下个目标是攻克FIFA游戏?DeepMind让AI自学传球配合
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在攻克围棋、星际2这些游戏之后,DeepMind下一个目标可能就是足球了。
今天,这家英国的AI公司开源了机器人足球模拟环境MuJoCo Soccer,实现了对2v2足球赛的模拟。

虽然球员的样子比较简单(也是个球),但DeepMind让它们在强化学习中找到了团队精神。热爱足球游戏的网友仿佛嗅到了它前景:你们应该去找EA合作FIFA游戏!
让AI学会与队友配合
与AlphaGo类似,DeepMind也训练了许多“Player”。DeepMind从中选择10个双人足球团队,它们分别由不同训练计划制作而成的。
这10个团队每个都有250亿帧的学习经验,DeepMind收集了它们之间的100万场比赛。
让我们分别从俯瞰视角来看一下其中一场2V2的足球比赛吧:
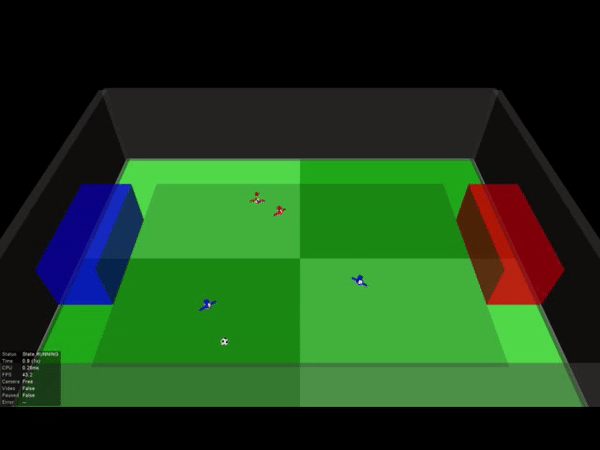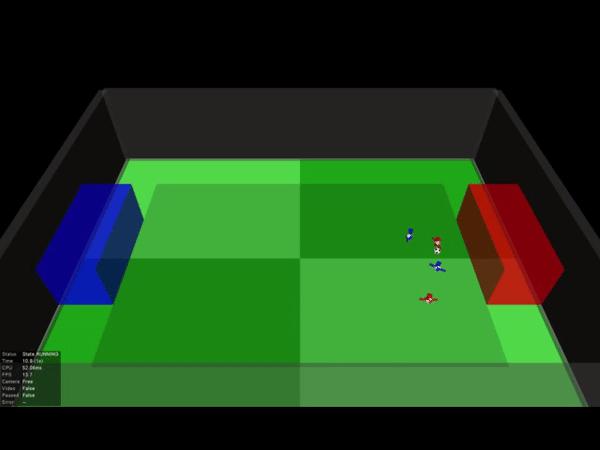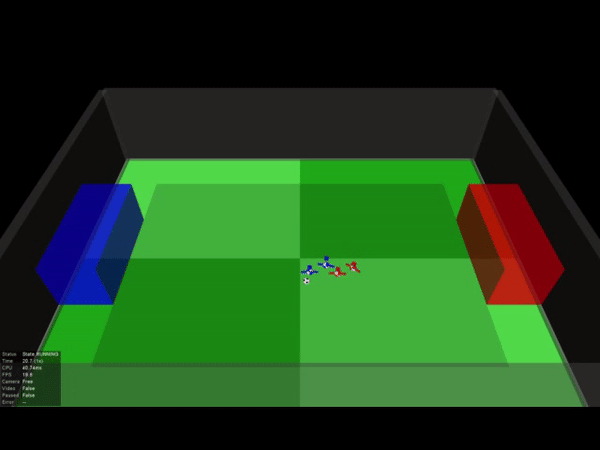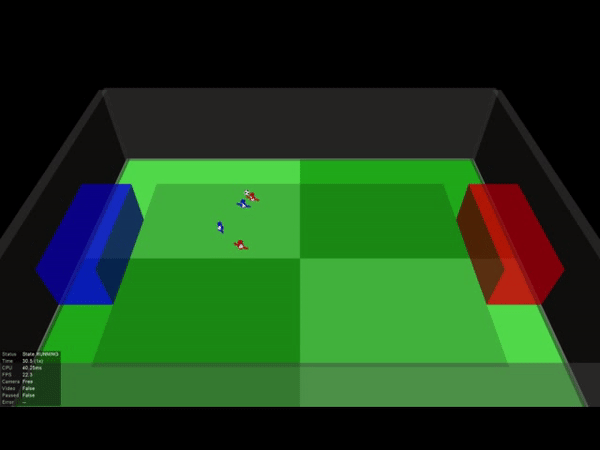
DeepMind发现,随着学习量的增加,“球员”逐渐从“独行侠”变成了有团队协作精神的个体。
一开始蓝色0号队员总是自己带球,无论队友的站位如何。在经历800亿画面的训练后,它已经学会积极寻找传球配合的机会,这种配合还会受到队友站位的影响。
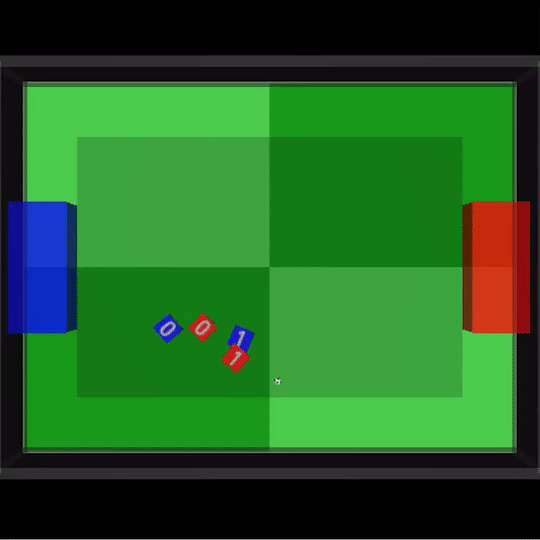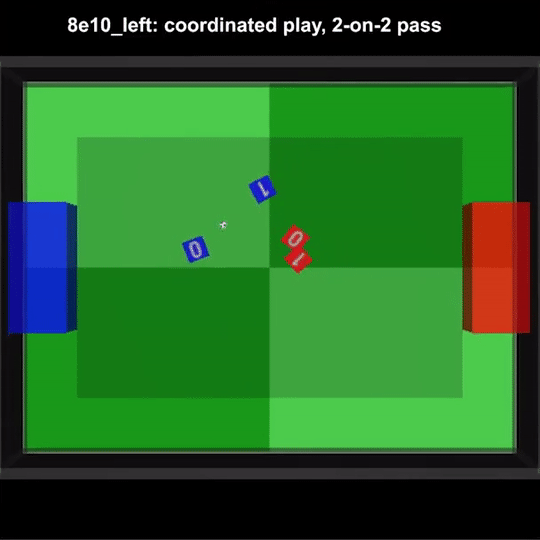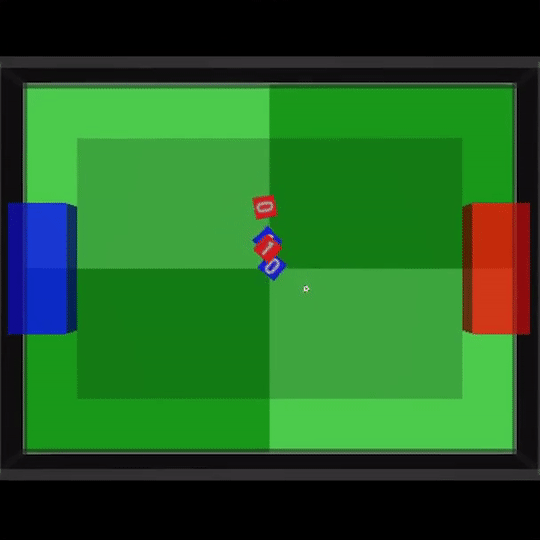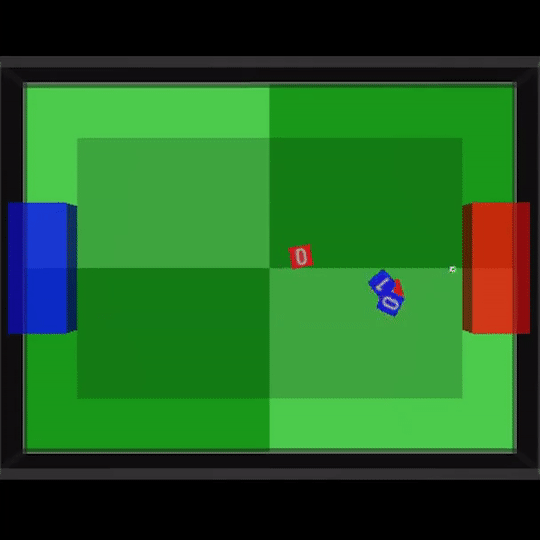
其中一场比赛中,我们甚至能看到到队友之间两次连续的传球,也就是在人类足球比赛中经常出现的2过1传球配合。
球队相生相克
除了个体技能外,DeepMind的实验结果还得到了足球世界中的战术相克。
实验中选出的10个智能体中,B是最强的,Elo评分为1084.27;其次是C,Elo评分为1068.85;A的评分1016.48在其中仅排第五。
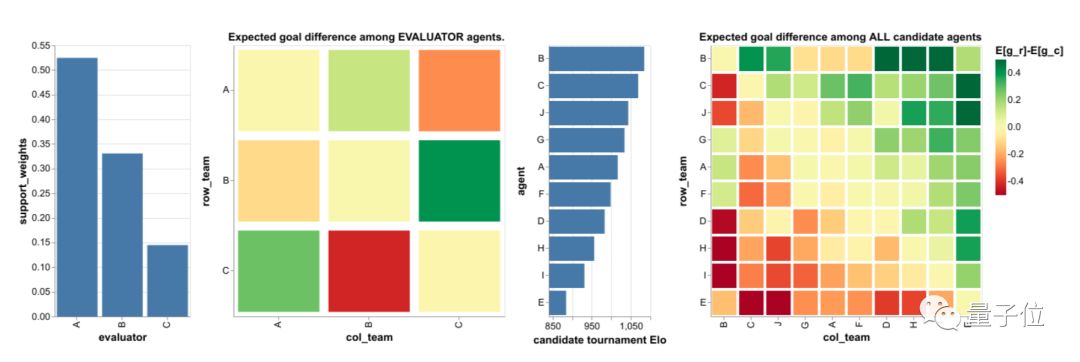
如果按照Elo评分的计算规则,我们会错误地认为B对A的胜率应该达到62%。实际上A能在59.7 %的比赛中打赢或打平B。

上图展示了智能体A、B和C之间比赛的录像,定性地展示了足球战术策略的多样性。
为何选择足球游戏
去年DeepMind开源了强化学习套件DeepMind Control Suite,让它模拟机器人、机械臂,实现对物理世界的操控。
而足球是一个很好的训练多智能体的强化学习环境,比如传球、拦截、进球都可以作为奖励机制。同时对足球世界的模拟也需要物理引擎的帮助。

DeepMind希望研究人员通过在这种多智能体环境中进行模拟物理实验, 在团队合作游戏领域内取得进一步进展。
于是他们很自然地把2v2足球比赛引入了DeepMind Control Suite,让智能体的行为从自发随机到简单的追球,最后学会与队友之间进行团队配合。
DIY试玩方法
现在你也可以自己去模拟这个足球游戏。首先安装MuJoCo Pro 2.00和dm_control,还需要在运行程序中导入soccer文件,然后就可以开始尝试了。
from dm_control.locomotion import soccer as dm_soccer
# Load the 2-vs-2 soccer environment with episodes of 10 seconds:
env = dm_soccer.load(team_size=2, time_limit=10.)
# Retrieves action_specs for all 4 players.
action_specs = env.action_spec()
# Step through the environment for one episode with random actions.
time_step = env.reset()
while not time_step.last():
actions = []
for action_spec in action_specs:
action = np.random.uniform(
action_spec.minimum, action_spec.maximum, size=action_spec.shape)
actions.append(action)
time_step = env.step(actions)
for i in range(len(action_specs)):
print(
"Player {}: reward = {}, discount = {}, observations = {}.".format(
i, time_step.reward[i], time_step.discount,
time_step.observation[i]))
在运行代码中,你还可以修改队伍人数和游戏时长,如果改成11v11、90分钟,就变成了一场FIFA模拟赛(滑稽)。
最后附上开源代码地址:
https://github.com/deepmind/dm_control/tree/master/dm_control/locomotion/soccer
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
加入社群
量子位现开放「AI+行业」社群,面向AI行业相关从业者,技术、产品等人员,根据所在行业可选择相应行业社群,在量子位公众号(QbitAI)对话界面回复关键词“行业群”,获取入群方式。行业群会有审核,敬请谅解。
此外,量子位AI社群正在招募,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式。
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !



