王的机器带你学 MIT 深度学习导论课

上个星期五看了「专知」推荐的这门课,我一看了只有 6 节,二话没说把 youtube 视屏设置 1.5 倍的语速,用了两天学完了全套。作为深度学习方法的官方入门课程,它内容讲的不是很深,但比较广,而且新,课件做的美,我自己听完后,是强烈想向那些想入门深度学习的同学推荐的。
为了对读者负责,我推荐的课都是我亲自上过的,比如之前的
都是我在 Coursera 买的上完拿到证书并觉得不错才推荐给大家的。今后我也会刷更多的课程 (现在正在上 MIT 和 Stanford 的几门),上完后写个总结贴并分享给大家。
好了言归正传,这门课讲深度学习以及它在序列建模、计算机视觉、生成模型,和强化学习中的应用。在我即将出版的书中也提到 (spoil alert 
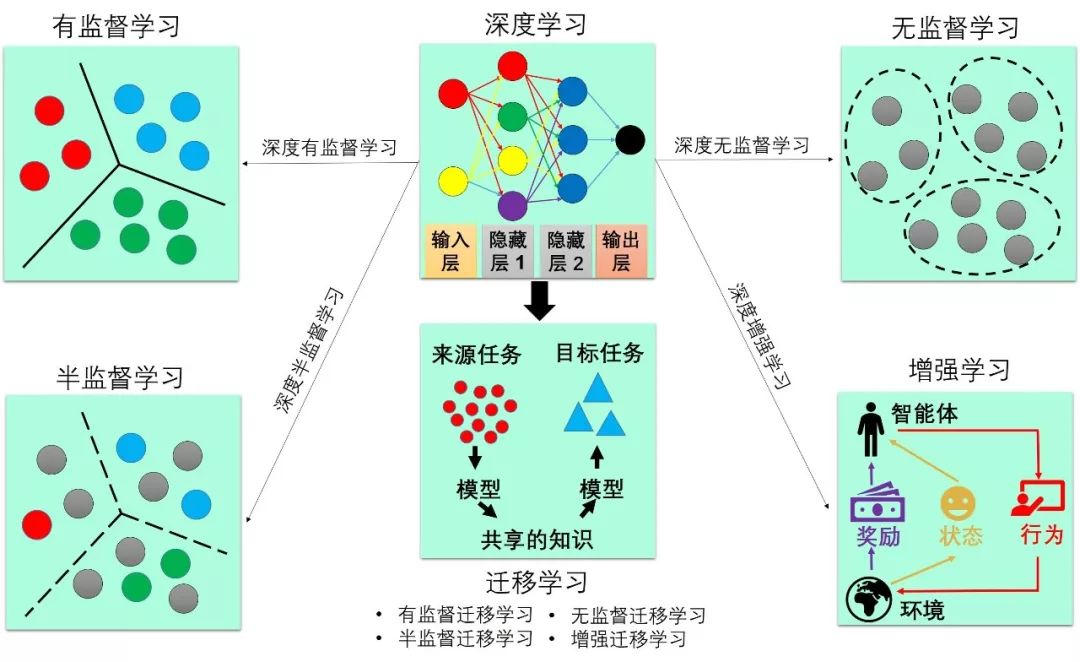
回到该课程,它的主要内容有
深度学习简介 (Introduction to DL)
深度序列建模 (Deep Sequence Modeling)
深度计算机视觉 (DL in CV)
深度生成模型 (Deep Generative Models)
深度强化学习 (DRL)
局限和前沿 (Limitations and Frontiers)

下面我给大家总结下每节课中最精华的部分,如要了解更多细节,下载本文给的课件材料并翻墙去看 Youtube 的视屏。
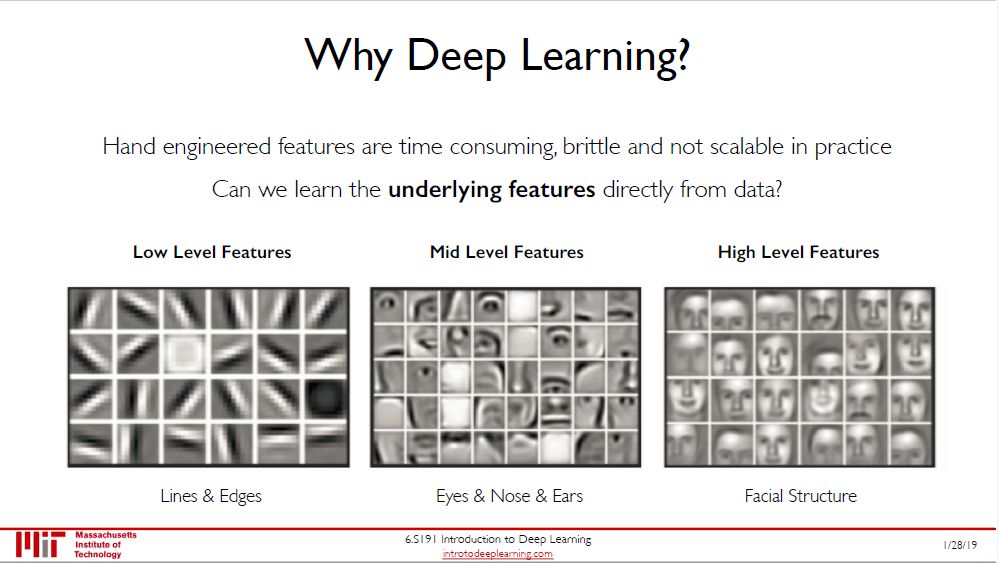
为什么要学深度学习?可以自动学到特征 (而不想传统机器学习要手工生成特征)!以人脸识别应用来说,卷积神经网络可以自动学到
低层特征比如线、边等
中层特征比如眼睛、鼻子、耳朵等
高级特征就是不同的人脸
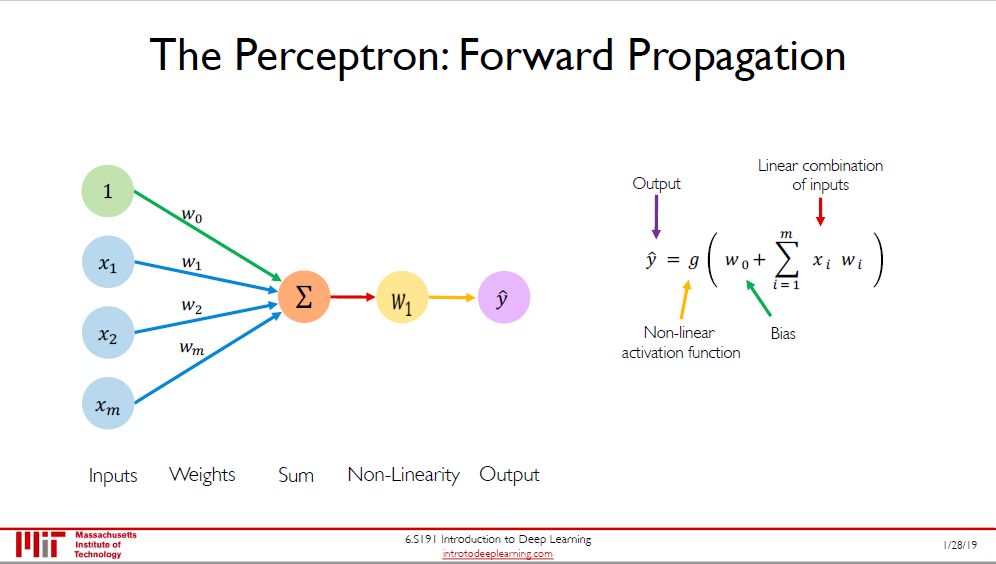
感知机 (perceptron) 是神经网络的极简形式,从输入到输出需要以下三个过程:
加总每个输入 (input) 和权重 (weight) 的乘积
加上偏置 (bias)
用转换函数 (transfer function) 得到输出 (output)
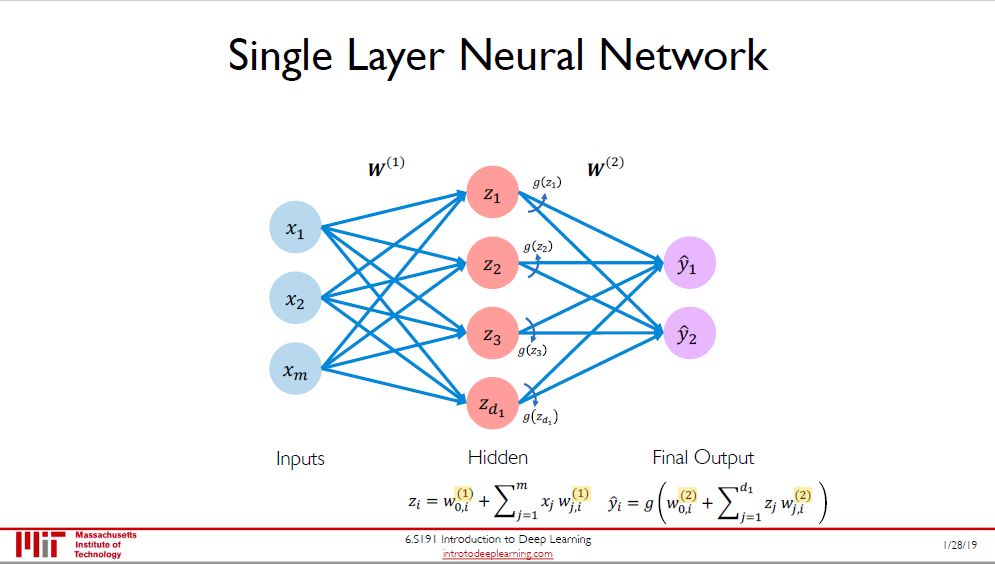
多加一个隐藏层 (hidden layer),单输出变成多输出,那么感知机就变成单层 (single layer) 神经网络了。多层 (multiple layer) 神经网络 (这里没画出来) 就是不断增加隐藏层。

计算出输出有什么用?当然要和真实标签 (true label) 比较,两者差异就叫做损失,专业术语是经验损失 (empirical loss)。上面计算的是单个数据的损失,全部加总再求平均得到总体损失 (total loss)。
我看了很多关于对损失 (loss),代价 (cost),误差 (error) 函数的解释,最喜欢用的惯例还是:
当描述单数据的误差时,用「损失函数」字眼
当描述多数据的误差时,用「代价函数」字眼
不想区分时,就用「误差函数」字眼
根据实际问题,损失主要可分为两类
回归问题的均方误差 (mean-square-error, MSE)
分类问题的交叉熵 (cross-entropy, CE)

定义完损失之后,当然要最小化它,核心方法 (当然还有很多变种) 就是梯度下降法 (gradient descent, GD)。而该方法的核心当然就是算出梯度,即误差函数 J 对所有参数 W 的偏导数。
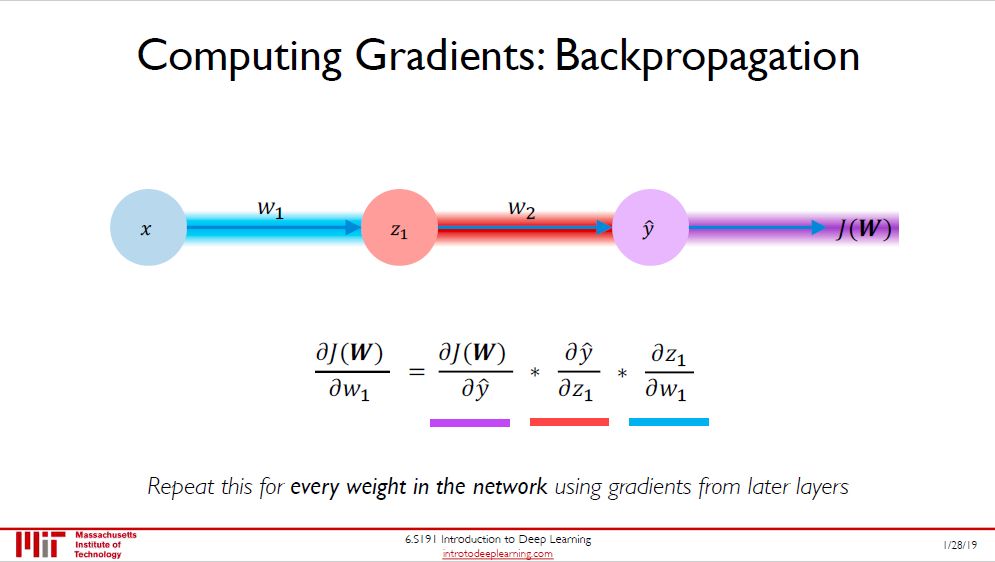
计算梯度有笨方法 (耗时) 和聪明方法 (省时),而反向传播 (backpropgation) 就是后者。说白了就是张量版的链式法则,充分利用已经算好的偏导数来计算新的偏导数。要深刻了解反向传播可参考我的帖子「人工神经网络之正反向传播」。

现实中神经网络的损失函数非常吓人,用单纯 (vanilla) 的梯度下降很难找到最优解。有几个自适应学习率 (adaptive learning rate) 的算法技巧可以克服这个困难:
Momentum
RMSProp
Adagrad
Adadelta
Adam
业界现在用的最多的是 Adam。
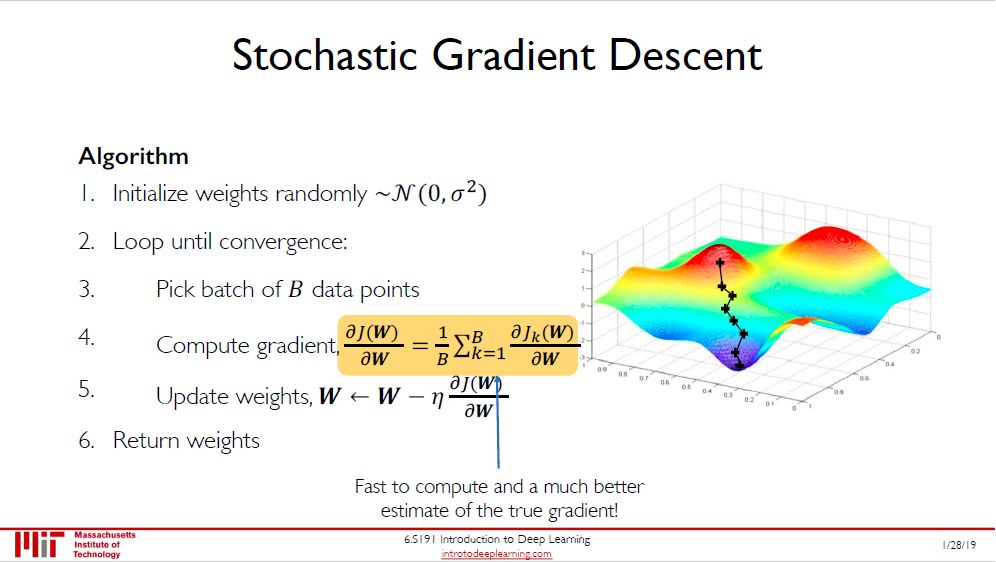
有了好的算法,我们发现在梯度下降 (GD) 中,更新一次参数需要在所有数据上做计算。深度学习中的数据有的上百万,这样做需要算力太惊人了。
换一个思路,用所有数据太慢,那么用单个数据,这种方法叫做随机梯度下降 (stochastic gradient descent, SGD),好处是快,坏处是不稳定。
把两者综合下,既不用所有数据,又不用单一数据,用一批数据怎么样?这种方法叫做小批量梯度下降 (mini-batch gradient descent, MBGD),每个 batch 里面的数据个数就是图中的 B。MBGD 在速度和稳定度综合来看比 GD 和 SGD 要好。
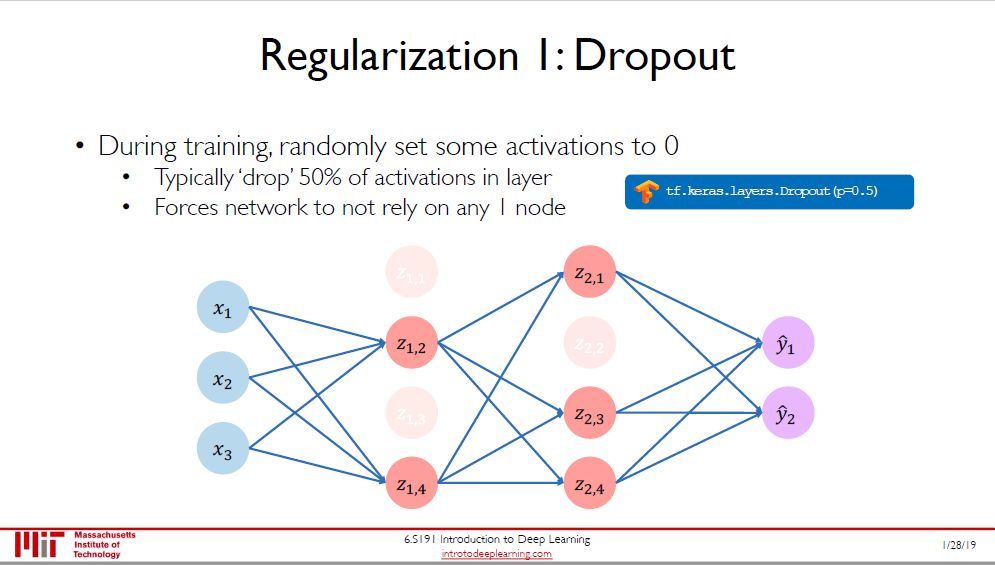
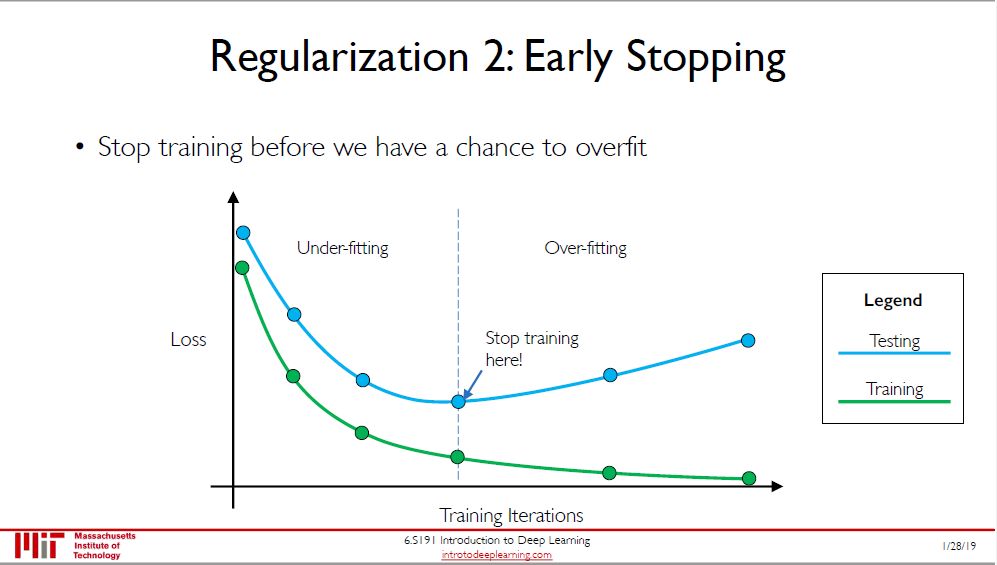
过拟合是机器学习 (深度学习) 中永远的问题,两个方法来减少过拟合:
Dropout (实在没找到合适的翻译)
提前终止 (early stopping)
Dropout 的思路是每次随机的断开某些神经元之间的连接,目的是想让剩余的少量神经元能更好地合作,希望能提高神经网络的推广能力 (generalization)。
提前终止这种方法很直观,在训练过程中观察训练误差和验证误差 (上图里说测试误差,我觉得不对),当验证误差随着训练次数增加而增大时,可以提前终止训练。


序列型数据最典型的是语言 (audio) 和文字 (text),当然还有金融里面的时间序列 (time series)。本节以文字举例,通常问题是给几个单词让你预测下一个单词是什么。比如
我生在中国,现定居美国,说一口流利的____
一个好的模型应该预测在空白处应填的词是「中文」。
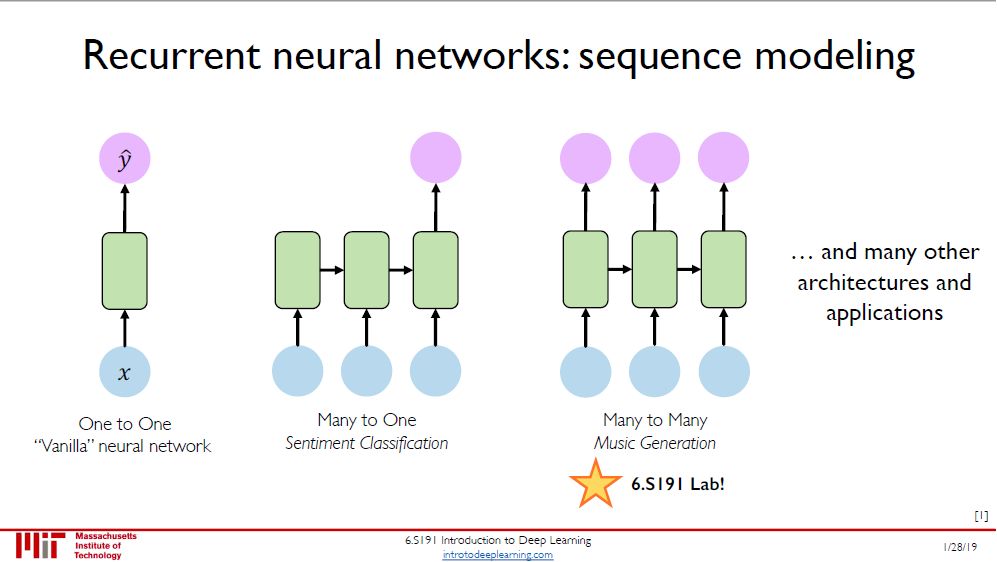
循环神经网络 (recurrent neural network, RNN) 天生就适用于对序列型数据建模。其实 RNN 根据输入和输出个数可分为五类,如下图 (来自 Andrej Karpathy)。因此本课 RNN 的分类不是很齐全。
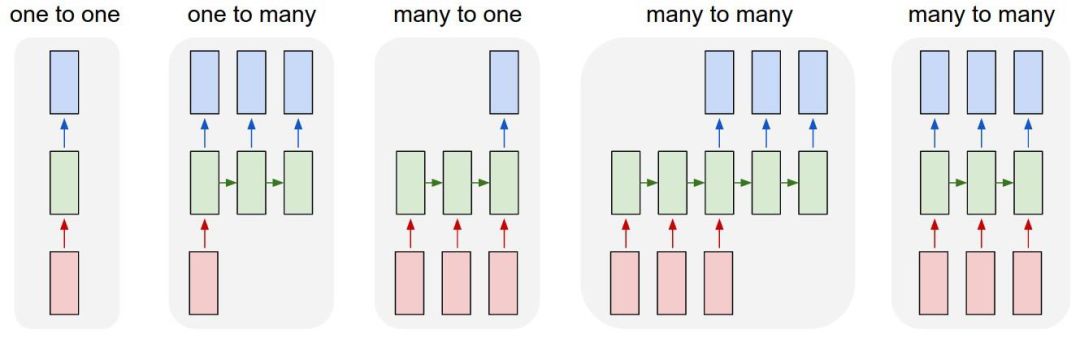
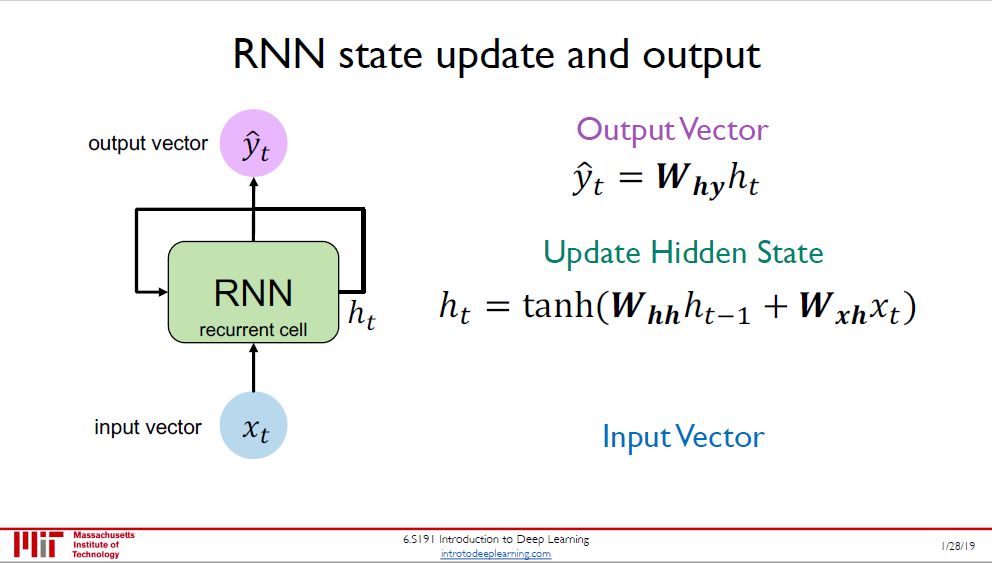
图右是一个 RNN 单元 (绿色矩形),输入 x(t) 进,输出 y(t) 出,更关键的是隐变量 h(t) 进进出出,以一种循环的方式。在时点 t 时
新隐变量 h(t) 是旧隐变量 h(t-1) 和输入 x(t) 的函数,外面再套个 tanh,参数为 Whh 和 Wxh
输出 y(t) 是 h(t) 的一个线性转换,参数为 Why
这些参数 Whh, Wxh, Why 在不同时点上是共享的。
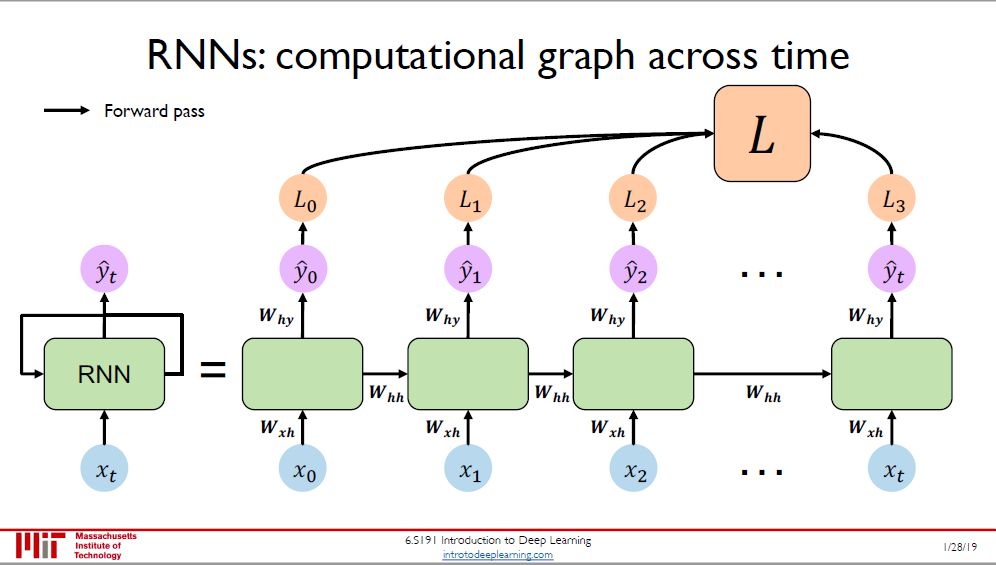
本图将 RNN 单元展开 (unroll),在每个模块中生成 y(t), 沿着时间维度上加总得到损失 L。当然这只是对单个数据而言,对多个数据还要在样本维度上再加总一次。
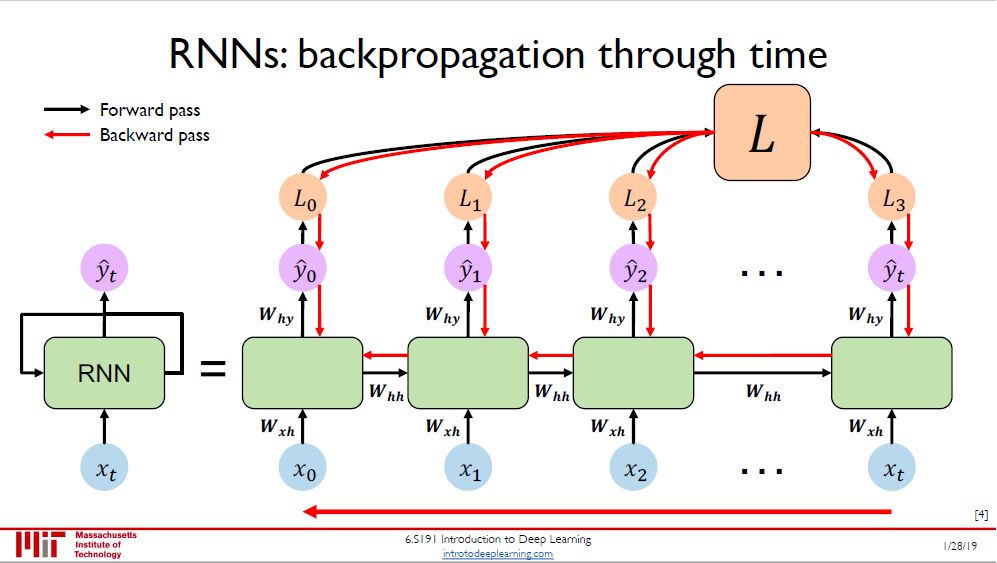
由于 RNN 里面参数沿着时间轴是共享的,那么在每个时点的损失都和 Whh, Wxh, Why 有关,根据链式法则推出的反向传播也沿着时间轴反向进行。
之后写到 RNN 时,我会详细推导「沿着时间的反向传播」(backpropogation through time, BPTT),比全连接神经网络的反向传播还要简单些,有兴趣的读者可以先看看我写的「张量求导和计算图」先预预热。

但是普通的 RNN 有个问题,就是没有长期的记忆。继续用刚才的例子
我生在中国,现定居美国,说一口流利的____
RNN 在填词时已经忘了前面距离很远的「中国」,而关注位置很近的「美国」,因此填的是「英文」而不是「中文」。
RNN 有这样的问题是在 BPTT 时梯度消失 (vanishing gradient) 了,可能连续相乘的偏导都很小,乘完梯度最后几乎为零。
新参数 = 旧参数 - 学习率×梯度
梯度等于零那还更新个什么参数?RNN 当然学不到东西了。有三个技巧可缓解梯度消失的问题:
用 ReLU 激活函数
用单位矩阵来初始化权重
用「门控单元」来代替普通 RNN 单元
第三个技巧提到的有门控单元 (gated cell) 的 RNN 有两种:
门控循环单元 (Gated Recurrent Unit, GRU)
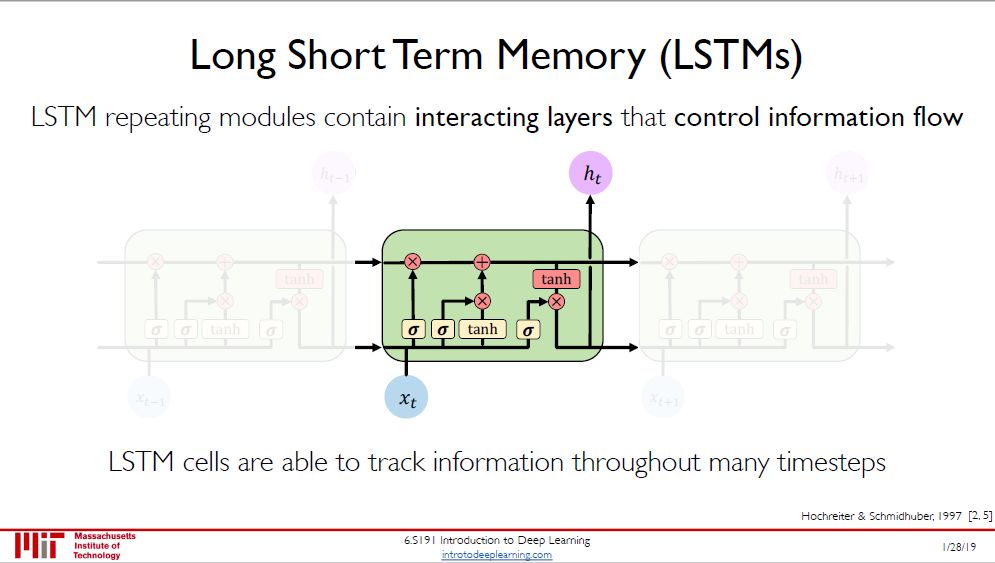
长短期记忆 (Long Short Term Memory, LSTM)
我们主要讲更为流行的后者,LSTM。它主要由四个小部分组成,下面四图来对其一一解释。
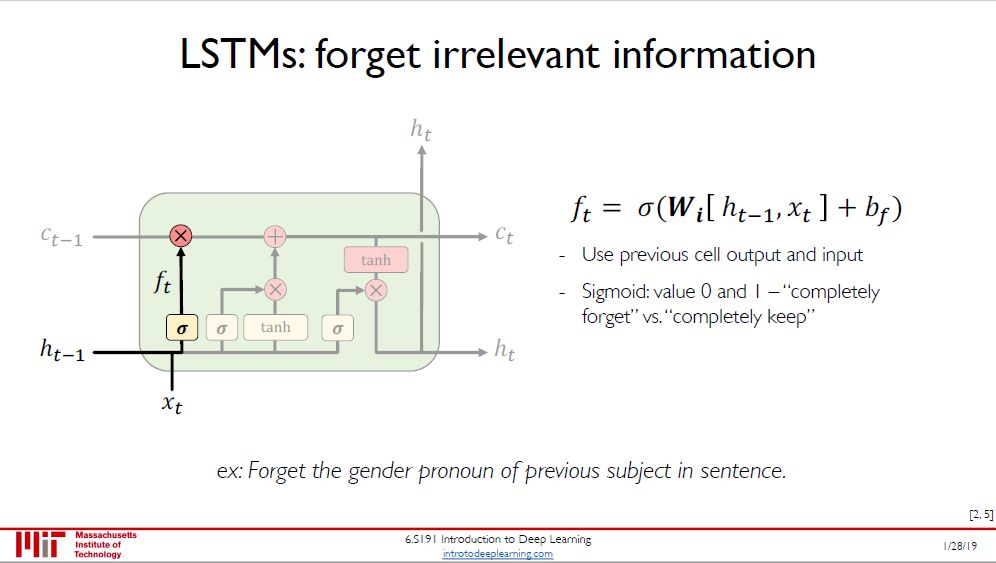
第一步:决定丢弃什么信息,这个操作由一个「忘记门」来完成。该层读取当前输入 x(t) 和前神经元信息 h(t-1),通过 sigmoid 函数 σ ,得到 f(t) 来决定丢弃的信息,输出结果为
1 表示完全保留
0 表示完全舍弃
在语言模型的例子中,通过此步可以忘记句子之前主要的性别代名词。
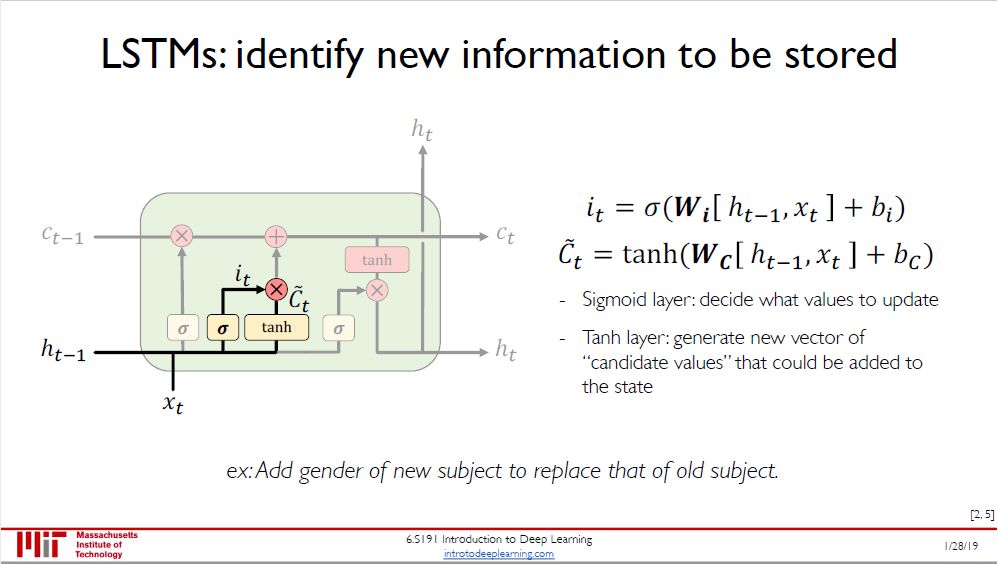
第二步:是确定所存放的新信息,分两步进行:
sigmoid 函数作为「输入门」,决定要更新的值 i(t)
tanh 函数来创建一个新的候选值 ~C(t) 加入到状态中
在语言模型的例子中,通过此步可以将新主语的性别替代旧主语的性别。
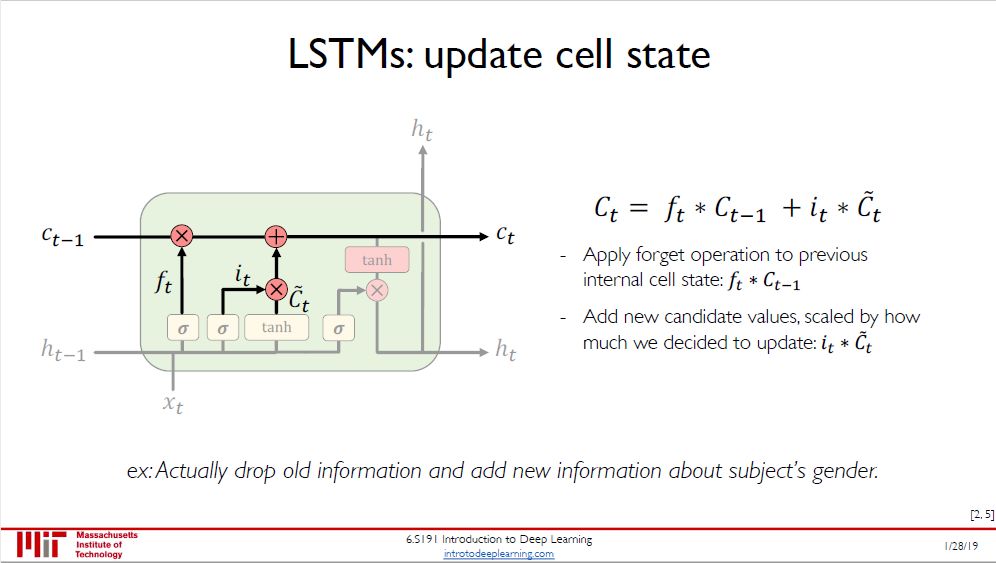
第三步:更新细胞状态,将 C(t-1) 更新为 C(t),分两步进行:
把旧状态 C(t-1) 与丢弃值 f(t) 相乘,丢弃掉确定需要丢弃的信息
接着加上 i(t) ⊗ ~C(t) 得到新的候选值
在语言模型的例子中,此步根据主语性别来丢弃旧信息并添加新信息。
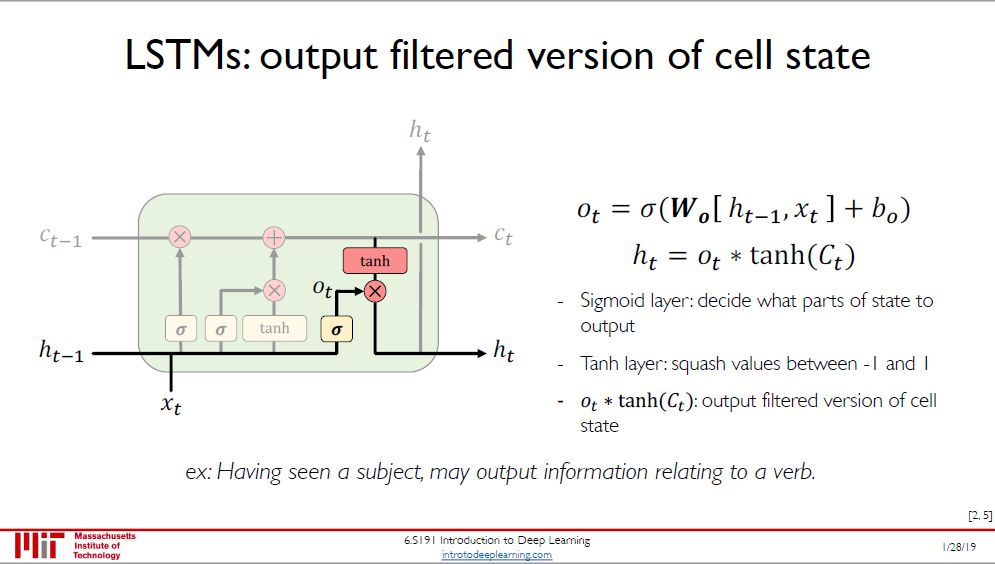
第四步:确定输出,分两步进行:
用 sigmoid 函数来确定细胞状态的哪个部分将输出出去,得到 o(t)
再用 tanh 函数处理新状态 C(t) 并和 o(t) 相乘,仅会输出我们确定输出的那部分
在语言模型的例子中,比如输出判断是一个动词,那么需要根据主语代词是单数还是复数,确定动词的词形。
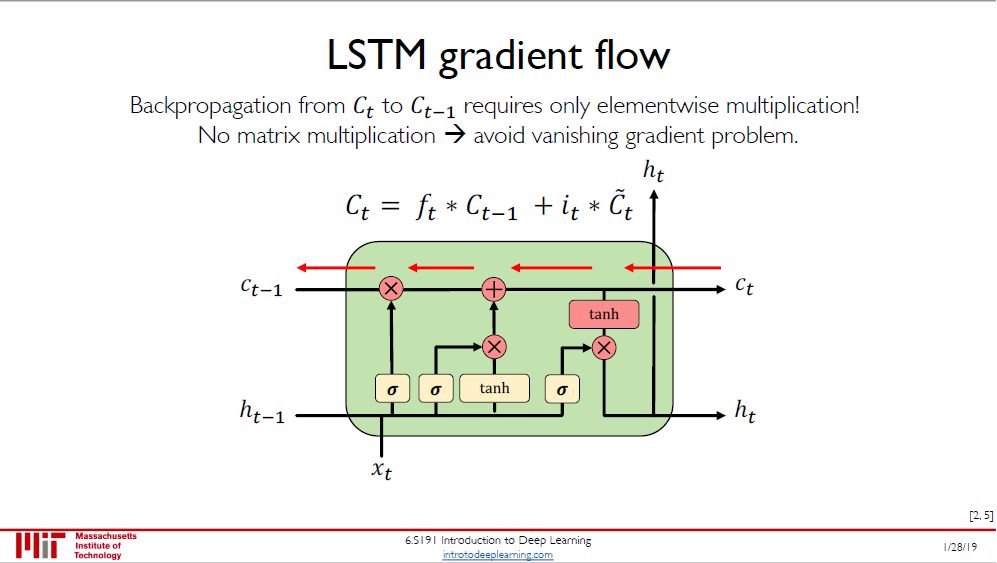
LSTM 更新状态 C(t) 时都是通过点乘 (而不是矩阵乘法),因此避免了梯度消失的问题。
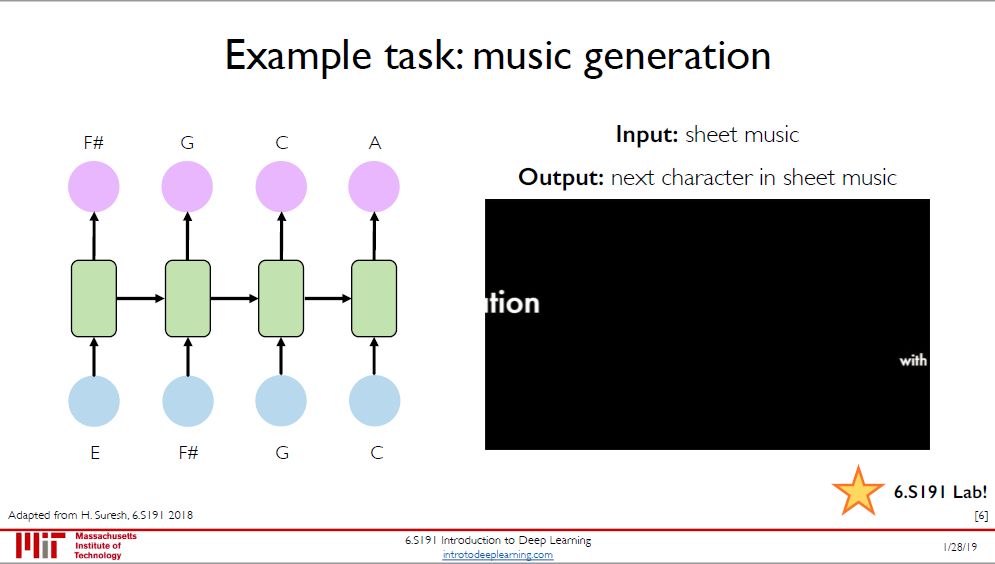

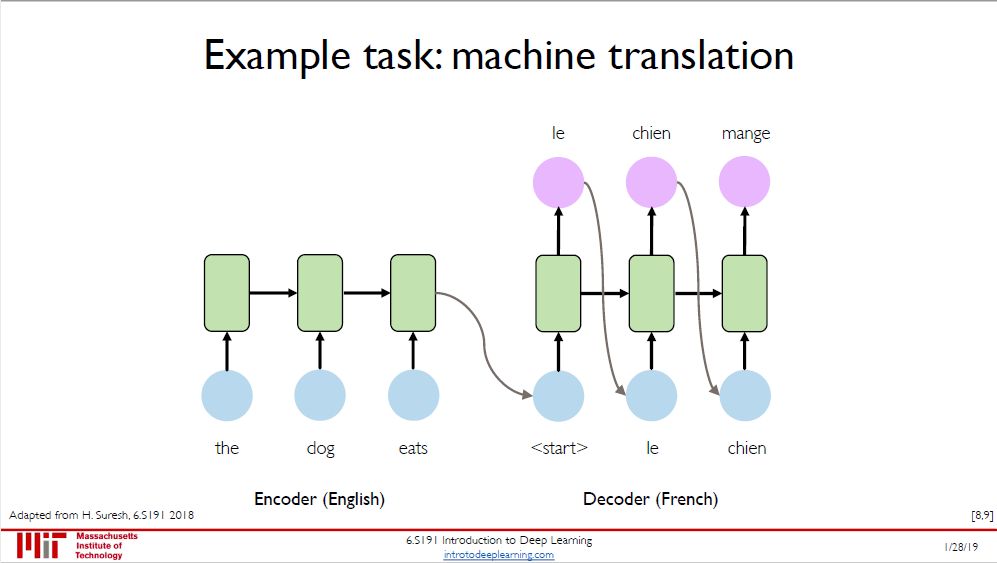
RNN 的三大应用:
音乐生成:输入是一堆音符,输出是下一个音符
情感分类:输入是一句评价,输出是「好\坏」类别
机器翻译:输入是一国语言,输出是另一国语言
最后机器翻译用到了 encoder+decoder 是很常见的,更先进的还会带上注意力机制 (attention mechanism) 变成 Transformer 模型,想想 ELMo, ULMFiT, GPT, BERT ... 它们现在几乎把 RNN 在自然语言处理的位置取代了,但我们还是要从最基本的 RNN 开始学不是吗?

计算机视觉 (computer vision, CV) 里面处理最常见的数据类型是图片,图片是非结构化类数据,但每个像素其实就是 0 到 255 之间的一个数,因此
一张黑白图片就是一个 2 维数组
一张彩色图片就是一个 3 维数组
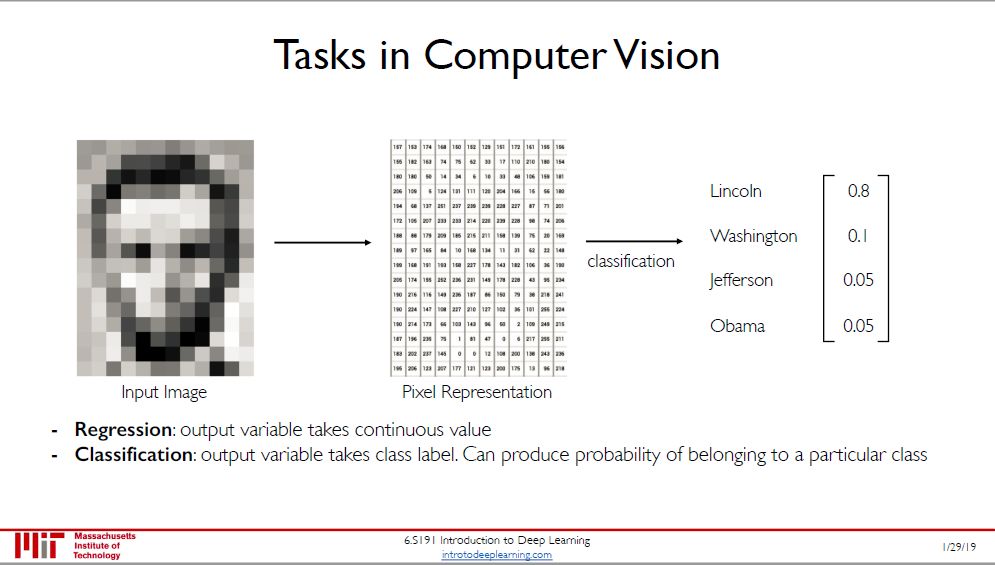
在 CV 分类任务中,我们用神经网络将「多维数组」的输入转换成「一维概率向量」的输出,哪个类别的概率值最大就分为那类。
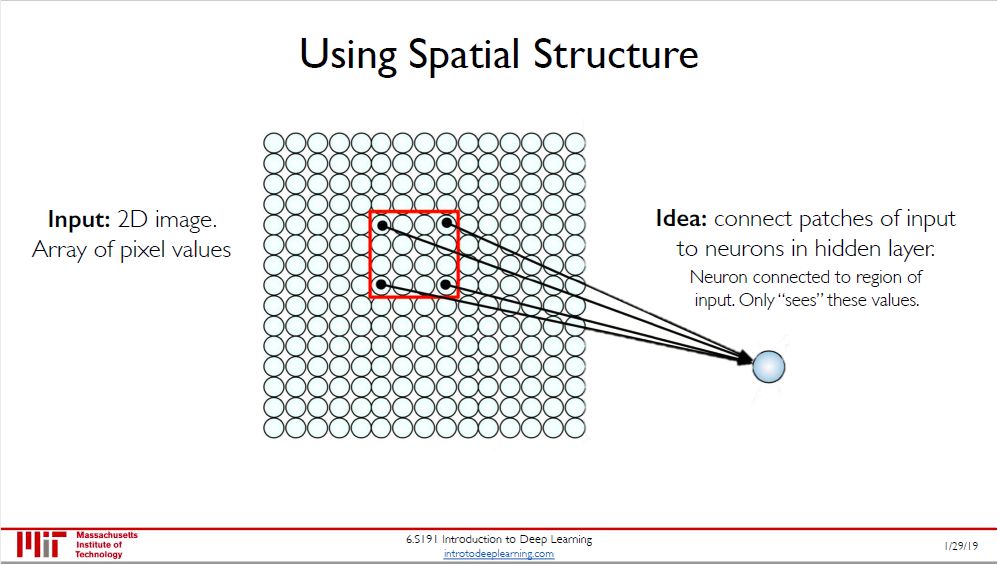
把这个蓝色球想成人眼,当我们看图片时目光锁定在某个红色框上。
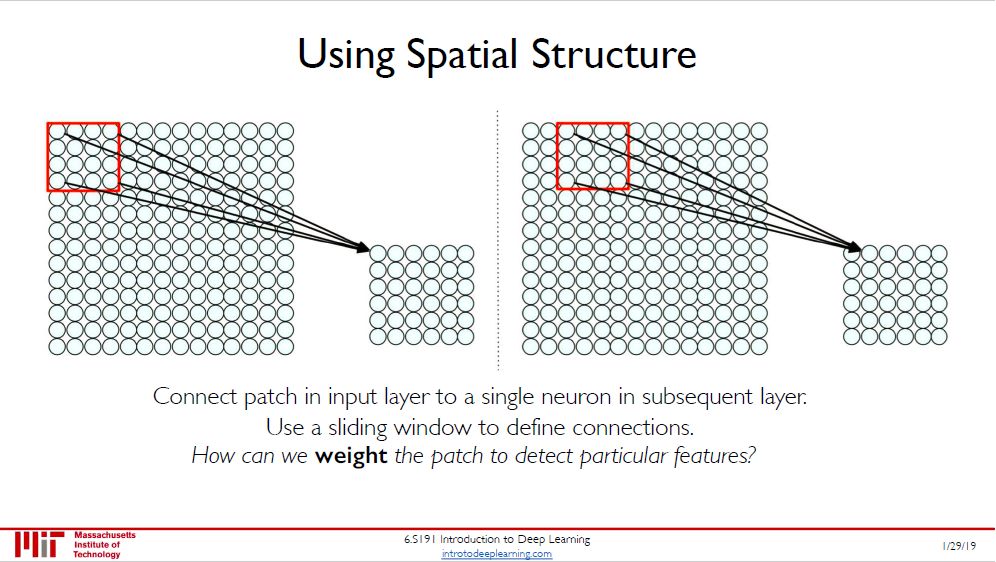
那要看完整幅图,必须要一帧帧扫过去啊,伴随的操作就是红色框一点点在移动。
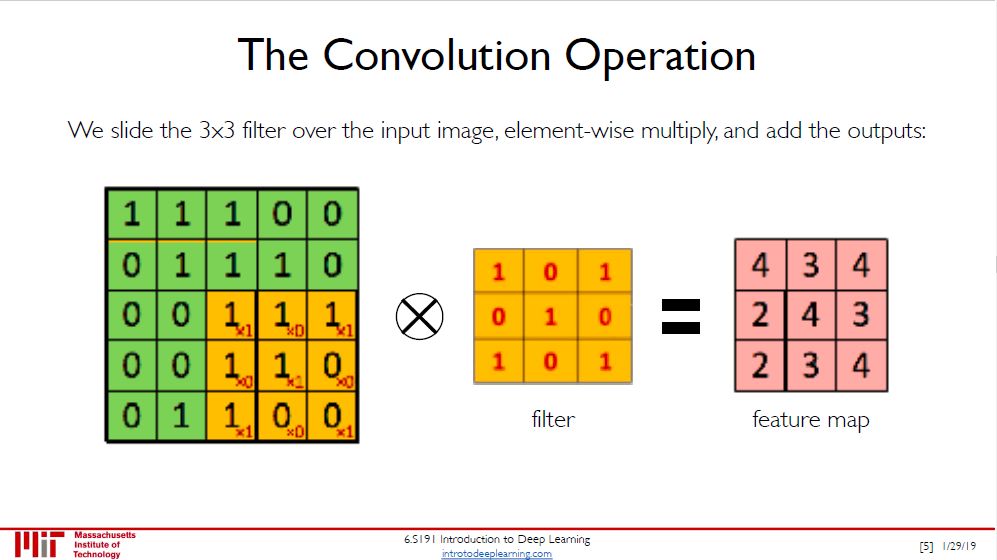
之前说了图片就是多维数组,将 0 到 255 值标准化成 0 到 1,像素 0 代表黑色,像素 1 代表白色,那么再看看这个滤器 (filter) 是不是代表是个白色 X 的样子。把滤器放在图片上一步步扫,每步就算出一个卷积值,那么
该值越大,扫的部分越像白色 X
该值越小,扫的部分越不像白色 X
卷积值计算也非常简单,就是滤器和被扫的所有数字点乘再加总,用上图举例
1×1 + 1×0 + 1×1
+ 1×0 + 1×1 + 0×0
+ 1×1 + 0×0 + 0×1 = 4
白色 X 只是一种滤器,你还可以想出黑色 X、黑色或白色竖线、黑色或白色横线等等的滤器。这些滤器可以帮助检测出图片中的线和边。
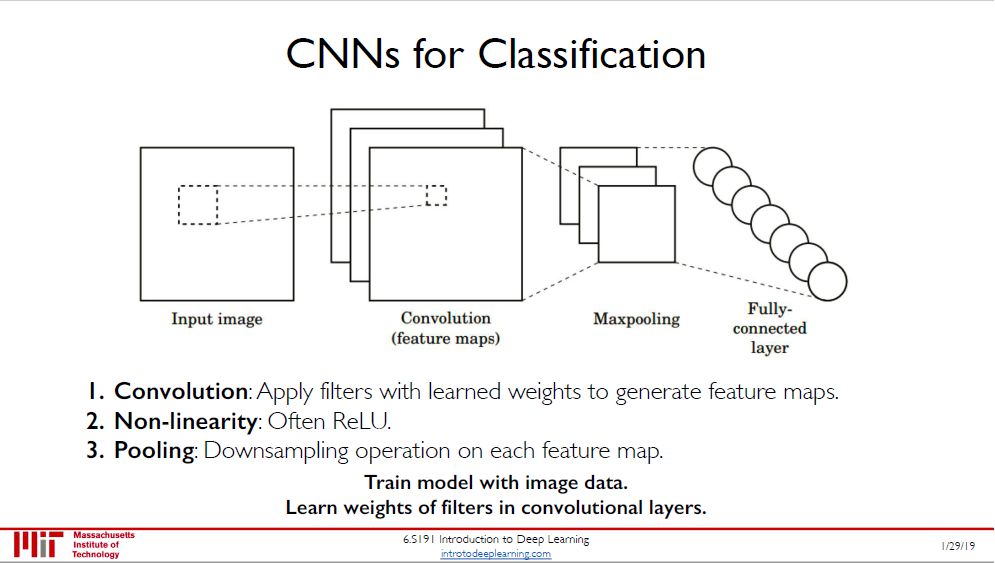
卷积神经网络 (convolutional neural network, CNN) 是由四个元素组成的:
卷积层 (convolutional layer)
非线性转换函数 (non-linear activation)
池化层 (pooling layer)
全连接层 (fully-connected layer)
通常元素 1-2-3 是相连的,CNN 中可能有好几个,而元素 4 是放在 CNN 最后若干层。
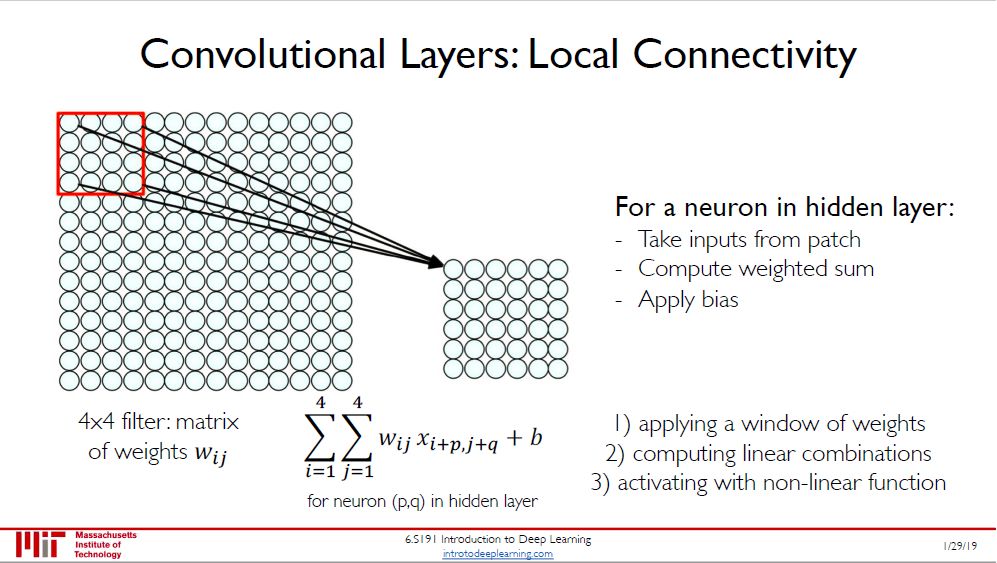
卷积层做的事就是用滤器扫过照片求卷积,每个滤器的参数在扫过整个照片的过程中是共享的。类比 RNN 的参数沿时间维度共享,CNN 的参数是沿空间维度共享。

非线性转换函数放在卷积层后面,这个和全连接神经网络一样,不停的做非线性转换,常见函数是 ReLU。
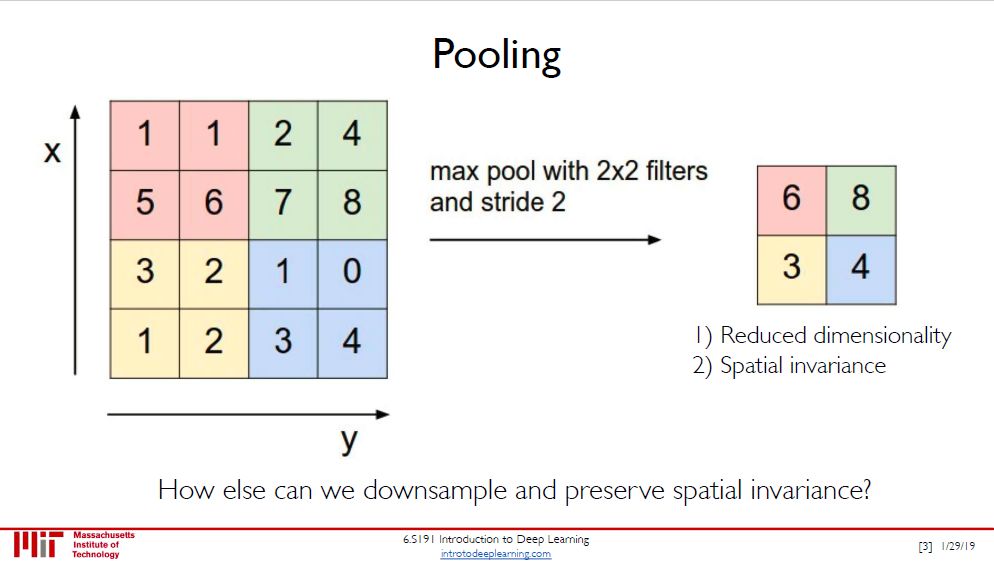
池化层主要是将图片变小并保存着最显著的特征。池化层分最大池化 (max pooling) 和平均池化 (average pooling),上图是前者,操作也非常简单,把过滤到的所有数取个最大值保存下来。
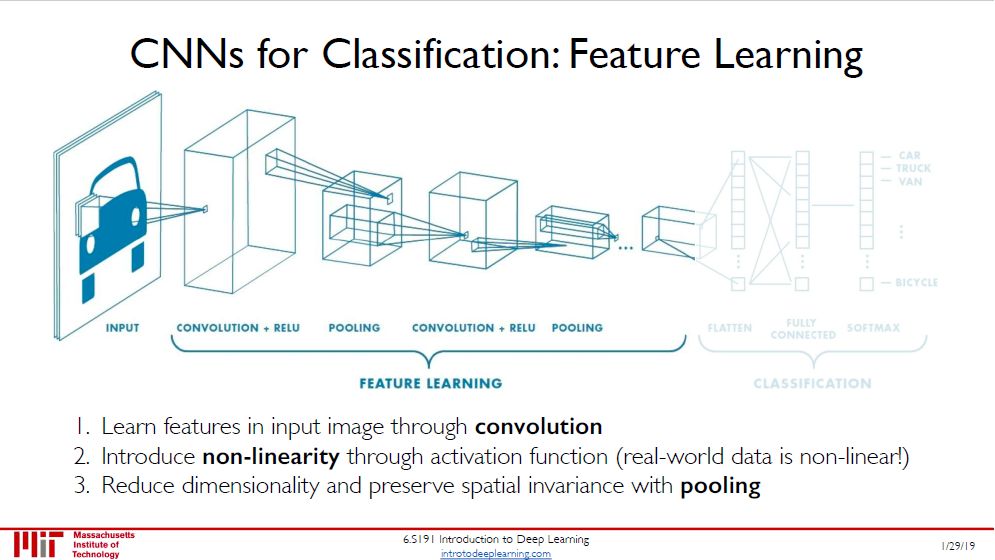
「卷积层 + ReLU + 池化层」做的事就是提取特征,从低层特征到高层特征。
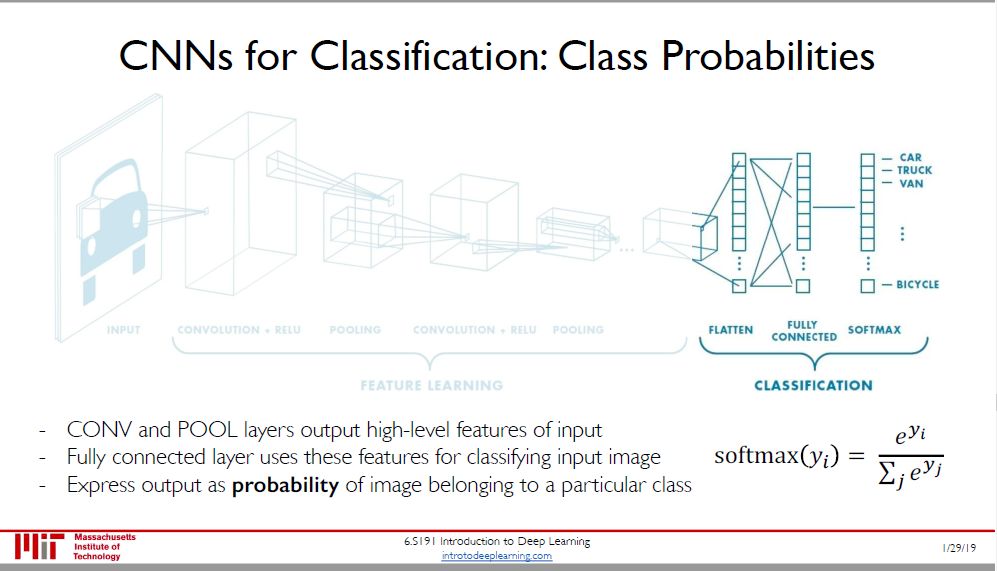
特征提取好后可以做很多事情,比如最常见的是「图像分类」,显然用全连接层来做这件事。
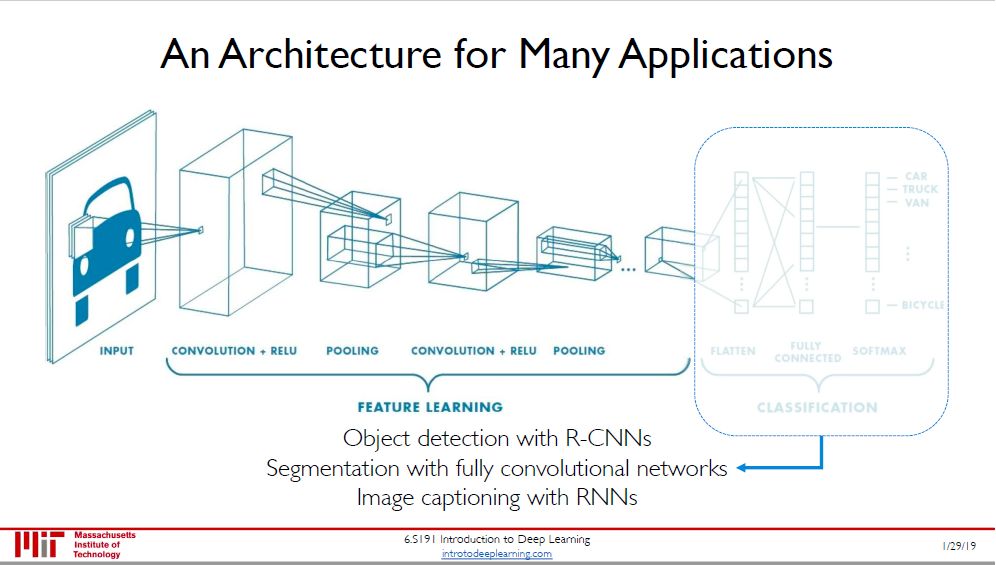
除了「图像分类」,CNN 还可以用提取好的特征做以下三件事:
语义分割 (semantic segmentation)
对象检测 (object detection)
看图说话 (image captioning)
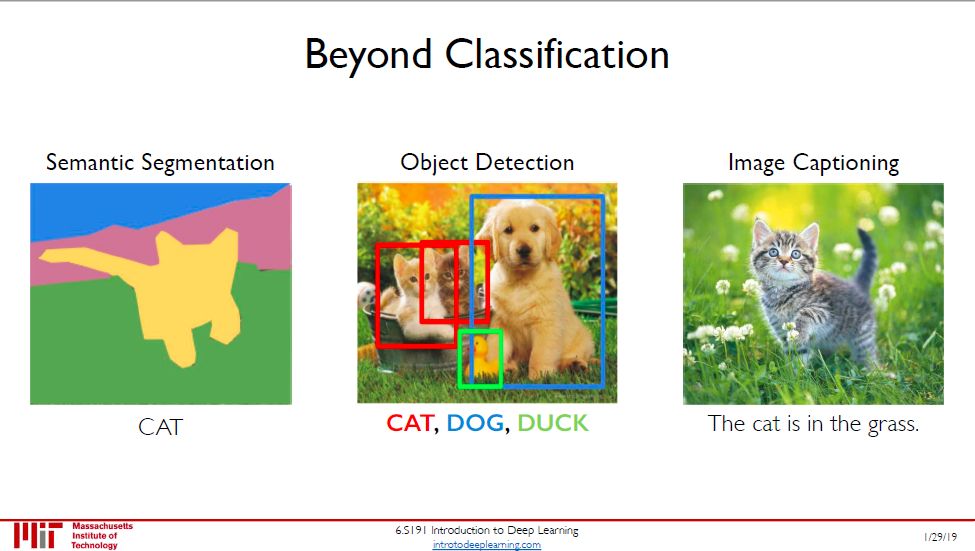
三个实例:
语义分割:从图像中分割出对象区域,并识别出示猫
对象检测:用方框找出两只猫、一只狗和一只鸭子。
看图说话:根据图片信息生成「猫在草丛中」

语义分割主要用卷积层下采样 (downsample) 和上采样 (upsampling),流行的模型如 SegNet。
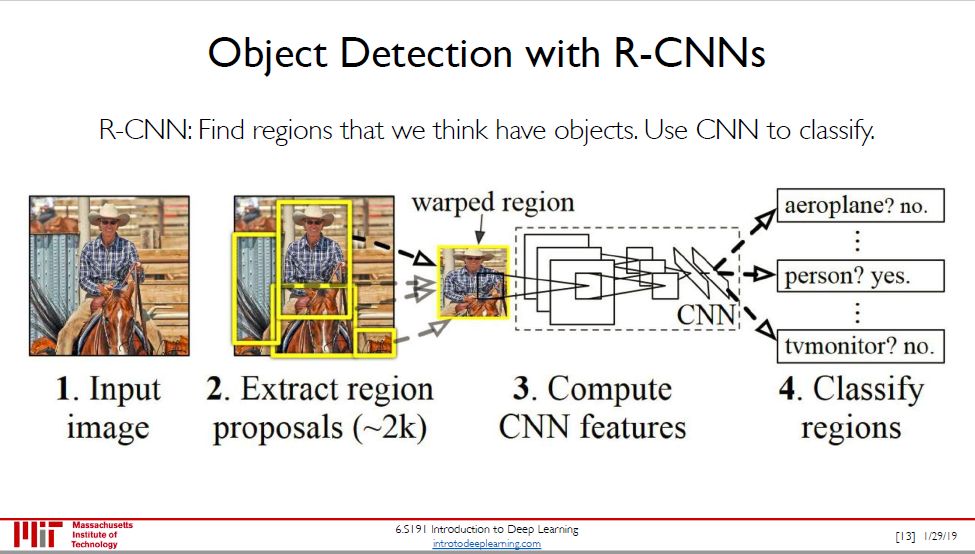
对象检测把定位和分类可以迭代起来,最终在一张图片汇总对多个对象进行检测和分类,流行的模型如 R-CNN 和 YOLO。
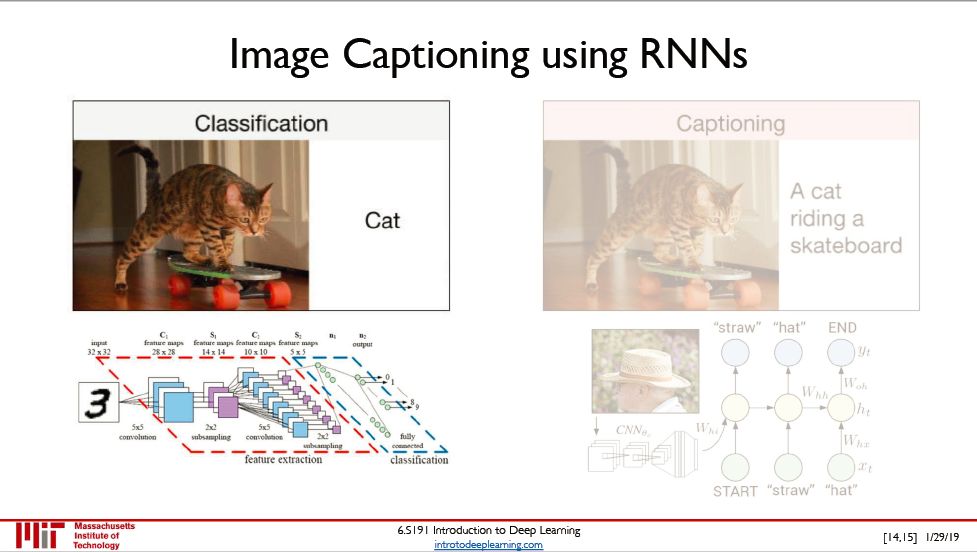

看图说话将图信息转换成文字,用 CNN 来处理图片,用 RNN 来生成文字。谷歌的这篇论文『Show and Tell: A Neural Image Caption Generator』了解一下。
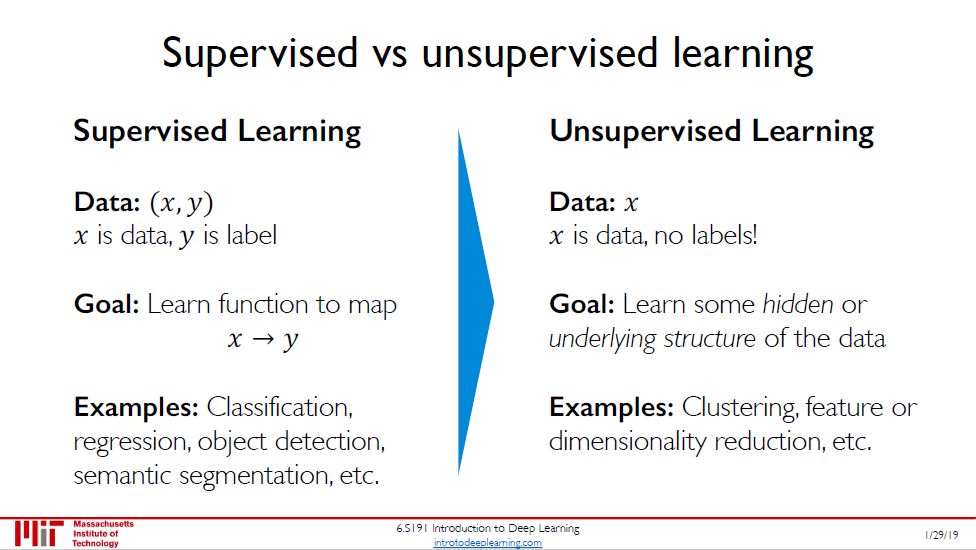
机器学习两大类:
有监督学习:数据 = (x, y),任务有分类、回归、对象检测、语义分割等。
无监督学习:数据 = x,任务有聚类、降维。
本节讲的是深度无监督学习。
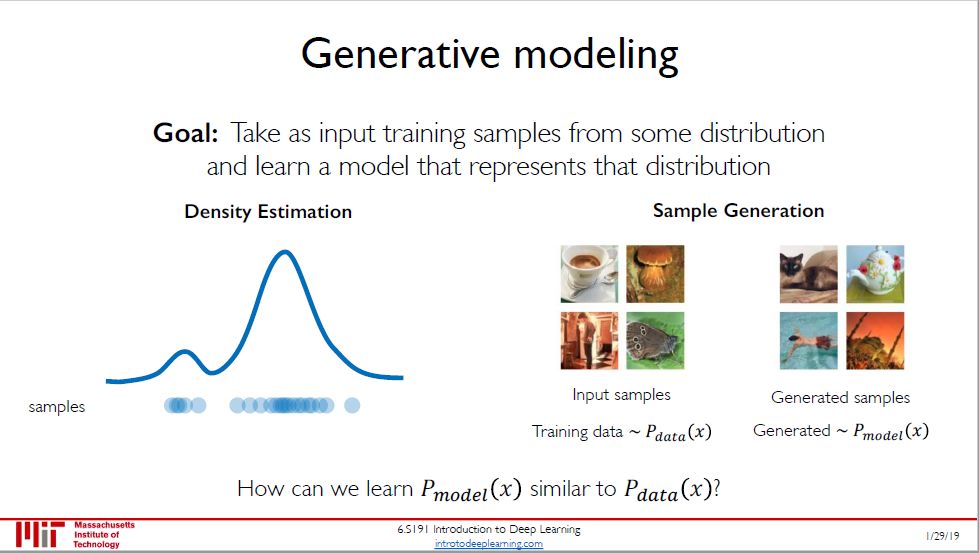
生成模型有两类:可以估计样本的概率分布密度,也可以直接对样本分布建模。
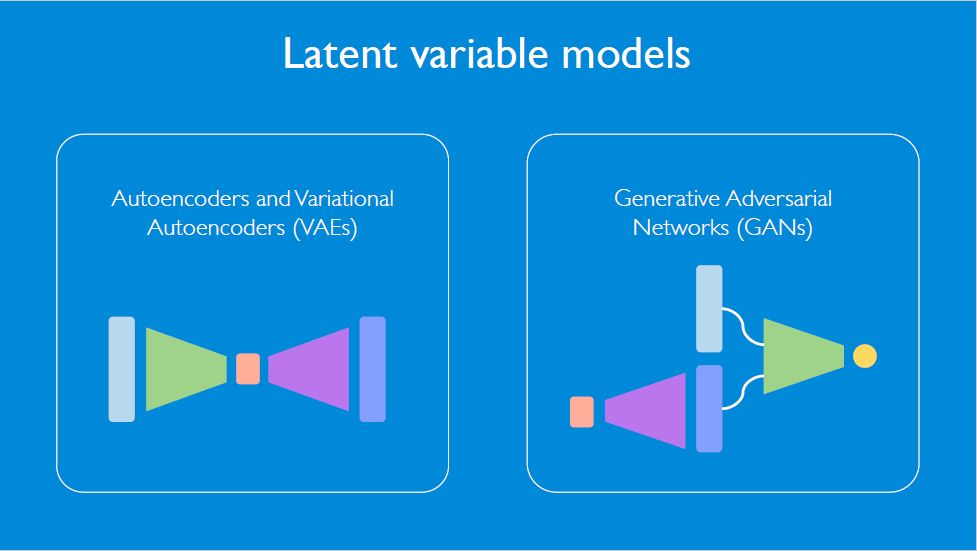
生成模型也可以叫做隐变量模型 (latent variable model),旗下两个有名的深度生成模型是
变分自编码器 (variational autoencoders, VAE)
生成对抗网络 (generative adversarial networks, GAN)

在统计里,隐变量是不可观测的随机变量,我们通常通过可观测变量的样本对隐变量作出推断。在上图中
那些法杖是隐变量,那些坐在墙边的奴隶看不到
那些法杖的影子是可观测变量,奴隶只能看到它们
奴隶只能靠影子来推测实物 (隐变量) 的样子。
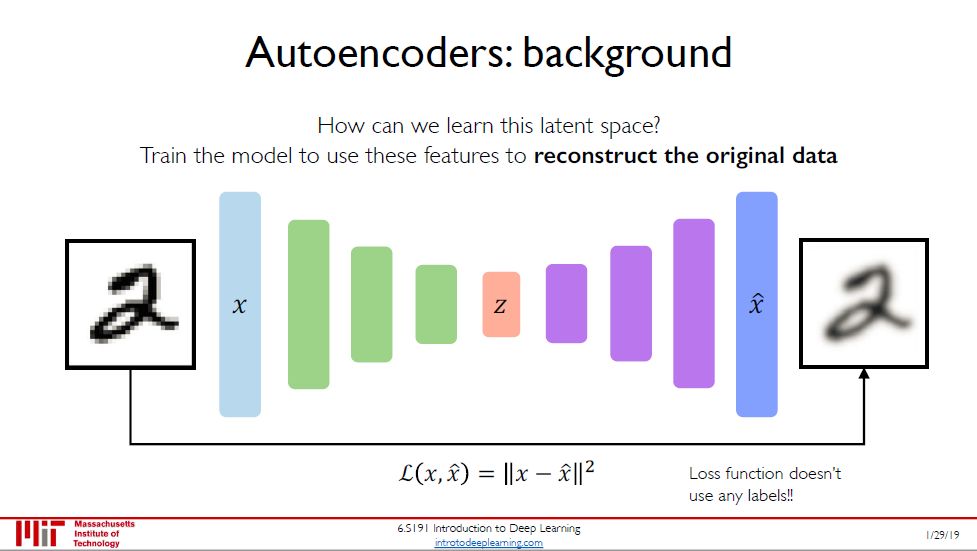
要理解变分自编码器 (VAE),首先需要了解自编码器 (autoencoder)。
自编码器是输出值等于输入值的神经网络,它没用到任何标签 (标签就是输入),因此是无监督学习下面的模型。它的核心理念分两步
觉得输入的特征维度太高,压缩成低维度表征,编码器 (encoder) 干的事
如果低维度表征够好,那么应该能重构出输入,解码器 (decoder) 干的事
损失函数定义成本身 x 和重构出来的 x 之间的误差。
自编码器只能将编码向量通过解码器映射到相应的输入。它当然不能用于生成具有可变性的相似图像。d上图中 2,自编码器只能生成和原来一样枯燥的 2,不能生成摆手弄姿的 2,不能生成旋转自如的 2。
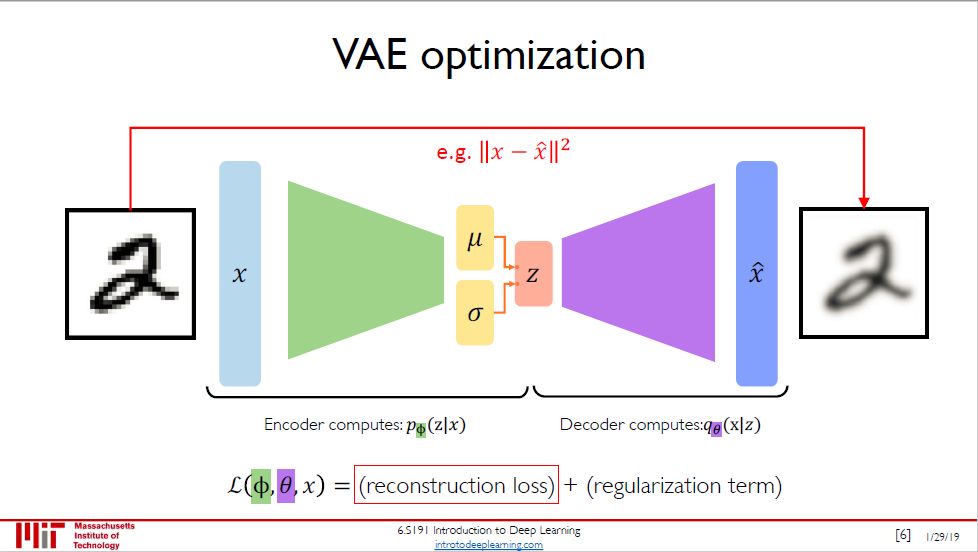
这些事变分自编码器 (VAE) 做的到。为了实现这一点,VAE 需要学习训练数据的概率分布,因此可以把 VAE 看成是在自编码器基础上加点「概率的料」,而做法就是在隐变量随机抽样,根据其均值向量 μ 和标准差向量 σ。
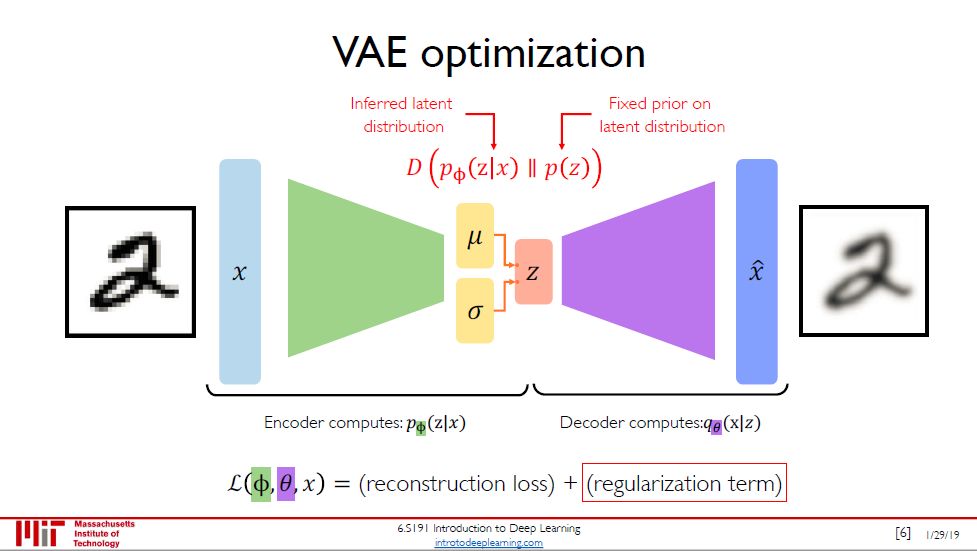
VAE 的损失由两部分组成,重构损失 (和自编码器里的一样) 加上正则项。正则项定义为
D(pΦ(z|x) || p(z))
其中
pΦ(z|x) 是隐变量后验分布,通过编码器计算得到 (Φ 是编码网络的参数)
p(z) 是隐变量先验分布,通常用标准正态分布表示
D(p || q) 是 KL 散度,度量两个概率分布 p 和 q 之间的差异
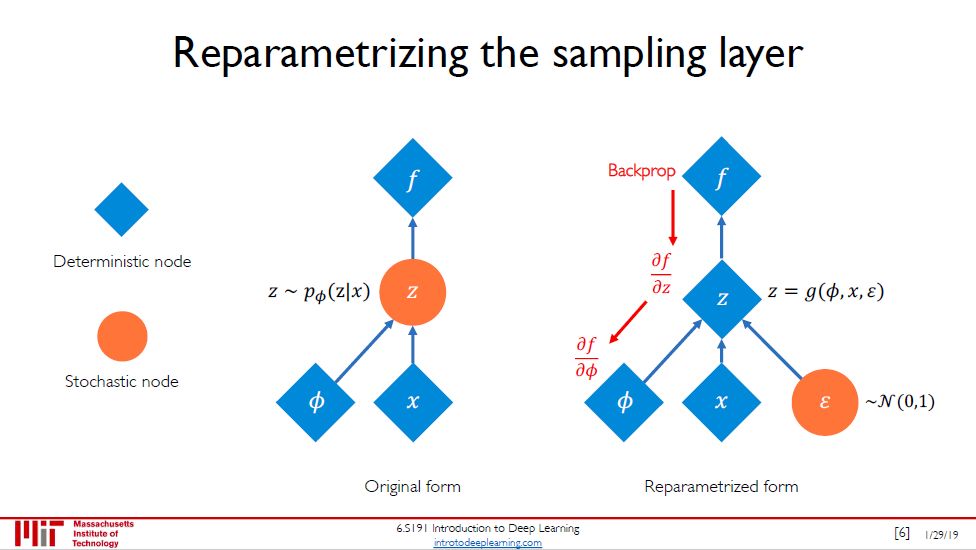
在 VAE,由于 z 是随机变量,直接反向传播是行不通的。这是可以重新参数化,把 z 看成 Φ, x 和 ε 的函数,其中 ε 是标准正态随机变量。
由图右可知,现在用反向传播来求 ∂z/∂Φ 和 ∂z/∂x 是可以的,虽然求 ∂z/∂ε 行不通,但是在实操上我们根本不需要这个偏导数。
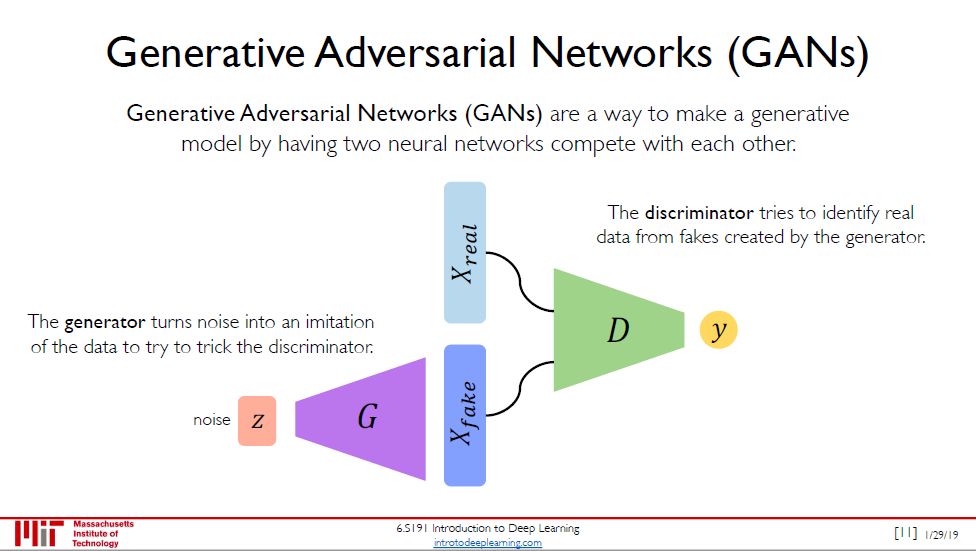
GAN and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion. -- Yann Lecun
GAN 不像 VAE 使用任何显式的密度估计,相反,它是基于博弈论 (game theory)的方法,目的是在两个网络,生成器 (generator) 和判别器 (discriminator) 之间的纳什均衡 (Nash equilibrium)。如上图所示:
生成器将杂讯输进数据里想要骗过辨别器
判别器从假数据中找出真数据
这样你来我往你追我赶的对抗中,生成器和判别器都越来越牛,生成器造假越来越炉火纯青,判别器打假越来越火眼金睛。直到判别器识别不出来真假的时候,生成器已经练成,可以造出高质量的假货了。

训练 GAN 就是一个 minimax 的游戏,定义
D 表示判别器
G 表示生成器
z 代表杂讯,概率分布 p(z)
x 是输入,概率分布 pdata
θd 是判别网络的参数
θg 是生成网络的参数
minimax 里面的目标函数比较复杂,以后再写 GAN 的帖子是再细说。粗略来说,将目标函数里 G 固定再求 max 就表示 pG 和 pdata 之间的差异,然后在找一个最好的 G 让这个最大值最小,即生成数据和真实数据的分布最小。
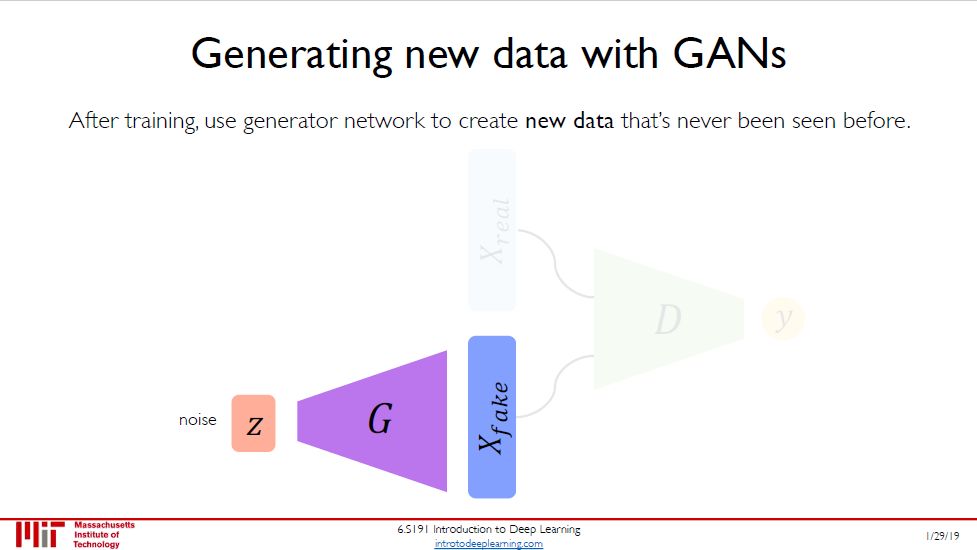
训练完后,丢弃判别器 (有点过河拆桥),保留生成器来生成数据了。
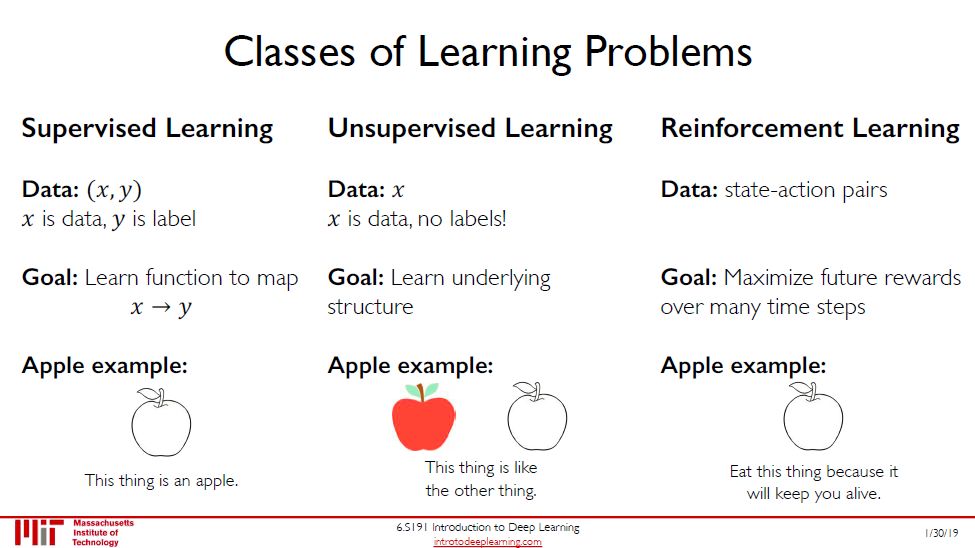
机器学习三大类:
有监督学习:数据 = (x, y)
无监督学习:数据 = x
强化学习:数据 = (x, grade)
本节讲的是深度强化学习。
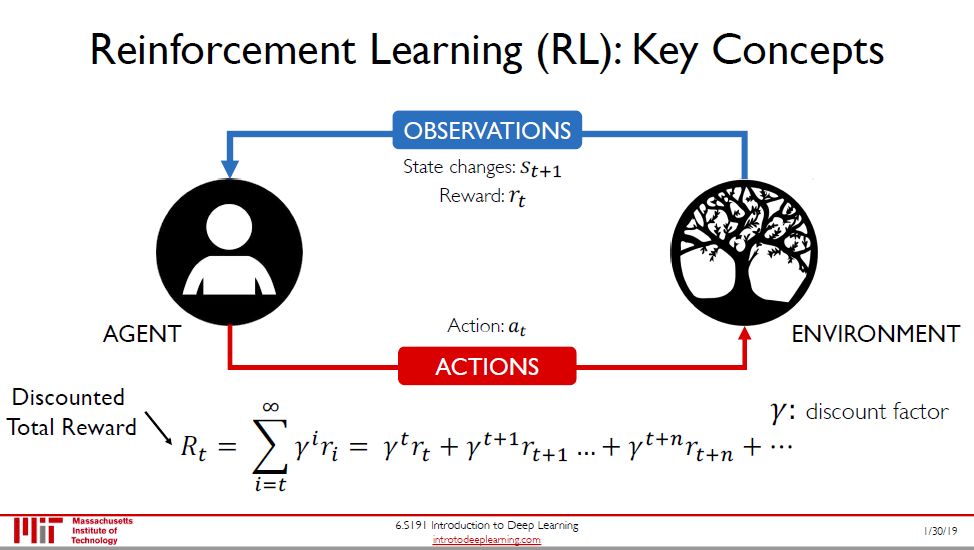
强化学习是在行动中学习,和有监督学习不同,它不需要输入和标签,而需要环境(environment) 对智能体 (agent) 在不同状态 (state) 下行为 (action) 的评价。环境、智能体、状态和行为就是强化学习的四大元素。
评价通常用回报表示,正回报就是奖励,负回报就是惩罚。为了体现回报的时间价值 (time value),我们会用一个小于 1 的折现因子对其打折。

动作值函数 Q 对于智能体而言,就好比人类的价值评判,它能根据智能体所处的状态 s 以及做相应动作 a 可以得到一个行为价值评分 (即总折现奖励的期望值),使智能体依据它的大小去选择实际采取的行动。
智能体要实现自主决策,必然会存在一个策略函数,定义为 π,它是状态 s 到行动 a 的函数,即 π(s) = a。在给定某个状态 s 时,智能体会采用最优行动 a*,而对应也是最优策略 π*(s)。

根据包不包含价值函数和策略可将 (深度) 强化学习两大类:
基于价值 (value-based) 学习,神经网络输出是 Q(s, a)
基于策略 (policy-based) 学习,神经网络输出是 π(s|a)
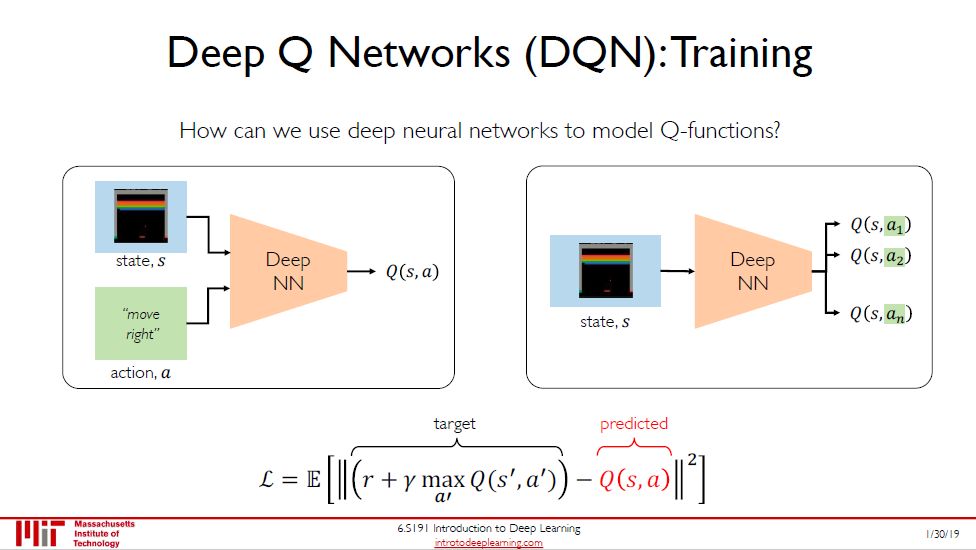
对于传统的强化学习,思路是通过计算最优值函数,从而求得最优策略 π*。而 DQN 是通过一些 CNN, RNN 和 FCNN,加上经验回放的技巧,将强化学习的问题转换成有监督学习问题 (见图底这个预测 Q 值和目标 Q 值之间的损失)。
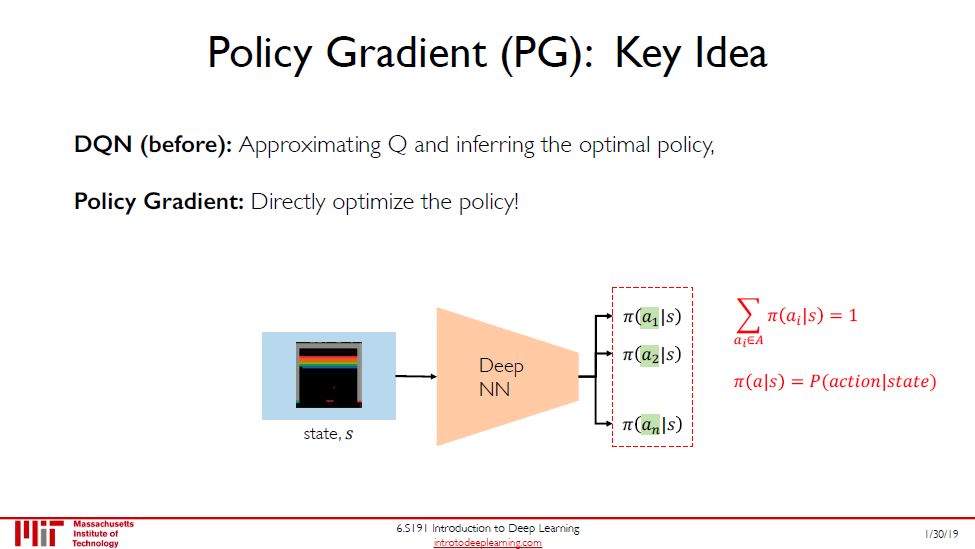
上一幅图的 DQN 是通过 Q 来间接推出最优策略,而本图中 DQN 是直接推出最优策略。既然已经有了基于值函数的方法,为何还需要有直接求最优策略的方法呢?因为更简单,而且最优策略本质就是个策略函数。
直接求策略函数的好处是可以减少对大量无关数据的储存,而且对于连续的动作空间,基于价值函数的方法也不适用。
没听懂。我没有什么 RL 基础,大牛们可以讲讲。
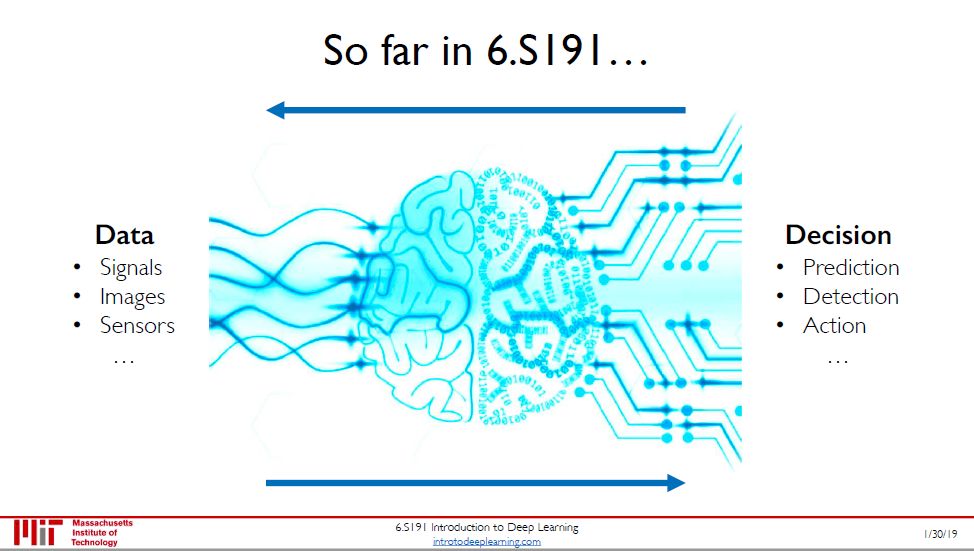
讲师极简方式总结了这门课教了什么:从数据到决策!
数据包括信号、图像、文字等非结构性 (unstructured) 数据
决策包括预测 (有监督学习)、检测 (无监督学习) 和行动 (深度学习)

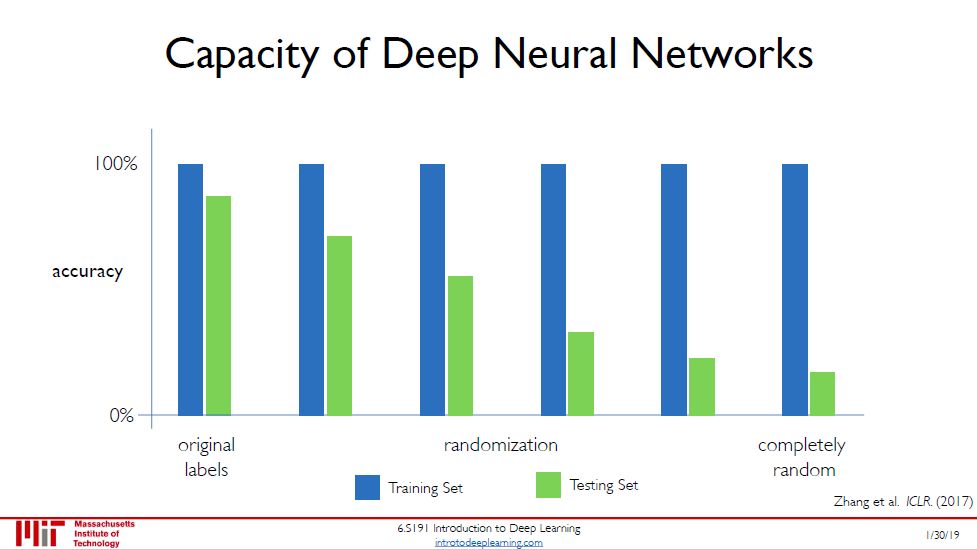
考虑图一的有趣实验,我们知道这四个图分别是狗、香蕉、狗和树,但是我们非要用丢骰子的方法重新定义类,比如 3 对应的是香蕉,5 对应的是狗,1 对应的是树。
这样完全将现实世界的物体类别打乱,但是放进神经网络训练,发现训练准确率还是 100%,但是测试准确率随着上述随机丢筛子的随机性的增强而降低 (见图二绿色逐渐变低的条形图)。神经网络的推广能力 (generalization) 越来越弱。

如果说差推广能力产生深度神经网络局限是正常的,那么这个对抗样本产生的局限性有点匪夷所思。
上图两边的小图用人眼看几乎分别不出差别,都是庙,但是在左图加了扰动以后,右图居然被神经网络分类为鸵鸟!


有人专门研究怎样生成对抗样本,图二提供了思路,而这思路是类比图一得来的。
图一:改变参数 θ (固定输入 x 和输出 y) 来减小误差
图二:改变输出 x (固定参数 θ 和输出 y) 来增大误差
增大误差不就是增大机器误分类率么?那么改变后的 x 不就是对抗样本了么?

列举一些神经网络的局限:
需要大量数据
需要大量算力
容易被对抗样本愚弄
容易受算法偏差影响
对不确定性的表示能力弱
难解释进而难信任
优化时需要注意大量细节
需要领域知识来设计或微调网络结构

前沿之一:贝叶斯神经网络
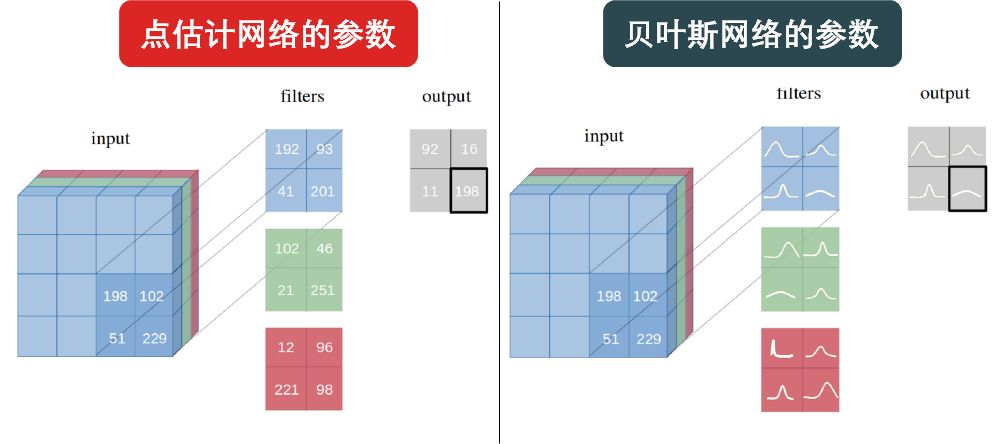
考虑一个二分类狗和猫的神经网络,它输出永远是概率 P(狗) 和 P(猫)。但当在测试数据集中遇到马的图像时,理想情况下应该预测它既不是狗也不是猫,即 P(狗) = P(猫) = 50%,但是,由于输出层的 softmax 函数会调整一个类输出概率分数并最大化一个类,从而导致一个类概率过大。 这是点估计 (point-estimate) 神经网络的主要问题之一,而这就是为什么需要贝叶斯 (Baysian) 神经网络,即为输出增添的不确定性 (uncertainty)。
一言以蔽之,点估计神经网络的参数是一个点,而贝叶斯神经网络的参数是一个分布,如下图所示。
前沿之二:自动学习
自动学习 (AutoML) 是机器学习的未来。它目标就是使用自动化的数据驱动方式来做出上述的决策。用户只要提供数据,自动机器学习系统自动的决定最佳的方案。领域专家不再需要苦恼于学习各种机器学习的算法。
自动学习大大降低的机器学习的门槛,也和强人工智能或通用人工智能 (Artificial General Intelligence) 沾了些边。
本来我自己学完就可以了,现在牺牲睡眠牺牲娱乐作总结,无非就是想让你们看后
觉得门槛降低
!
 !
!或
点个赞或转发
!
 !
!你会选哪个呢?
按二维码关注王的机器
迟早精通机学金工量投





