
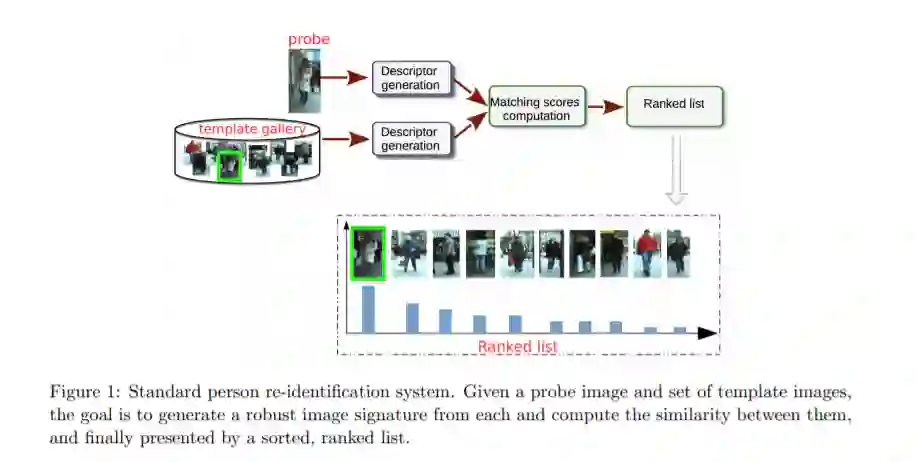
智能视频监控(IVS)是当前计算机视觉和机器学习领域的一个活跃研究领域,为监控操作员和取证视频调查者提供了有用的工具。人的再识别(PReID)是IVS中最关键的问题之一,它包括识别一个人是否已经通过网络中的摄像机被观察到。PReID的解决方案有无数的应用,包括检索显示感兴趣的个体的视频序列,甚至在多个摄像机视图上进行行人跟踪。文献中已经提出了不同的技术来提高PReID的性能,最近研究人员利用了深度神经网络(DNNs),因为它在类似的视觉问题上具有令人信服的性能,而且在测试时执行速度也很快。鉴于再识别解决方案的重要性和广泛的应用范围,我们的目标是讨论在该领域开展的工作,并提出一项最先进的DNN模型用于这项任务的调查。我们提供了每个模型的描述以及它们在一组基准数据集上的评估。最后,我们对这些模型进行了详细的比较,并讨论了它们的局限性,为今后的研究提供了指导。
成为VIP会员查看完整内容
相关内容

Arxiv
3+阅读 · 2019年2月26日
Arxiv
6+阅读 · 2018年3月8日

相关VIP内容
相关资讯