为什么一定要重视隐式反馈?
什么是隐式反馈?
推荐系统所需要的核心数据是用户的反馈。没有反馈的推荐系统属于一级残疾,归残联管,这里不负责。
因为没有反馈就:
没有持续优化的标注数据
没有评价效果的真实数据
总之一句话:没有反馈数据,没有数据循环,不通透,产品的新陈代谢就有问题。
注意,我们说的用户反馈可不是用户打电话给客服说的“意见反馈”,而是对Item的喜好。
反馈数据的形式有多种:点击查看,收藏,看(听)完,加入购物车,付钱,评分,给评价……
这些反馈形式分为两种:隐式反馈和显式反馈。
上面列举的反馈方式中,评分是显式反馈,因为用户知道自己在表达态度, 并且用一种较量化的方式给出很明确的态度。其他的反馈则是用户使用产品时所留下的自然行为, 用户留下这些数据,目的并不是要告诉他的喜好,但是我们却可以从中“揣摩”到用户的喜好,这就是隐式反馈。
隐式反馈相对于显式反馈有以下特点:
数量会比显式反馈大很多,矩阵更稠密,更稳定;
用户自然发生,通常会更加真实全面地反应其态度;
更接近产品指标,如人均播放时长(视频),点击率(新闻);
Xavier Amatriain(Quora工程副总裁)在ACM Resys2016 上也分享过要重视隐式反馈的观点。见推荐系统老司机的十条经验。
只有隐式反馈有没有问题?
看上去隐式反馈都很好,那么要把它用起来还要面对的问题是什么呢?容我细细说来。
回望历史,Netflix Prize百万美元推荐算法大赛催生了很多优秀的算法,尤其是以伪SVD为主的矩阵分解算法, 这些算法在预测评分上表现优异。然而在实际打造推荐系统时,发现有一点尴尬:产品中没有评分功能,从而没 有评分数据。这让人很无奈,这么多好锤子,却找不到钉子,一定是钉子的问题,曾经出现过一些乌龙事件, 某推荐算法比赛公布的比赛数据,将用户“喜欢”电影的操作都赋值成了4分,硬生生地构造成评分数据,简直是为了用上 现成的锤子,先用铁砂掌辟出钉子。
针对评分数据设计的矩阵分解算法,类似于监督学习中的回归问题,而隐式反馈数据通常是0-1二值数据,理想情况 下应当把它当做“预测用户是否会对Item产生某种隐式反馈”的分类问题,分类问题则需要负样本,显然通常隐式反馈 的负样本不那么明显。这是问题之一。
推荐的场景更多是推荐列表,关心的是排序,不论是“猜你喜欢”的综合列表推荐,还是Item-2-Item的相关推荐, 抑或是feed流推荐,关心排序胜过关心单个Item预测误差,因此用RMSE去评价隐式反馈推荐模型,就显得有 些差强人意,这是问题之二。
解决方案有哪些?
显式反馈如此匮乏,而SVD一类的矩阵分解算法又针对显式反馈而设计,是不是就只能去构造评分数据了呢? 并不是,人民的智慧是无穷的,隐式反馈的问题存在,就有各种解决方案冒出来。
针对隐式反馈的矩阵分解主流有以下两种做法:
Point Wise类:还是预测User对单个Item的偏好,最后根据偏好排序。
Pair Wise类:对同一个User,直接考虑任意两个Item的顺序谁在前谁在后。
Point Wise类,以Collaborative Filtering for Implicit Feedback Datasets这篇论文为代表[1], 对此,优秀的实现有:
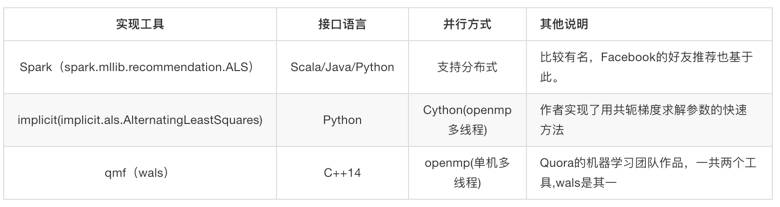
构造负样本的方法有三种:
随机采样矩阵的缺失值,即未被User消费的Item作为负样本;
从热门Item中采样未被User反馈的Item作为负样本;
用One-Class分类器建模(如scikit-learn OneClassSVM),识别出缺失值中的负样本(实际上被OneClassModel视为异常值)
Pair Wise类,以/BPR: Bayesian Personalized Ranking from Implicit Feedback/这篇论文为代表[2],对此,优秀的实现有:

第二类的思想是更加直接地求解最佳Item的顺序。在构造样本时有以下假设:
User反馈(无论显式隐式)Item,说明User已经消费过Item。相较未被反馈的Item,概率上更可能被User偏好。
该方法的训练样本不再是单个的Item,而是Item对,毕竟它是PairWise算法。
其中正样本就是这样的组对:
有反馈的Item在未反馈Item之前
负样本就是反过来组对:
无反馈的Item在有反馈的Item之前
有反馈的Item之间,无反馈的Item之间不参与构造样本。
这里有一个话题之外的问题,为什么Quora内部使用的是一个单机版?对此,Quora的工程副总裁Xavier Amatriain 曾表达过,不要轻言分布式,单机能搞定会计算得更快[3]。
实例demo
下面就以公开数据集来示范一下用这类隐式反馈数据如何进行推荐以及效果评价。
准备数据
我们以Last.fm开放的用户听歌记录来作为示范所用数据集[4]。这份数据集概述如下:
文件名:usersha1-artmbid-artname-plays.tsv
文件内容:
359,347个用户
107,373(无MBDID)和186,642(有MBDID)的歌手
17,559,530条收听关系及收听次数
构造矩阵
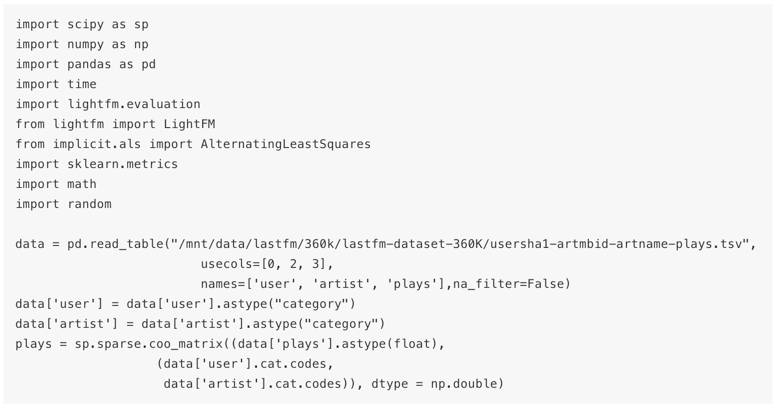
拆分训练集和测试集,注意是从每个用户收听历史中随机选择的:

训练模型
我们分别用PointWise方法和PairWise方法训练模型。
bpr模型(采用lightfm实现)

WALS模型(采用implicit实现)

效果评价
由于关心排序效果,所以用AUC作为我们的评价指标,和通常关心整体AUC不同,这里关心每一个用户的排序效果, 按照用户逐一计算AUC,最后看平均值和标准差。
lightFM自带AUC评价,而implicit的AUC评价需要自己实现。首先要专门为评价ALS模型构造负样本, 方法就是从热门Item中采样那些未被用户反馈过的Item,并且是加权采样,热门程度越高,采样的概率越高。
先用指数分布实现一个加权采样。
加权采样有很多实现方法,最简单合理的是利用指数分布来实现。加权采样 的用途也很多,比如:
1. 根据用户的tags 权重加权随机选择k个用于召回
2. 想让推荐结果每次输出不完全按照分数高低,而是有一定的变化。


再针对每一个测试用户产生测试样本来计算AUC。

把ALS的训练和评价放在一起:

用同一份数据运行两个模型,结果如下:
LightFM training cost 188.27 seconds User auc mean = 0.92, std = 0.10 (on testing dataset) ALS training cost 89.32 seconds User auc mean = 0.88, std = 0.22 (on testing dataset)
可以看到bpr模型在优化AUC上要略胜一筹。
推荐接口
好了,至此,我们对如何用隐式反馈做推荐有了一些认识,知道除了传统的Point Wise类的矩阵分解外,还有Pair Wise 直接优化AUC的方法。接下来一个自然的问题就从你我的头脑中冒了出来,模型训练好了,该如何使用呢?
这里简单编写一个推荐接口,输入UserID,列出他历史上听过的歌手,并输出推荐的歌手和分数列表,并且看看直观效果。




实现了两个简单的接口: recommend和similar_items。前者给用户进行个性化推荐,后者用于相关推荐。简单测试一下这两个接口:

给User 173031推荐:

用户收听历史输出如下:
[('周杰倫', 2122.0), ('陳奕迅', 1181.0), ('glenn gould', 673.0), ('楊丞琳', 536.0), ('wolfgang amadeus mozart', 492.0), ('aly & aj', 452.0), ('secondhand serenade', 425.0), ('avril lavigne', 424.0), ('s.h.e', 417.0), ('johann sebastian bach', 304.0), ('張敬軒', 291.0), ('kevin kern', 223.0), ('倉木麻衣', 223.0), ('張韶涵', 203.0), ('mitsuko uchida', 197.0), ('鄧麗欣', 194.0), ('x japan', 193.0), ('academy st. martins in the fields', 180.0), ('garnet crow', 160.0), ('michelle branch', 153.0), ('troy and gabriella', 150.0), ('jesse mccartney', 148.0), ('céline dion', 144.0), ('gil shaham and goran sollscher', 143.0), ('hide', 136.0), ('westlife', 136.0), ('孫燕姿', 128.0), ('jason mraz', 126.0), ('andy mckee', 123.0), ('oku hanako', 122.0), ('high school musical 2', 113.0), ('zard', 113.0), ('sara bareilles', 101.0), ('backstreet boys', 99.0), ('the corrs', 99.0), ('kelly sweet', 98.0), ('三枝夕夏 in db', 97.0), ('glay', 92.0), ('david garrett', 90.0), ('タイナカサチ', 87.0), ('james blunt', 84.0), ("the st. philips boy's choir", 84.0), ('david archuleta', 82.0), ('linkin park', 81.0), ('coldplay', 69.0), ("b'z", 68.0), ('nelly furtado', 65.0), ('sigiswald kuijken', 62.0)]
可以看到该用户收听兴趣广泛,港台,日本,欧美都有。
看看bpr模型给他推荐了哪些歌手:
{'item': [], 'items': [('josh groban', 2.541165828704834), ('michael w. smith', 2.5229959487915039), ('hillsong', 2.4939250946044922), ('宇多田ヒカル', 2.3995833396911621), ('hayley westenra', 2.369992733001709), ('angela aki', 2.3347458839416504), ('casting crowns', 2.3013358116149902), ('hillsong united', 2.2782249450683594), ('boa', 2.2732632160186768), ('steven curtis chapman', 2.2700684070587158), ('rebecca st. james', 2.2616958618164062), ('kokia', 2.2322888374328613), ('barlowgirl', 2.2148218154907227), ('do as infinity', 2.213282585144043), ('f.i.r.', 2.1844463348388672), ('corrinne may', 2.1044127941131592), ('chris tomlin', 2.0857734680175781), ('celtic woman', 2.0772864818572998), ('depapepe', 2.0735812187194824), ('ayaka', 2.0611968040466309)], 'user': []}
以欧美为主,有日本,也有台湾的f.i.r.
als 输出如下:
{'item': [], 'items': [('taylor swift', 1.186539712906344), ('frédéric chopin', 1.1863112931343351), ('colbie caillat', 1.0978262200222491), ('jonas brothers', 1.0811056577548976), ('bruno coulais', 1.0621494330528296), ('boa', 1.0488158944365353), ('bryan adams', 1.0277970165423405), ('daniel powter', 1.0220579888574337), ('yann tiersen', 1.0143708728515772), ('f.i.r.', 1.012305501265341), ('yiruma', 1.003527371248728), ('hilary duff', 0.99238201965409678), ('mandy moore', 0.97962069749414749), ('natasha bedingfield', 0.97652199359550906), ('simple plan', 0.95801904189552334), ('daughtry', 0.95771285384471316), ('bz', 0.93582329901255945), ('mariah carey', 0.93090378201808766), ('angela aki', 0.92184519678959209), ('claude debussy', 0.9190989429349703)], 'user': []}
也是以欧美为主,也有台湾的f.i.r.
再看看推荐相似歌手:

{'item': [('周杰倫', 1)], 'items': [('周杰倫', 0.99999999999999989), ('王力宏', 0.88290674032689487), ('陶喆', 0.85771472510708613), ('南拳媽媽', 0.85302933173781792), ('陳奕迅', 0.85081279073917004), ('林俊傑', 0.8493482632159628), ('孫燕姿', 0.83399343224087041), ('張惠妹', 0.82906432515041484), ('方大同', 0.82485675783986334), ('五月天', 0.82292313630632996)], 'user': []}
相似Item推荐看上去很简单,却是传统推荐系统最常见的一种应用。这里的相似Item计算,是用矩阵分解得到的factor 稠密向量计算而来,而非传统近邻模型那样的稀疏向量。用稠密向量计算近邻,也有一些神器, implicit内部用了另一个Python包,叫做annoy[5],开源自Spotify。除了annoy,类似的还有kgraph[6],nmslib[7]. 都是用来快速计算近邻的,可考虑在自己推荐系统中使用。
另外,lightFM还能用User和Item的属性数据做embedding,从而一定程度上实现冷启动策略,这个以后你我之间有缘的话再介绍。
后记
没什么好写的了,来一段freestyle吧:
yo, yo, check, check
关注隐式反馈
从此推荐不累
扔掉均方差,熊抱AUC
注意,这里是一个“单押 x3”。
本文全部代码见:
https://github.com/xingwudao/learning-to-rank-with-implicit-matrix
参考文献
[1] http://yifanhu.net/PUB/cf.pdf
[2] https://arxiv.org/abs/1205.2618
[3] https://www.slideshare.net/xamat/recsys-2016-tutorial-lessons-learned-from-building-reallife-recommender-systems
[4] https://www.upf.edu/web/mtg/lastfm360k
[5] https://github.com/spotify/annoy
[6] https://github.com/aaalgo/kgraph
[7] https://github.com/searchivarius/nmslib
本文作者:陈开江@刑无刀。具体介绍估计你们也不看,感兴趣的话见公众号以前的文章。
★ 读了本文的还读了:「推荐系统老司机的十条经验」

你们猜,我写了这么多还想干点啥?当然还想招人啊:
【后端开发工程师】:想转型AI工程师又苦于无人领路?没关系,我们给你实践机会,免票上车,一起成长学习。只要你编程基础好,聪明,上进,富有激情,不要求懂AI大数据这些劳什子概念,来就是一把梭,在干中学!(Java、Python方向均可)
简历请投:kaijiangchen@gmail.com




