【学界】北大、清华、微软联合提出RepPoints,比边界框更好用的目标检测方法

来源:新智元
【导读】来自北京大学、清华大学和微软亚洲研究院的研究人员提出一种新的、更精细的对象表示方法RepPoints,抛弃了流行的边界框表示,结果与最先进的基于 anchor 的检测方法同样有效。
目标检测是计算机视觉中最基本的任务之一,也是许多视觉应用的关键组成部分,包括实例分割、人体姿态分析、视觉推理等。
目标检测的目的是在图像中定位目标,并提供目标的类别标签。
近年来,随着深度神经网络的快速发展,目标检测问题也取得了长足的进展。
当前先进的目标检测器很大程度上依赖于矩形边界框来表示不同识别阶段的对象,如 anchors、proposals 以及最终的预测。
边界框使用方便,但它只提供目标的粗略定位,导致对目标特征的提取也相当粗略。
近日,来自北京大学、清华大学和微软亚洲研究院的杨泽、王立威、Shaohui Liu 等人在他们的最新论文中,提出了一种新的、更精细的对象表示方法 ——RepPoints (representative points),这是一组对定位和识别都很有用的样本点 (sample points)。

论文地址:
https://arxiv.org/pdf/1904.11490.pdf
给定训练的 ground truth 定位和识别目标,RepPoints 学会自动以限制目标的空间范围的方式来排列自己,并表示在语义上重要的局部区域。此外,RepPoints 不需要使用 anchor 来对边界框的空间进行采样。
作者展示了一个基于 RepPoints 的、anchor-free 的目标检测器,不需要多尺度训练和测试就可以实现,而且与最先进的基于 anchor 的检测方法同样有效,在 COCO test-dev 检测基准上达到了 42.8 AP 和 65.0 AP₅₀。
在目标检测过程中,边界框是处理的基本元素。边界框描述了目标检测器各阶段的目标位置。
虽然边界框便于计算,但它们仅提供目标的粗略定位,并不完全拟合对象的形状和姿态。因此,从边界框的规则单元格中提取的特征可能会受到包含少量语义信息的背景内容或无信息的前景区域的严重影响。这可能导致特征质量降低,从而降低了目标检测的分类性能。
本文提出一种新的表示方法,称为 RepPoints,它提供了更细粒度的定位和更方便的分类。
如图 1 所示,RepPoints 是一组点,学习自适应地将自己置于目标之上,其方式限定了目标的空间范围,并表示语义上重要的局部区域。
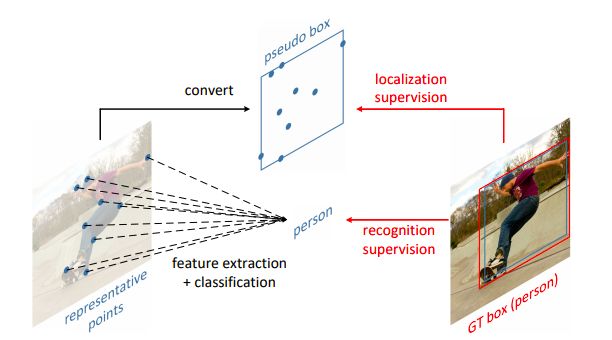
图 1:RepPoints 是一种新的目标检测表示方法
RepPoints 的训练由目标定位和识别目标共同驱动,因此,RepPoints 与 ground-truth 的边界框紧密相关,并引导检测器正确地分类目标。
这种自适应、可微的表示可以在现代目标检测器的不同阶段连贯地使用,并且不需要使用 anchors 来对边界框空间进行采样。
RepPoints 不同于用于目标检测现有的非矩形表示,它们都是以自底向上的方式构建的。这些自底向上的表示方法会识别单个的点 (例如,边界框角或对象的末端)。此外,它们的表示要么像边界框那样仍然是轴对齐的,要么需要 ground truth 对象掩码作为额外的监督。
相反,RepPoints 是通过自顶向下的方式从输入图像 / 对象特征中学习的,允许端到端训练和生成细粒度的定位,而无需额外的监督。
为了证明 RepPoints 表示的强大能力,我们提出了一种基于可变形 ConvNets 框架的实现,该框架在保证特征提取方便的同时,提供了适合指导自适应采样的识别反馈。
我们发现,这个无 anchor 的检测系统在对目标进行精确定位的同时,具有较强的分类能力。在没有多尺度训练和测试的情况下,我们的检测器在 COCO 基准上实现了 42.8 AP 和 65.0 AP₅₀ 的精度,不仅超过了所有现有的 anchor-free 检测器,而且性能与最先进的 anchor-based 的基线模型相当。
本节将描述 RepPoints,以及它与边界框的区别。
边界框表示
边界框是一个 4-d 表示,编码目标的空间位置,即 B = (x, y, w, h), x, y 表示中心点,w, h 表示宽度和高度。
由于其使用简单方便,现代目标检测器严重依赖于边界框来表示检测 pipeline 中各个阶段的对象。
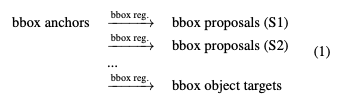
性能最优的目标检测器通常遵循一个 multi-stage 的识别范式,其中目标定位是逐步细化的。其中,目标表示的角色如下:
RepPoints
如前所述,4-d 边界框是目标位置的一个粗略表示。边界框表示只考虑目标的矩形空间范围,不考虑形状、姿态和语义上重要的局部区域的位置,这些可用于更好的定位和更好的目标特征提取。
为了克服上述限制,RepPoints 转而对一组自适应样本点进行建模:
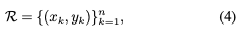
其中 n 为表示中使用的样本点的总数。在这项工作中,n 默认设置为 9。
Learning RepPoints
RepPoints 的学习是由目标定位损失和目标识别损失共同驱动的。为了计算目标定位损失,我们首先用一个转换函数 T 将 RepPoints 转换为伪框 (pseudo box)。然后,计算转换后的伪框与 ground truth 边界框之间的差异。
图 3 显示,当训练由目标定位损失和目标识别损失组合驱动时,目标的极值点和语义关键点可以自动学习。

图 3: 学习的 RepPoints 的可视化和来自 COCO minival set 的几个例子的检测结果。通常,学习的 RepPoints 位于目标的端点或语义关键点上。
我们设计了一种不使用 anchor 的对象检测器,它利用 RepPoints 代替边界框作为基本表示。
目标表示的演化过程如下:

RepPoints Detector (RPDet) 由两个基于可变形卷积的识别阶段构成,如图 2 所示。
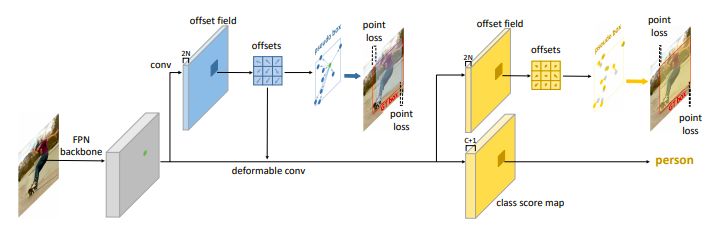
图 2:RPDet (RepPoints detector) 的概览,以特征金字塔网络 (FPN) 为主干
可变形卷积与 RepPoints 很好地结合在一起,因为它的卷积是在一组不规则分布的采样点上计算的,反之,它的识别反馈可以指导训练这些点的定位。
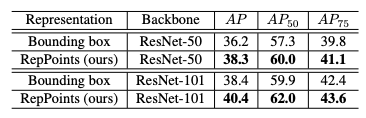
表 1:目标检测中 RepPoints 与边界框表示的比较。除了处理给定的目标表示之外,网络结构是相同的。
从表 1 可以看出,将目标表示从边界框变为 RepPoints,可以带来一定程度的性能提升,如使用 ResNet-50 作为主干网络时提升了 2.1 mAP,使用 ResNet-101 时提升了 2.0 mAP。这表明相对于边界框,RepPoints 表示在对象检测方面具有优势。
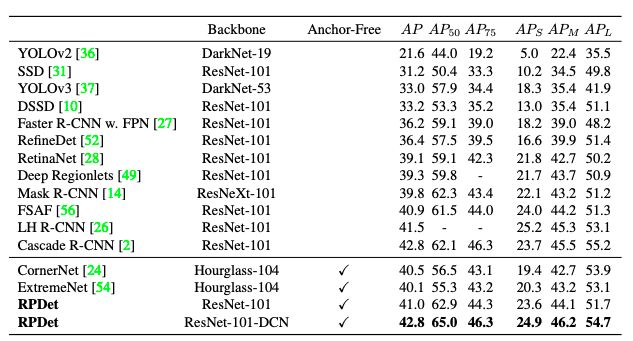
表 7:将所提出的 RPDet 与 COCO test-dev 上最先进的检测器进行比较。
如表 7 所示,在没有 multi-scale 训练和测试的情况下,所提出的框架使用 ResNet-101-DCN 主干网络实现了 42.8 AP,与基于 anchor 的 Cascade R-CNN 方法相当,性能优于现有的所有不采用 anchor 的检测器。此外,RPDet 获得了 65.0 的 AP₅₀,大大超过了所有基线。
论文地址:
https://arxiv.org/pdf/1904.11490.pdf
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得



