式通常不在对角线上,这说明这样的匹配往往是不符合要求的匹配且存在极大的不相关性,也侧面说明了绝大部分的匹配需要做到满足匹配覆盖度。
同时,该图也说明了迁移全局匹配信息的重要性,可以发现在目标领域和源领域存在着大量相似的匹配模式,这些匹配模式下虽然背后所表达的语义信息不同,但却存在很多类似的匹配结构,进一步证明了迁移全局层级的语义匹配信息的重要性和合理性。
参考文献
[1] Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Conference on information and knowledge management, pages 2333–2338. ACM.
[2] Chuan Qin, Hengshu Zhu, Tong Xu, Chen Zhu, Liang Jiang, Enhong Chen, and Hui Xiong. 2018. Enhancing person-job fit for talent recruitment: An ability-aware neural network approach. In In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR-2018) , Ann Arbor, Michigan, USA.
[3] Chen Zhu, Hengshu Zhu, Hui Xiong, Chao Ma, Fang Xie, Pengliang Ding, and Pan Li. 2018. Person-job fit: Adapting the right talent for the right job with joint representation learning. ACM Transactions on Management Information Systems ACM TMIS.
[4] John Blitzer, Mark Dredze, and Fernando Pereira. 2007. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th annual meeting of the association of computational linguistics, pages 440–447.
[5] Yftah Ziser and Roi Reichart. 2017. Neural structural correspondence learning for domain adaptation. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 400–410.
[6] Pengfei Liu, Xipeng Qiu, and Xuanjing Huang. 2017. Adversarial multi-task learning for text classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1–10.

张钹院士:人工智能的魅力就是它永远在路上 | CCAI 2019


点击“阅读原文” 查看 EMNLP 2018 Facebook、谷歌 39 篇会议论文合集