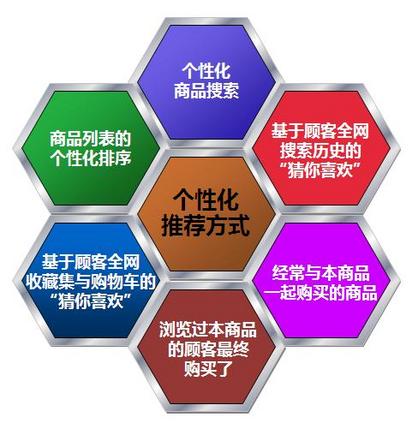
爱奇艺个性化推荐排序实践

作者介绍
Michael,推荐算法助理研究员,2014年硕士毕业于北京邮电大学后加入爱奇艺。从事推荐算法的研发和管理工作,对于机器学习和深度学习在推荐上的应用有着丰富的经验。
请输入标题 abcdefg
导 读
在当前这个移动互联网时代,除了专业内容的丰富,UGC内容更是爆发式发展,每个用户既是内容的消费者,也成为了内容的创造者。这些海量的内容在满足了我们需求的同时,也使我们寻找所需内容更加困难,在这种情况下个性化推荐应运而生。
个性化推荐是在大数据分析和人工智能技术的基础上,通过研究用户的兴趣偏好,进行个性化计算,从而给用户提供高质量的个性化内容,解决信息过载的问题,更好的满足用户的需求。

1
爱奇艺推荐系统介绍
我们的推荐系统主要分为两个阶段,召回阶段和排序阶段。
召回阶段根据用户的兴趣和历史行为,同千万级的视频库中挑选出一个小的候选集(几百到几千个视频)。这些候选都是用户感兴趣的内容,排序阶段在此基础上进行更精准的计算,能够给每一个视频进行精确打分,进而从成千上万的候选中选出用户最感兴趣的少量高质量内容(十几个视频)。
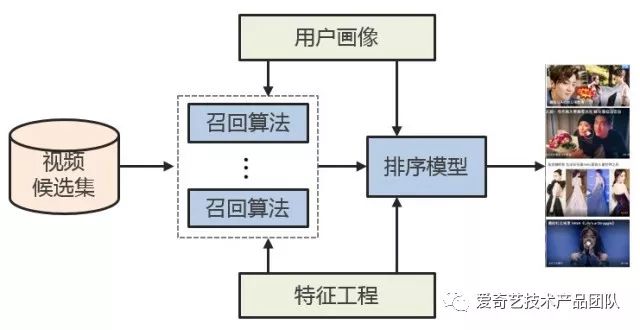
推荐系统的整体结构如图所示,各个模块的作用如下:
1
用户画像:包含用户的人群属性、历史行为、兴趣内容和偏好倾向等多维度的分析,是个性化的基石
2
特征工程:包含了了视频的类别属性,内容分析,人群偏好和统计特征等全方位的描绘和度量,是视频内容和质量分析的基础
3
召回算法:包含了多个通道的召回模型,比如协同过滤,主题模型,内容召回和SNS等通道,能够从视频库中选出多样性的偏好内容
4
排序模型:对多个召回通道的内容进行同一个打分排序,选出最优的少量结果。
除了这些之外推荐系统还兼顾了推荐结果的多样性,新鲜度,逼格和惊喜度等多个维度,更能够满足用户多样性的需求。
2
推荐排序系统架构
在召回阶段,多个通道的召回的内容是不具有可比性的,并且因为数据量太大也难以进行更加精确的偏好和质量评估,因此需要在排序阶段对召回结果进行统一的准确的打分排序。
用户对视频的满意度是有很多维度因子来决定的,这些因子在用户满意度中的重要性也各不相同,甚至各个因子之间还有多层依赖关系,人为制定复杂的规则既难以达到好的效果,又不具有可维护性,这就需要借助机器学习的方法,使用机器学习模型来综合多方面的因子进行排序。
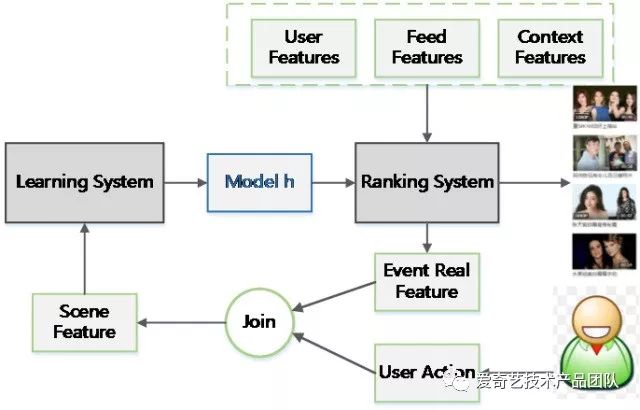
排序系统的架构如图所示,主要由用户行为收集,特征填充,训练样本筛选,模型训练,在线预测排序等多个模块组成。
机器学习的主体流程是比较通用的,设计架构并不需要复杂的理论,更多的是需要对细节,数据流和架构逻辑的仔细推敲。
这个架构设计吸取了以前的经验和教训,在通用机器学习的架构基础上解决了两个问题:
训练预测的一致性
机器学习模型在训练和预测之间的差异会对模型的准确性产生很大的影响,尤其是模型训练与在线服务时特征不一致,比如用户对推荐结果的反馈会实时影响到用户的偏好特征,在训练的时候用户特征的状态已经发生了变化,模型如果依据这个时候的用户特征就会产生非常大的误差。
我们的解决办法是,将在线服务时的特征保存下来,然后填充到收集的用户行为样本中,这样就保证了训练和预测特征的一致性。
持续迭代
互联网产品持续迭代上线是常态,在架构设计的时候,数据准备,模型训练和在线服务都必须能够对持续迭代有良好的支持。
我们的解决方案是,数据准备和模型训练各阶段解耦,并且策略配置化,这种架构使模型测试变得非常简单,可以快速并行多个迭代测试。
3
推荐机器学习排序算法演进
1
上古时期
我们第一次上线机器学习排序模型时,选用了比较简单的Logistic Regression,将重点放到架构设计上,尽量保证架构的正确性。除此之外,LR模型的解释性强,方便debug,并且通过特征权重可以解释推荐的内容,找到模型的不足之处。
在模型训练之前,我们首先解决的是评测指标和优化目标的问题。
评测指标(metrics)
线上效果的评测指标需要与长远目标相匹配,比如使用用户的投入程度和活跃度等。在我们的实验中,业界流行的CTR并不是一个好的评测指标,它会更偏向于较短的视频,标题党和低俗内容。
离线评测指标是按照业务来定制的,以便与在线评测指标匹配,这样在离线阶段就能够淘汰掉无效策略,避免浪费线上流量。
优化目标(objective)
机器学习会按照优化目标求解最优解,如果优化目标有偏差,得到的模型也存在偏差,并且在迭代中模型会不断地向这个偏差的方向学习,偏差会更加严重。
我们的方法是给样本添加权重,并且将样本权重加到loss function中,使得优化目标与评测指标尽可能的一致,达到控制模型的目的。
LR是个线性分类模型,要求输入是线性独立特征。我们使用的稠密的特征(维度在几十到几百之间)往往都是非线性的,并且具有依赖性,因此需要对特征进行转换。
特征转换需要对特征的分布,特征与label的关系进行分析,然后采用合适的转换方法。我们用到的有以下几种:Polynomial Transformation,Logarithmic or Exponential Transformation,Interaction Transformation和Cumulative Distribution Function等。
虽然LR模型简单,解释性强,不过在特征逐渐增多的情况下,劣势也是显而易见的。
1
特征都需要人工进行转换为线性特征,十分消耗人力,并且质量不能保证
2
特征两两作Interaction 的情况下,模型预测复杂度是。在100维稠密特征的情况下,就会有组合出10000维的特征,复杂度高,增加特征困难
3
三个以上的特征进行Interaction 几乎是不可行的
2
中古时期
为了解决LR存在的上述问题,我们把模型升级为Facebook的GBDT+LR模型,模型结构如图所示。
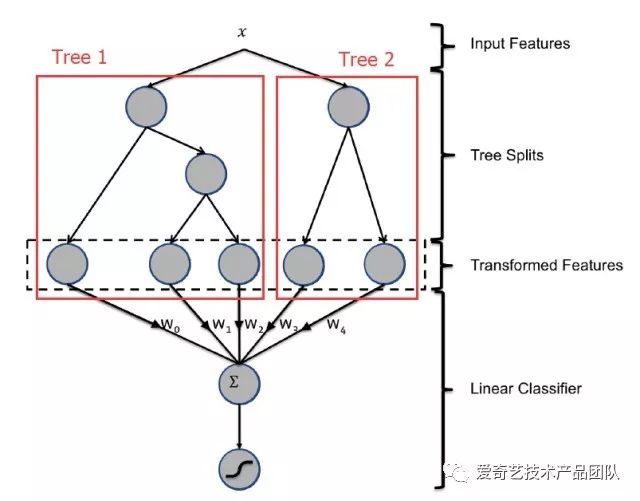
GBDT是基于Boosting 思想的ensemble模型,由多颗决策树组成,具有以下优点:
1
对输入特征的分布没有要求
2
根据熵增益自动进行特征转换、特征组合、特征选择和离散化,得到高维的组合特征,省去了人工转换的过程,并且支持了多个特征的Interaction
3
预测复杂度与特征个数无关
假设特征个数n=160决策数个数k=50,树的深度d=6,两代模型的预测复杂度对比如下,升级之后模型复杂度降低到原来的2.72%
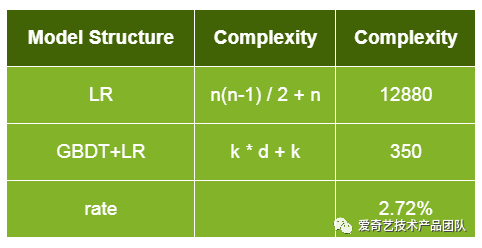
GBDT与LR的stacking模型相对于只用GBDT会有略微的提升,更大的好处是防止GBDT过拟合。升级为GBDT+LR后,线上效果提升了约5%,并且因为省去了对新特征进行人工转换的步骤,增加特征的迭代测试也更容易了。
转自:爱奇艺技术产品团队
完整内容请点击“阅读原文”