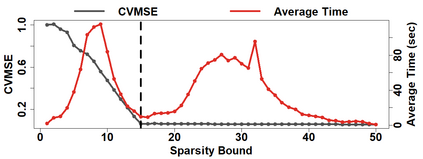
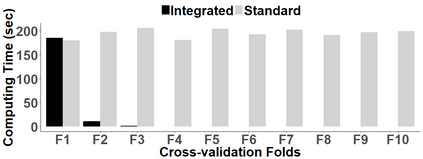
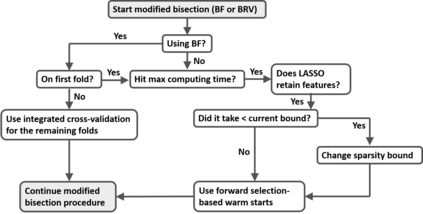
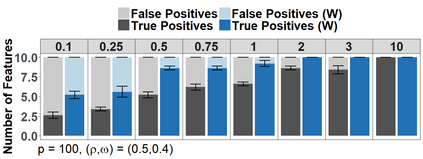
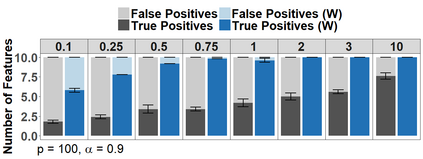
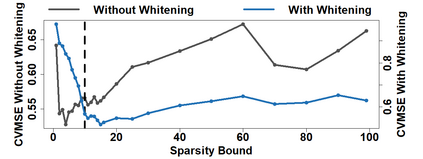
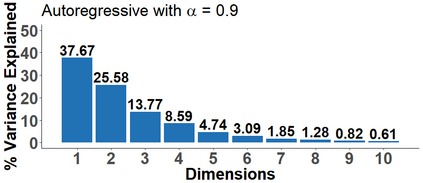
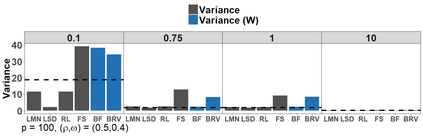
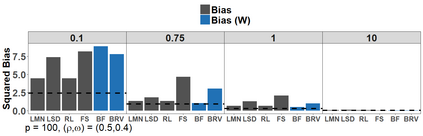
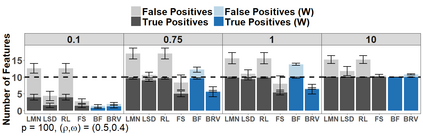
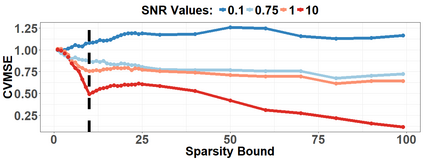
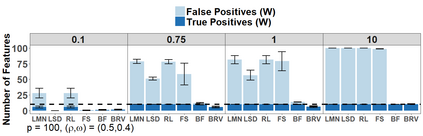
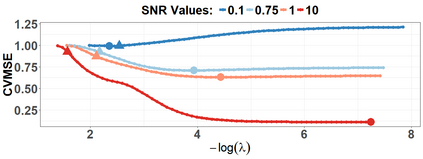
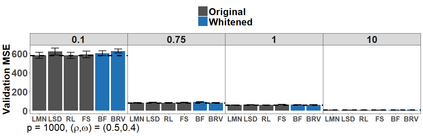
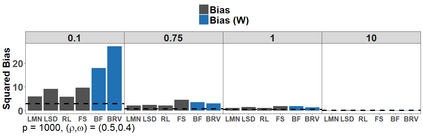
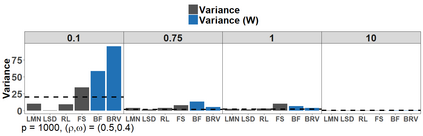
Because of continuous advances in mathematical programing, Mix Integer Optimization has become a competitive vis-a-vis popular regularization method for selecting features in regression problems. The approach exhibits unquestionable foundational appeal and versatility, but also poses important challenges. We tackle these challenges, reducing computational burden when tuning the sparsity bound (a parameter which is critical for effectiveness) and improving performance in the presence of feature collinearity and of signals that vary in nature and strength. Importantly, we render the approach efficient and effective in applications of realistic size and complexity - without resorting to relaxations or heuristics in the optimization, or abandoning rigorous cross-validation tuning. Computational viability and improved performance in subtler scenarios is achieved with a multi-pronged blueprint, leveraging characteristics of the Mixed Integer Programming framework and by means of whitening, a data pre-processing step.
翻译:由于在数学编程方面不断取得进展,Mix Integer优化已成为一种与民众在选择回归问题特征方面的正规化方法相比的竞争性方法。该方法显示出无可置疑的基本吸引力和多功能性,但也提出了重大挑战。我们应对这些挑战,在调整宽度约束(对有效性至关重要的一个参数)时减少计算负担,在特征相近和信号性质和强度不同的情况下提高绩效。重要的是,我们使这种方法在现实的大小和复杂性的应用中具有效率和效果――在优化时不诉诸放松或超常,也不放弃严格的交叉校准调整。在微妙的情景下,通过多管齐下的蓝图,利用混合整形规划框架的特点,并通过白化、数据处理前的步骤,实现可比较的可行性和改进性。