通俗易懂的让你了解深度学习中的注意力机制
1.前言
本文主要介绍一下,目前在深度学习中比较火的一门技术——Attention 机制(Attention Mechanisms)。
这门技术目前在 seq2seq(序列到序列模型,如图文转换,机器翻译,语音识别等) 的工作中,基本上已成标配。而在当前的 NLP 研究中,最近一年来,一些比较有影响力的算法模型,如 Google 的大杀器 bert 模型,OpenAI 提出的 GPT-2 ,其基本思想就是 Attention 机制。
Attention 来源:人类视觉的选择性注意力机制
视觉的注意力机制是人类视觉大脑特有的一种处理机制,这种机制讲的是,人类在看到一张图片时,主要进行以下三项工作:
选取重点关注的目标区域
着重对目标区域投入大脑精力
忽略其他非目标区域信息
该机制使得人类大脑能够更加高效的分析得到有用内容,如下图所示,红色区域代表视觉更关注的区域。当我们大脑通过视觉感知这张图片时,会更关注人脸、文章标题、文章首部等内容[1]。
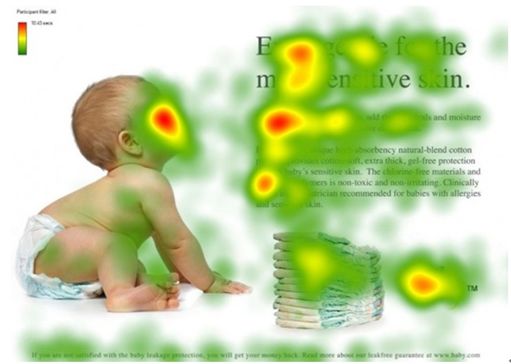
图1 人类观察图片注意力热度分布
简单的概括一下:
Attention机制=聚焦
我们在日常的机器学习建模中,其实也用到了“Attention”的的方法,如 Logistic 回归:
模型输入:x1,x2,...xn
模型输出:y
模型表达式:
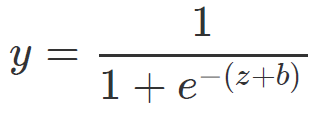
其中,
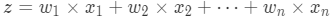
此处,我们模型学习到的变量系数wi决定了变量xi对目标 y 的影响程度,其绝对值越大,表明对 y 的影响也越大,我们通过建模学习到的就是不同变量对目标的决定程度,在后期决策分析时,重点关注影响程度大的变量,这就是Attention的思想。
回过头来,在深度学习领域,鉴于 Attention 来源于人类视觉领域,我们先介绍图像识别中 Attention 是如何使用的。
2. 图像识别中的 Attention 机制
下图为李飞飞 2015 年在 TED 上做汇报——
《How we are teaching computers to understand pictures?》

图2 李飞飞TED演讲
李飞飞教授主要讲的是如何让计算机理解图片,就是看图说话(Image Caption),其现场演示了向计算机输入一张图片,输出描述语:
a person sitting at a table with a cake
我们思考下,人类大脑具体是如何对一张图片进行描述的,类似“把大象塞进冰箱”的操作,将这一过程分为三步:
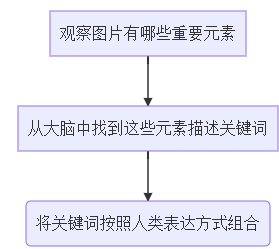
这一过程如何用计算机进行实现呢?我们可以进行以下操作
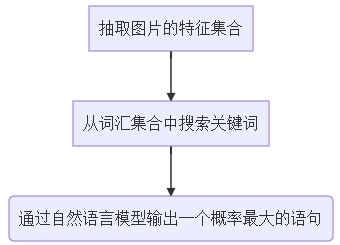
针对此类问题,研究人员首先提出了一种 seq2seq 模型进行处理,这种模型结构基本类似,主要包含两个神经网络,针对图文转换,具体为:
神经网络1:此部分主要为从图片中自动提取特征,作为后面生成语句的判定依据
神经网络2:通过前者从图片中提取到的特征,按顺序从头预测一个个 word,并最终拼接成一句完整的语句
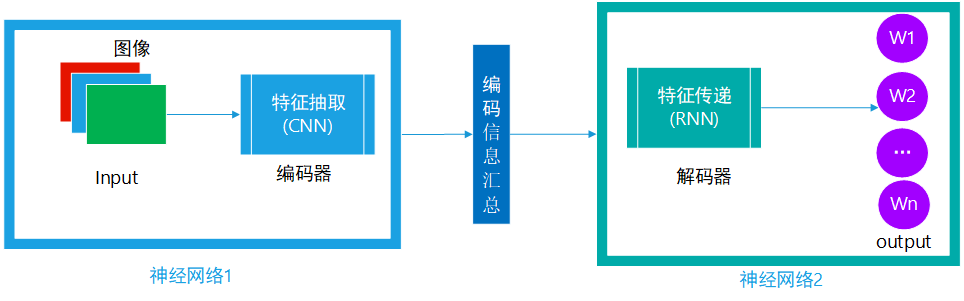
图3 seq2seq模型示意图
这种模型还是存在一些瑕疵的,下游的神经网络预测一个个输出时,面对上游提取到的信息是一样的,这个很显然是不科学的,因为每个关键词,与图片各个特征的关系是有区别的。
如图2生成的一句描述语中,单词person和cake依赖的图片特征可能是完全不同的,person更关注眼、嘴、鼻等特征,而cake更关注圆柱物体的特征。
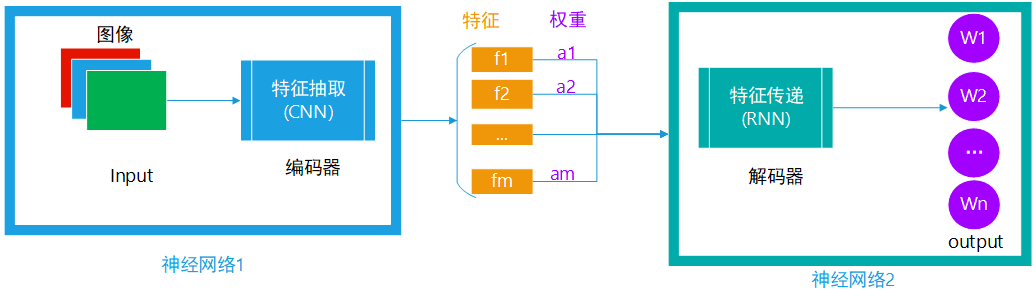
针对上面的框架,做以下调整:
直接保留编码器提取的特征,而非将其汇总成一个语义编码
在下游解码器预测时,输入是上游的特征与其权重的加权求和
图4 seq2seq+Attention模型示意图
利用权重可以评判预测的关键词与提取特征的相关程度。下面我们来看下Kelvin Xu等人[2]是如何实现的:首先利用 CNN 进行图像特征抽取;然后在下游预测部分,采用 Attention + LSTM 的方法,一步步生成一句话。
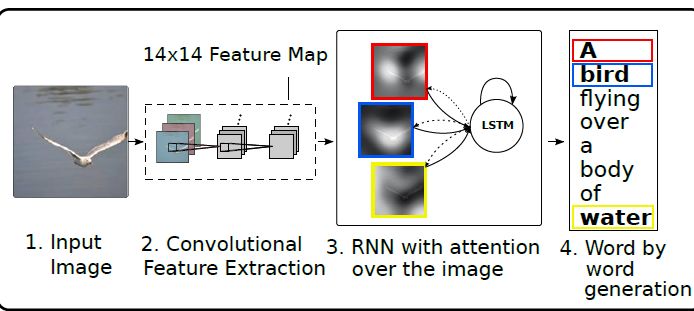
最终达到下图效果,图片部位的明亮程度代表与标注关键词的密切程度,亮度越高,相关性越强。第一张图中,针对关键词 frisbee,左上角部位表示相关性最高;第二个图片描述语中的 girl,与图片右上角部位相关性最高。

图5 关键词与图片区域相关灰度图
以上介绍了 Attention 机制,以及在图像识别中应用,下面我们来看看 Attention机制在 NLP 中如何使用。
3. NLP 中的 Attention 机制
在 NLP 领域,与图文转换非常相似的一个场景是机器翻译,也是一个序列到序列的场景。Ilya Sutskever 等人[3],结合自然语言领域的特征,提出了一种 seq2seq 模型进行 English - French 的机器翻译模型,鉴于 NLP 领域数据的序列特征,模型编码器和解码器使用的模型都是 RNN 的算法。
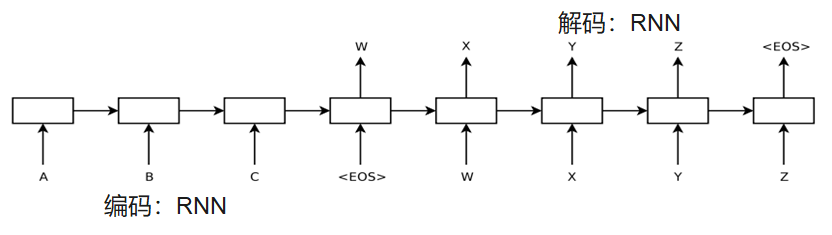
对于目标单词的预测概率计算方式为
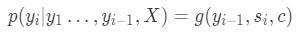
预测值主要受三部分影响
上一个预测值:yi-1
解码器隐藏层当前状态:si=f(si-1,yi-1,c)
编码器汇总输入上下文信息:c
可以看到解码器,在预测单词yi时,依赖于输入的上下文汇总信息是一致的,都是c,与图文转换类似,这也是不科学的。
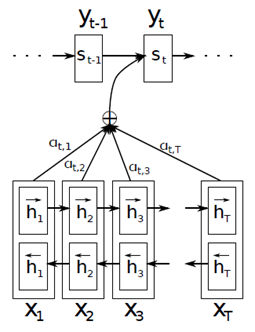
所以,Bahdanau 等人[4]利用 seq2seq + Attention 进行机器翻译,如下图所示,此处,对于输出的每个位置上单词的预测概率:
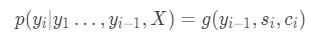
模型结构如图所示:
可以看到,该预测受三部分影响:
- 上一个预测值:yi-1
- 解码器隐藏层当前状态:si=f(si-1,yi-1,ci)
- 当前时刻编码器汇总的输入上下文信息:
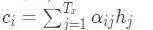
其中,
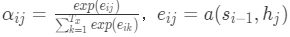
可以看到,权重aij是由编码层的hj和解码层的si-1的计算,该权重可用于衡量输入xj和输出hi的关系。用灰度图(1:白色,0:黑色)表示输入的序列单词与输出的序列单词的相关性,对应元素点的颜色越趋近于白色,说明横纵坐标轴的两个单词相关性越强。

图6 机器翻译目标词与输入词相关灰度图
下面介绍下在我们的日常的文本分类中,如何使用 Attention 机制。
4. Attention 机制在文本分类中的应用
我们在公司的文本分析工作中,其中一部分工作是要对舆情数据进行分析,很直接的应用,就是想了解下他人对我们的评价如何,这个时候就要进行情感分析,其实就是将文本进行二分类——好评和差评,那么我们是如何利用深度学习的方法进行建模的呢?
4.1 基于 RNN 的文本分类模型
我们建模的过程如下所示:
对于文本数据,我们进行预处理得到一个个单词
将单词转为词向量,我们使用腾讯 AI Lab 公开的词向量数据集作为初始值,后面随着模型训练进行微调
之后将词向量传入 RNN 模型(我们用的是 LSTM 模型),利用 RNN 的性质,抓取整个输入文本的上下文信息,汇总得到一个文档向量
利用汇总得到的文档向量,通过一个全连接层,将信息汇总,通过 softmax 转换成分类概率
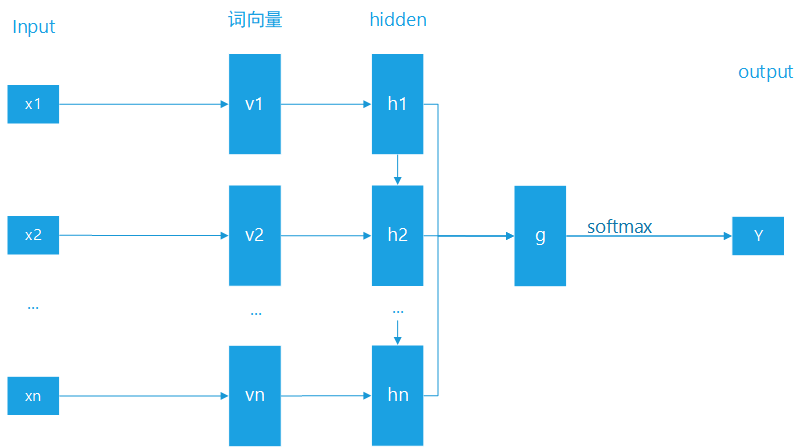
图7 RNN文本分类模型示意图
4.2 基于 RNN + Attention 的文本分类模型
为了优化模型,以及抽取出具体影响文本情感分类的关键词,我们考虑在 RNN 的基础上,加上 Attention 机制。
具体如下图,模型针对 4.1 做了一步优化,在对隐藏层进行信息整合时,先利用隐藏层的h1,h2,...,hn计算对应的权重,a1,a2,...,an,然后计算gi=hi*ai,最终将gi进行汇总,同样利用 softmax 的方式,即可得到分类概率。
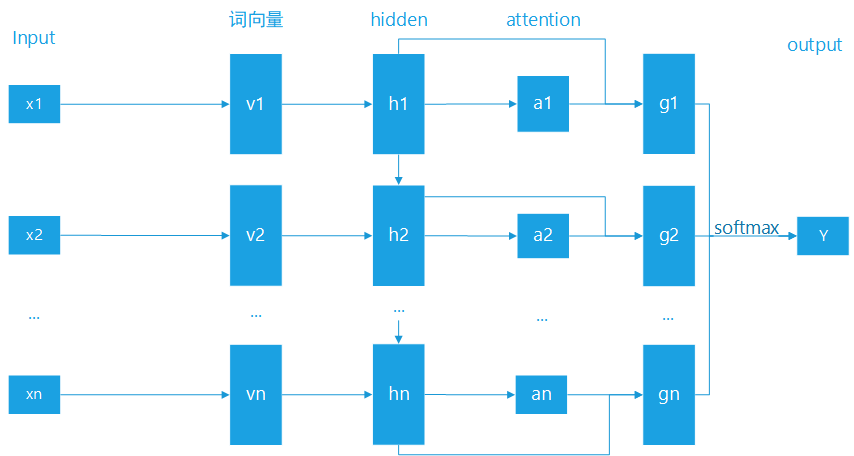
图8 RNN+Attention文本分类示意图
当然我们在应用中,仅使用了基于词的 Attention 机制,Jader Abreu 等人[5]提出了一个多层的 RNN+Attention 的模型——Hierarchical Attentional Hybrid Neural Networks(简称 HAHNN),该模型将一条文本分类两层,词语层和句子层,使用两层 RNN + Attention 的方式,一层用于抽取基于 word 的 Attention,另外一层用于抽取由word组成的sentence的 Attention,最终汇总进行文本类别的预测。
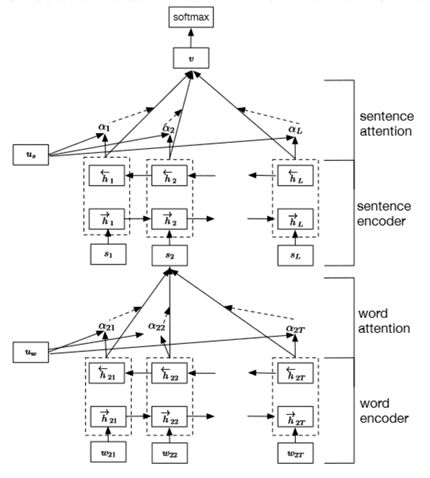
图9 双层RNN+Attention文本分类示意图
在我们的实际工作中,考虑到模型复杂度和标注数据的成本,未采用HAHNN模型。
我们搭建RNN + Attention模型进行文本分类,采用tensorflow进行开发,具体代码可访问以下github网址[7]查看。
https://github.com/iambyd/text_classification_lstm_attention
5.总结和展望
本次关于 Attention 的推文仅作为一个入门的介绍。后期主要介绍 Self-Attention ,以及 Google 的 bert 模型的理论和具体应用。
参考文章
[1] 张俊林 深度学习中的注意力机制(2017 版).
[2] Kelvin Xu,Jimmy Lei Ba,Ryan Kiros,Kyunghyun Cho,Aaron Courville,Ruslan Salakhutdinov,Richard S. Zemel,Yoshua Bengio. Show, Attend and Tell Neural Image Caption Generation with Visual Attention.
[3] Ilya Sutskever,Oriol Vinyals,Quoc V. Le. Sequence to Sequence Learning with Neural Networks.
[4] Dzmitry Bahdanau,KyungHyun Cho,Yoshua Bengio. NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE.
[5] Jader Abreu, Luis Fred, David Macêdo, and Cleber Zanchettin . Hierarchical Attentional Hybrid Neural Networks for Document Classication.
[6] Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit,Llion Jones,Aidan N. Gomez,Łukasz Kaiser,Illia Polosukhin.Attention Is All You Need.
[7] https://github.com/iambyd/text_classification_lstm_attention
本文转载自公众号:数据天团,作者丁永兵
推荐阅读
AI界最危险武器 GPT-2 使用指南:从Finetune到部署
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
Transformer (变形金刚,大雾) 三部曲:RNN 的继承者
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





