
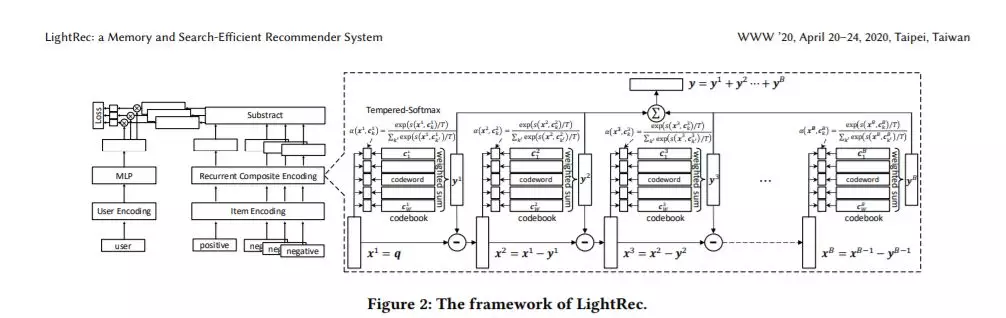
深度推荐系统近年来取得了显著的进步。尽管其具有较高的排名精度,但其运行效率和内存消耗在现实中成为严重的瓶颈。为了克服这两个限制,我们提出了LightRec,这是一个轻量级的推荐系统,具有快速的在线推理和经济的内存消耗。LightRec的主干是B码本,每个B码本由W个潜在向量组成,称为码字。在这种结构的顶部,LightRec将有一个项目表示为B码字的附加组合,这些B码字是从每个码本中最佳选择的。为了从数据中有效地学习代码本,我们设计了一个端到端学习工作流,其中所提出的技术克服了固有的可微性和多样性方面的挑战。此外,为了进一步提高表示质量,我们使用了一些蒸馏策略,这些策略可以更好地保存用户-项目的相关性分数和相对的排序顺序。LightRec通过四个真实世界的数据集进行了广泛的评估,这产生了两个经验发现:1)与最先进的轻量级基线相比,LightRec在召回性能方面取得了超过11%的相对改进;2)与传统推荐算法相比,在top-k推荐算法中,LightRec的精度下降幅度可以忽略不计,但速度提高了27倍以上。
成为VIP会员查看完整内容
相关内容
专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
15+阅读 · 2020年3月7日
Arxiv
9+阅读 · 2019年5月27日


相关VIP内容
专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
15+阅读 · 2020年3月7日
相关资讯
相关论文
Arxiv
9+阅读 · 2019年5月27日