一种小目标检测中有效的数据增强方法
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文介绍了一种小目标检测中有效的数据增强方法,论文标题是《Augmentation for small object detection》

作者 | autocyz
原文地址 | https://zhuanlan.zhihu.com/p/57760020
论文地址 | https://arxiv.org/pdf/1902.07296.pdf
什么是小物体?

在COCO数据集,其给出了小目标、中等目标、大目标的区分定义,如上图。主要是看目标框的大小。
小物体的检测效果怎么样?
COCO上state-of-art目标实例分割算法的性能情况:
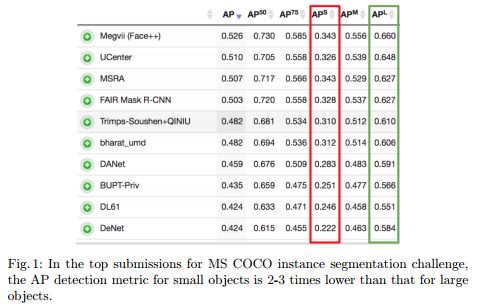
看上图,可以发现小目标的检测性能 几乎只有大目标 的一半。因此,小目标的检测性能成了很多任务、算法的瓶颈所在。
分析:为何小目标的检测性能不好
直观上,当我们看到一幅时,我们首先关注的是图像中比较醒目的图像,一般的,这些醒目的图像往往在图中所占的比例比较大。而小目标目标往往被我们忽略。数据集中也存在这种情况,很多图像中包含的小物体并没有被标出。另外,小目标所在区域较小,在提取特征的过程中,其提取到的特征非常少,这些都不利于我们对小目标的检测。
下面从量化的角度来分析一下为何小目标不好做。
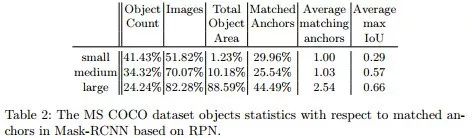
上图是在COCO上的统计图,可以发现COCO中,小目标的个数还是很高的,占到了41.43%,但是含有小目标的图片只有51.82%,大目标(large)所占比例为24.24%,但是含有大目标的图像却有82.28%。这说明有一半的图像是不含小目标的,大部分的小目标都集中在一些少量的图片中。这就导致在训练的过程中,模型有一半的时间是学习不到小目标的特性的。
另外,对于小目标,平均能够匹配的anchor数量为1个,平均最大的IoU为0.29,这说明很多情况下,有些小目标是没有对应的anchor或者对应的anchor非常少的,且即使有对应的anchor,他们的IoU也比较小,平均最大的IoU也才0.29。
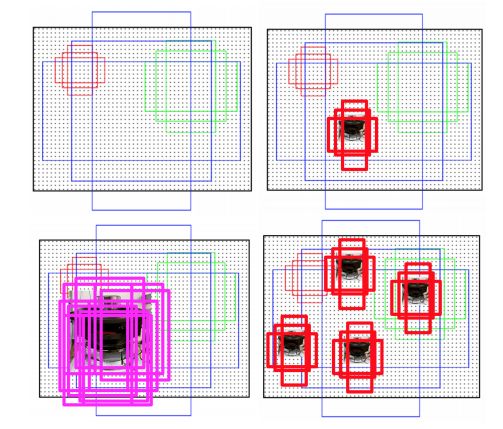
如上图,左上角是一个anchor示意图,右上角是一个小目标所对应的anchor,一共有只有三个anchor能够与小目标配对,且配对的IoU也不高。左下角是一个大目标对应的anchor,可以发现有非常多的anchor能够与其匹配。匹配的anchor数量越多,则此目标被检出的概率也就越大。
基于上述分析,我们可以得到小目标不好检测的两大原因:
1)数据集中包含小目标的图片比较少,导致模型在训练的时候会偏向medium和large的目标。
2)小目标的面积太小了,导致包含目标的anchor比较少,这也意味着小目标被检测出的概率变小。
本文改进方法
1)对于数据集中含有小目标图片较少的情况,使用过度采样(oversample)的方式,即多次训练这类样本。
2)对于第二类问题,则是对于那些包含小物体的图像,将小物体在图片中复制多分,在保证不影响其他物体的基础上,人工增加小物体在图片中出现的次数,提升被anchor包含的概率。
如上图右下角,本来只有一个小目标,对应的anchor数量为3个,现在将其复制三份,则在图中就出现了四个小目标,对应的anchor数量也就变成了12个,大大增加了这个小目标被检出的概率。从而让模型在训练的过程中,也能够有机会得到更多的小目标训练样本。
具体的实现方式如下图:图中网球和飞碟都是小物体,本来图中只有一个网球,一个飞碟,通过人工复制的方式,在图像中复制多份。同时要保证复制后的小物体不能够覆盖该原来存在的目标。

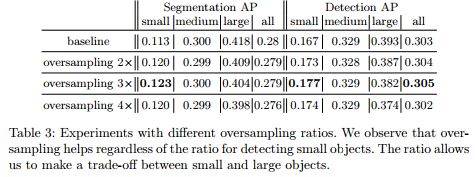
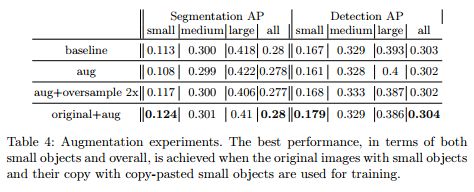
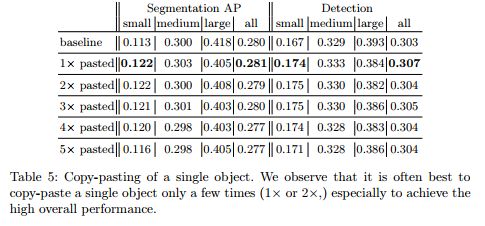
具体性能的提升文章做了较多的实验对比,可以参看论文。
*延伸阅读
聊聊目标检测中的多尺度检测(Multi-Scale),从 YOLO到FPN,SNIPER,SSD 填坑贴和极大极小目标识别
目标检测算法优化技巧:Bag of Freebies for Training Object Detection
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~




