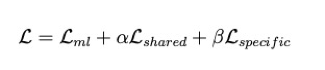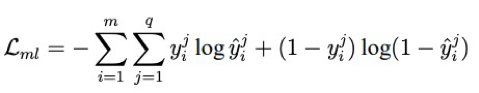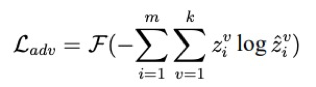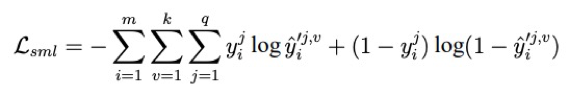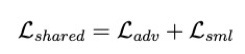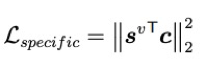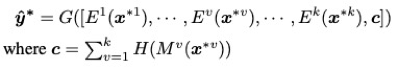IJCAI 2019 将于 8 月 10 日至 16 日在中国澳门隆重召开,本届大会共收到 4752 篇有效提交论文,收录 850 篇,接收率为 17.9%。据机器之心了解,阿里文娱摩酷实验室共有 5 篇论文被接收。
本文对其中一篇论文《Multi-View Multi-Label Learning with View-Specific Information Extraction》进行解读。该论文由东南大学、阿里巴巴集团优酷人工智能平台合作完成,旨在利用视图私有信息对示例的标记进行预测。
![]()
链接:http://palm.seu.edu.cn/zhangml/files/IJCAI'19.pdf
在真实世界中,存在许多对象兼具多样性的描述与丰富的语义信息。例如,对图 1(a) 的风景图片,可以通过 HSV 色彩直方图、全局特征 Gist、尺度不变特征 SIFT 等方式进行表征,同时可以被打上 {雪景,亭子,湖} 等标记。又例如,对图 1(b) 中的剧集《长安十二时辰》进行标注时,通常可以通过多种信息源进行表征,如标题、音频、封面图、视频帧等,同时该视频可以被打上 {长安,易烊千玺,雷佳音,古装剧} 等标记。
![]()
在此场景下,若使用传统的多标记学习算法,在特征空间需对多样的表征信息进行合并。方式一是将多个特征向量进行对应位相加,然而各特征向量的维度可能不完全相同,无法直接操作;方式二是将不同种表征信息进行拼接,但是这样会导致特征维度过高,当样本数量不足时,容易带来过拟合的问题,影响最终的训练效果。因此,在此场景下进行学习的关键,是如何对种类多样的信息(多样表征信息与多个标注信息)进行有效整合,多视图多标记学习(Multi-view multi-label learning)是一种常用的解决此类问题的框架。
现有方法均试图挖掘所有视图间的共享信息,然而当他们试图挖掘所有视图的共享信息来消除噪声和冗余时,通常的做法是将各个视图不同维度的特征向量映射到一个共享子空间,但是各视图特征向量的映射矩阵是互不相同的,也就是说各视图的映射过程是完全独立的,在此情况下,视图之间缺少交流,很难保证挖掘到的是真正的共享信息。
同时,现有方法在进行多标记预测时,各个视图的私有贡献被直接忽略。
举例来讲,一张画着粉色玫瑰的图片被打上了 { 粉色,花 } 的标记,同时它通过 HSV 和 Gist 两种方式进行表征,我们可以很容易发现标记与表征之间的关联,即 { 粉色 } 是通过 HSV 描述所得到的标 记,{ 花 } 是通过 Gist 描述得到的,然而现有的方法通常是希望挖掘 HSV 和 Gist 所描述的公共信息,而忽略了不同表征对标记的私有贡献。显然,在这一例子中,保留视图的私有信息要比挖掘其公共信息更加符合直观。
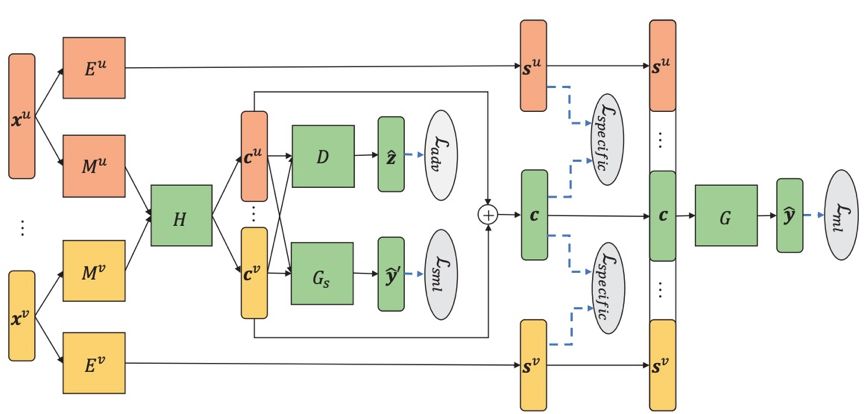
基于以上两点考虑,本文作者提出基于视图私有信息挖掘的多视图多标记算法 SIMM(view-Specific Information extraction for Multi-view Multi-label learning),同时进行共享子空间挖掘与视图私有信息提取。
作者认为,视图提供的信息分为两个方面:共享和私有。SIMM 算法分为两个步骤:共享子空间挖掘 (Shared Subspace Exploitation) 与视图私有信息提取 (View-Specific Information Extraction)。SIMM 算法通过神经网络框架来实现两个关键步骤,整体损失函数:
![]()
其中,L_ml 为多标记损失,控制最终模型的标记输出。在该论文中,使用「一阶」策略进行计算:
![]()
受文献 [1] 启发,SIMM 通过最小化一个对抗损失 L_adv 来混淆视图到共享子空间的映射过程,希望迷惑判别器 D,使其无法判断输入的共享子空间表征来自于哪一个视图。
令 c^v 表示第 v 个视图特征 x^v 的共享子空间表征向量,由共享子空间提取层 H 提取得到。文中引入视图标记向量 z_i,仅 z^v_i 为 1,表示 c^v_i 来自于第 v 个视图。令 hat(z) 为判别器预测的视图标记向量,对抗损失 L_adv 表示为:
![]()
F 需选择一个单调递减函数,通过这种设定,作者希望迷糊判别器,无法判断输入的共享子空间表达来自于哪一个视图,当判别器无法分辨时,可以认为输入的特征向量不含判别性的私有信息,表明 c^v 中仅包含共享信息。
然而,仅利用 L_adv 可能会带来一些问题:单纯的噪声不含任何信息,但也极有可能迷惑判别器,但噪声不能表示包含共享信息的表征向量。因此,作者额外增加了共享子空间多标记损失 L_sml 保证 c^v 具有语义:
![]()
在 SIMM 算法中,共享子空间的挖掘不再只是各个视图独立进行,H 和 D 在训练中可以接触到来自所有视图的特征向量,增加了视图间的交互过程,共享子空间挖掘的整体损失表示为:
![]()
直观上,什么是视图私有信息,似乎无法被直接明确的定义,本文作者选择的方式是,将公共信息从原始信息中剥离,并认为保留下来的部分为视图私有信息。这一想法在文中通过约束正交损失实现,s^v 表示由私有信息提取层 E^v 提取得到的 l 维特征向量,c 表示包含所有视图公共信息的 l 维特征向量,由 c^v 相加得到。私有信息提取损失 L_specific 约束 s^v 和 c 间的正交性:
![]()
L_specific 希望从原始特征 x^v 中提取出的 s^v 和 c 相差越大越好。
![]()
模型整体框架图如图 2 所示,在训练阶段,同时优化各模块参数,测试阶段,给定未见示例 x^*,模型预测输出结果由下式得到:
![]()
在实验部分,论文中共选取了 8 个多视图多标记数据集,包括 6 个基准数据集和 Youku 视频标注数据集:
![]()
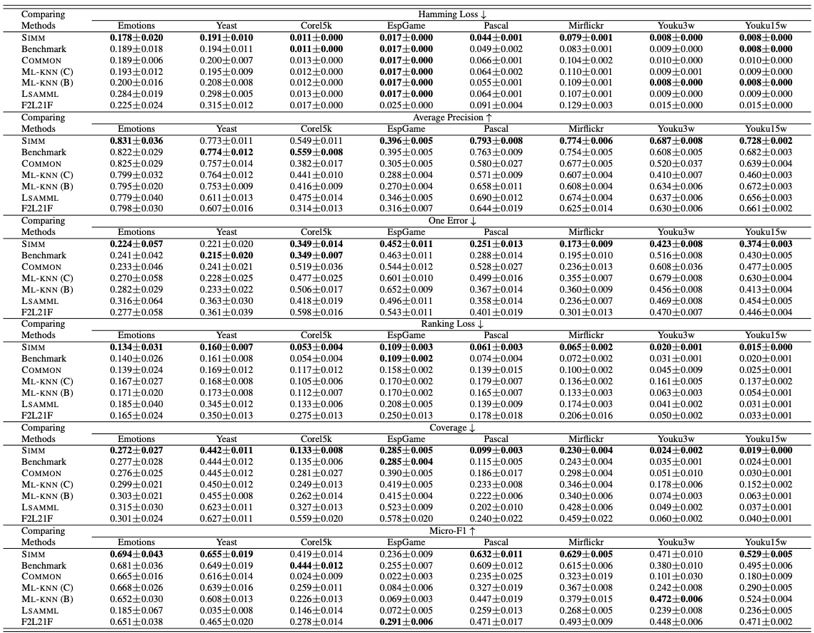
6 个对比算法包括:2 个与 SIMM 相关的基准算法、2 种不同输入的多标记算法 ML-kNN 和 2 个多视图多标记算法 F2L21F、LSAMML。实验指标选择 6 种被广泛使用的多标记评价指标 Hamming Loss、Average Precision、One Error、Coverage、Micro-F1,对 Average Precision 和 Micro-F1 来说,结果越大越好,对其他 4 个指标来说,结果越小越好,在每个数据集上,均采用十折交叉验证计算各指标均值与标准差。结果如下:
![]()
加粗部分为 SIMM 算法在该指标下优于对比算法的情况,SIMM 算法在 87.5% 的情况下排名第一,在 10.4% 的情况下排名第二。
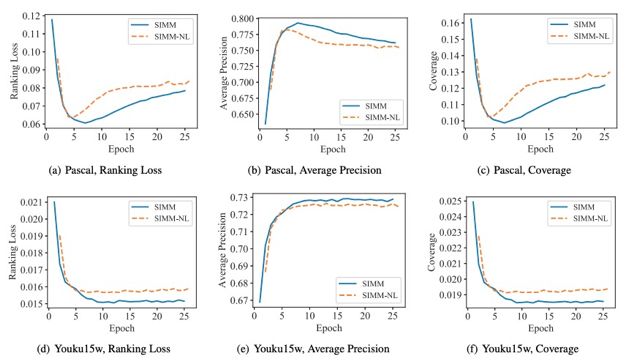
同时,在文中为分析 L_shared 和 L_specific 的作用,作者保留论文结构,将平衡参数 alpha 和 beta 置为 0。图 3 中结果显示,在 Pascal 和 Youku15w 数据集下,无损失约束时,性能要劣于 SIMM 算法,说明 SIMM 在一定程度上帮助分离各视图的共享和私有信息。
![]()
该论文提出了一种多视图多标记学习算法 SIMM,首先 SIMM 同时优化一个混淆的对抗损失与多标记损失来提取视图间的共享信息,其次加入正交约束,利用视图私有的判别信息,最终通过共享和私有信息的协同作用,进行语义学习。在 8 个数据集、6 个对比算法、6 种评价指标上的对比实验,可以观察到 SIMM 算法较自身基准模型、传统多标记算法、多视图多标记算法均有明显提升。
[1] Liu, Pengfei, Qiu, Xipeng, and Huang, Xuanjing. Adversarial Multi-task Learning for Text Classification[C]. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada, 2017. 1–10.
[2] Min-Ling Zhang and Zhi-Hua Zhou. ML-kNN: A lazy learning approach to multi-label learning. Pattern recognition, 40(7):2038–2048, 2007.
[3] Min-Ling Zhang and Zhi-Hua Zhou. A review on multi-label learning algorithms. IEEE transactions on knowledge and data engineering, 26(8):1819–1837, 2014.
[4] Xiaofeng Zhu, Xuelong Li, and Shichao Zhang. Block-row sparse multiview multilabel learning for image classification. IEEE transactions on cybernetics, 46(2):450–461, 2016.
[5] Changqing Zhang, Ziwei Yu, Qinghua Hu, Pengfei Zhu, Xinwang Liu, and Xiaobo Wang. Latent semantic aware multi-view multi-label classification. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA,4414–4421, 2018.
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com